As noted by Pat Frank, Demetris Koutsoyiannis’ new paper has been published, evaluating 18 years of climate model predictions of temperature and precipitation at 8 locales distributed worldwide. Demetris notified me of this today as well.
The paper is open access and can be downloaded here: http://www.tandfonline.com/doi/pdf/10.1623/hysj.53.4.671
Here’s the citation: D. KOUTSOYIANNIS, A. EFSTRATIADIS, N. MAMASSIS & A. CHRISTOFIDES “On the credibility of climate predictions” Hydrological Sciences–Journal–des Sciences Hydrologiques, 53 (2008).
Abstract “Geographically distributed predictions of future climate, obtained through climate models, are widely used in hydrology and many other disciplines, typically without assessing their reliability. Here we compare the output of various models to temperature and precipitation observations from eight stations with long (over 100 years) records from around the globe. The results show that models perform poorly, even at a climatic (30-year) scale. Thus local model projections cannot be credible, whereas a common argument that models can perform better at larger spatial scales is unsupported.”
Pat Frank observes: “In essence, they found that climate models have no predictive value.”





540 Comments
Please discuss this article and do not make generalized complaining about climate models. Observations should be related to the paper.
Umm, pretty darn good. Scanning for faults … haven’t found any problems yet.
Disconcertingly poor performance on the Hurst coefficient. As expected. Supports the hunch that there are long-term persistent processes (ocean upwelling? cloudiness?) that are not accounted for in the GCMs. Exactly the kind of thing that could lead to a decade’s worth of flat GMT.
Doh!
Fisnished. Conclusion: I like this paper and agree with its conclusions. I wish it had been published years ago.
The only question remaining: how will RC cope? Ad hominem? Poison the well? Denial? Dismiss based on minor technicalities? Tough to guess, when they have resorted to each of those so many times in the past.
Nice paper, Dr. Koutsoyiannis.
Judith? JEG? Your reviews?
is it peer reviewed?
i assume so, but since it wasn’t specifically said, i thought i would check!
Click to access PublishingInHSJ.pdf
Gavin Schmidt is acknowledged as a reviewer. How I would love to see that one!
You have seen his comments at RC. You didn’t read the acknowledgements carefully enough:
The predecessor paper was discussed at RC which would be the “sometimes negative” comments. I was not a peer reviewer for the journal and am thanked on the basis of blog discussions.
I find this statement curious given Lucia’s recent analyses and her most recent post on the Echo-G projections:
“GCMs underestimate the observed variability”
http://rankexploits.com/musings/2008/planet-echog-thats-some-weather-noise/
Perhaps this a difference between global and local metrics?
last comments for tonight:
(1) bound to spark many more such studies
(2) may or may not become a “classic” like MBH98 but will be cited many times, even though this journal has a low impact factor
(3) required reading for any scientist who uses GCM outputs (raw or downscaled) as inputs in their climate change impact studies
(4) anyone researching climate change impacts who does not read this paper and take a stand should be held to account for their negligence
#10 no, i read carefully; i read that and understood precisely what it meant. i presume i was not online during that period.
i.e. A single GCM run underestimates the GC process’s full potential range of variability.
The GC a stochastic, non-stationary, non-ergodic process. It has far more intrinsic variability than what you may observe in a single real-world realization. Far more than what you are bound to observe in a single GCM run.
#14 (Bender)
“It has far more intrinsic variability than what you may observe in a single real-world realization”
Does that mean you disagree with Lucia’s use of the historical variability in real world weather to estimate the uncertainty intervals for the IPCC projections?
The only weakness that I can see that will be latched onto by the RC crowd is the fact that Koutsoyiannis appears to be some sort of Associate Editor at this journal. They will spin that into a presumed lack of impartiality in the review process. Of course, it’s far easier to do that than to address the substance of the results and conclusions.
Steve: I doubt that this is something that they will pursue as it’s pretty easy to find similar issues in some RC pubs.
#14 – I don’t want to derail this discussion with something off – I only want to better understand the implications of your comments on this paper.
Dunno. Can’t judge her argument without seeing it in full. Gimme a url. (I do see some potential issues there. Nothing she will not have thought of already, I’m sure.)
I think Bender just went nova.
#18 – Here is a recent post that makes the argument that GCMs overestimate weather variability.
http://rankexploits.com/musings/2008/hypothesis-test-for-2ccentury-now-with-monte-carlo
#17 Yes, best to discuss lucia’s argument where it can be found.
The “implications of my comments” are simple. I agree with Koutsoyiannis. My review is 100% completely independent, impartial. (In fact I’m on record as a fence-setting lukewarmer.) I think – and I am on record saying this at lucia’s blog – there is a chance that the current GMT flatline is as misleading as the 1990s uptick. That both may be the result of LTP processes that have yet to be correctly identified and parameterized. Perfectly consistent with this paper’s conclusion. (I’m also on record saying I’m neither a climatologist nor a statistician.)
“Coolers” (aka “deniers”) who try to overinterpret the 2000s flatline are taking the opposite risk that the “warmers” are in over-interpreting the 1990s uptick. If the trend is somewhere in the middle, and if you further correctly remove the warm biases and uncertainty pointed to by Pielke this a.m. – then you are probably left with a weak upward trend. Maybe that’s what we need to take “precaution” against. Not the over-dramatized scare scenarios.
Off-topic. Trying hard to stay on-topic. Best we all do that.
#20: See her caveat #1. This squarely addresses my concern here. The “bell-shaped curve” may be wider than what she supposes. And she fully recognizes that.
[Delete if OT.]
kaboom
$20 says Wunsch is far from offended by this paper.
This makes the deletion of the LTP paragraph from the IPCC final draft all the more pertinent.
I saw Chris Essex do a talk on a related problem 2 years ago. Modelers struggled with climatic drift for a long time — the propensity for models to wander off into absurd states over long runs. Modelers had to tune and constrain and tweak out sources of low-freq variability to deal with this. But that’s where the climate processes operate. So fidelity to climate was lost as part of the solution to drift. I wonder if earlier GCMs would do better at matching Hurst behaviour, at the cost of higher propensity to drift.
OUCH!!!
#25 (P…r Texas) – [Steve – this is a forbidden word for obvious reasons as any wavering will cause the site to be overwhelmed with spam]
It means that we don’t have any idea what will happen in the future if we keep adding CO2 to the atmosphere and we cannot exclude the possibility that the models are basically right even with their flaws. That said, the smart money would bet on warming over the next century at the same rate that we have seen since 1950 (i.e. 0.7-1.0 degC/century).
It will also be impossible for policy makers to completely ignore the potential problem of CO2 but the uncertainity will require that they be more prudent in their policy choices.
The bad thing was, he didn’t mention how additional funding is necessary to shore up uncertainties in the study (that’s in every other climate study that I can remember.)
The good thing was that no one has to go tell a guy on a camel that the Sahara is really a jungle because that’s what the GCM concludes.
Now go read IPCC 2007 Working Group 1, chapter 8.4 and tell me if everything in the conclusion of this paper isn’t already backed up by the worlds leading climate scientists.
The only question remaining: how will RC cope? Ad hominem? Poison the well? Denial? Dismiss based on minor technicalities? Tough to guess, when they have resorted to each of those so many times in the past.
I predict they use the TTID Defense. This Time it’s Different. i.e. the modelers of 20 or 30 years ago did not have the skill [cringe] and sophistication of modelers today.
PTT says:
July 29th, 2008 at 11:14 pm 25
1) Does this mean that other such models used to predict such things as the local weather tomorrow are similarly flawed and inaccurate?
No. It means that the GCM that have been used successfully by meteorologists to predict the weather for next day,and even with a fair rate of success for the next ten days, cannot be extrapolated and played in a stochastic game into decades, let alone centuries.
The mathematics as far as I am concerned is simple. The whole climate system is a complicated coupled differential equations system, where it is impossible to find solutions analytically. One is using approximations, and usually these are first(the mean) or at most second order term approximations from a putative expansion in the variables into a series that hopefully converges. Nobody knows if it converges ( chaos results), but if the stepping function in time is for a reasonable number of steps, the instabilities of the true solution do not have “time” ( i.e.number of time steps) to appear, so the tuned GCM for the week’s weather are OK. When the stepping continues into years and decades, the instabilities are inevitable.
A very important find! I seriously hope (and doubt) that this reaches the mainstream media.
Steve#1 I appreciate your comment but wonder if you will permit me to put the report into a broader context that illustrates how timely, interesting, and pertinent it is. I particlarly agree with Benders’ #3 analysis and suspect there are many other processes of which we are unaware at present. Our knowledge of climate is much less than we like to pretend.
The observations contained in the paper highlights two fundamental flaws in climate science.
The first is lack of historical reference by researchers. History is not well taught these days and working with computers that can be instantly adjusted to provide a new scenario is more exciting (to some)than ploughing through extensive written documents about our past climate that often need cross referencing in order to put them into context.
Couple that with the inherent problems with computer models that the IPCC themselves acknowledge- but seem to be brushed aside- and the science is built on shakier foundations than many admit. Some quotes on the efficacy of models are shown by the following refernces;
The IPCC 2001 report;
“In climate research and modelling we should recognise that we are dealing with a coupled non linear chaotic system and therefore that the long term predictions of future climate states is not possible.”
If that is not explicit enough, in 2007 they said;
“At each step (of the CO2 calculations) uncertainty in the time signals of climate change is introduced by errors in the representation of earth’s system processes in modelling.”
Kevin Trenberth, lead author wrote,
“…the startling climate state in several models may depart significantly from the real climate owing to model errors.”
The latest 2007 SPM, continues to state
“…cloud feedbacks remain the largest source of uncertainty…”
You should not build a multi billion industry on shaky foundations and I aplogise if this post has strayed too far from the scientific analysis you wanted.
TonyB
I like it that Koutsoyiannis used a procedure that maximizes CE to calculate the estimated point temperature from the GCM gridcells. Then they used the CE to measure how well the prediction matched the reality.
That means that no one can claim that a different means of calculating the point temperature from the GCM field would give a better CE …
I also liked that they looked at the average and standard deviation of the models vs reality, a technique I used here.
w.
Demetris Koutsoyiannis has presaged some of the likely criticisms, such as choice of only a few sites. As an Australian, I could raise some points about Alice Springs (for example, in the dry centre of one of the driest continents, rainfall influenced by several possible passing weather systems more than an identifiable annual pattern, etc). I offer to help with more site selections, if asked, for the planned longer paper.
Models have to accommodate variable sites like this, however, and the authors have shown the inability of models to do so, even by simple analysis. Indeed, it is a theme of the paper that sites are more variable than models commonly predict.
The conclusion-
seems to leave little room for an influence by GHG in the data chosen.
I should think it would be highly informative to examine the design documents and the user manuals for each of these GCM’s and to construct a side-by-side comparison of each of the major facets of their internal designs.
When I use the word “internal design” I mean something much more than just the model’s code listings and a description of the model’s code structure in terms of language constructs, sub-program calls, etc.
First, I would like to see a written overview “primer document” as to which climatic processes are included in that GCM, an inventory of the underlying physics that are being modeled, how the climate drivers are assumed to interact with each other, and how instabilities in the model’s step-by-step progression are handled and dispositioned. This primer document might be considered as being the model’s Conceptual Design Document.
Next, I want something that could be considered as the GCM’s Detailed Design Document. This document takes the inventory of assumed climatic processes, climatic related physics, and their assumed mutual relationships/interactions and maps them into the actual code modules that comprise the GCM’s code base.
The Detailed Design Document also contains a Data Dictionary for the model which describes in detail its input and output data sets, and any internal data sets it creates as a part of its modeling processes. Each data set element is mapped back to the inventory of climatic processes and/or physics which utilize that particular data element. No data element within the model is excluded for any reason, other than the usual index counters, etc.
Last, I would like to see a listing of the code base for each GCM organized and indexed according to the material contained in the Detailed Design Document. I would also like to see a cross index of the internal, input, and output data elements with every code line and code module which they appear in.
In my sometime career as a software designer and programmer in the nuclear industry, I have produced similar types of documentation for software systems that had nuclear safety implications; i.e., the end-to-end validity and quality of the driving design requirements, the internal designs, and the fidelity of the coded software to its design requirements was of critical importance.
As has been observed by others at CA, having these well-written and readable design documents in our hands for each of these models might become a foundation for creating the “2xCO2 yields 2.5 C warming” engineering analysis that Steve M is asking for.
Geoff, you raise a good point:
I would add that predicting the temperature in the middle of the big dry seems like it couldn’t be too hard, comparatively. There would be less interference from that notorious shape-shifter, water vapor. Also, there’s no ocean influence, and only a few of those nasty clouds that mess up a perfectly good climate model. Seems like it could make a good test case for just CO2.
w.
I don’t believe it’s new that GCMs aren’t reliable, I came across this earlier this year:
“… the credibility of these computer model predictions took a significant hit in June 2007 when Dr. Jim Renwick, a top UN IPCC scientist, admitted that climate models do not account for half the variability in nature and thus are not reliable. “Half of the variability in the climate system is not predictable, so we don’t expect to do terrifically well,” Renwick conceded.
Another high-profile UN IPCC lead author, Dr. Kevin Trenberth, recently echoed Renwick’s sentiments about climate models by referring to them as “story lines.”
“In fact there are no predictions by IPCC at all. And there never have been. The IPCC instead proffers ‘what if’ projections of future climate that correspond to certain emissions scenarios,” Trenberth wrote in journal Nature’s blog on June 4, 2007. He also admitted that the climate models have major shortcomings because “they do not consider many things like the recovery of the ozone layer, for instance, or observed trends in forcing agents. There is no estimate, even probabilistically, as to the likelihood of any emissions scenario and no best guess.”
I think they’re both Aussies, so as well as being honest it goes without saying they’ll be brilliant at cricket and rugger.
Thanks indeed, Steve, for this post; Pat for the earlier note; and everybody for the comments and for trying to find possible caveats on the paper or its peer review process. I would like to give some information on the latter issue.
1. I did not hope that this paper would be accepted in broad scope, high impact factor, journals such as Science or Nature. I did an experiment recently with a paper on Hurst and entropy:
It was rejected outright (in chronological order) by Nature, Science, Nature Geoscience, Nature Physics.
2. Even less broad scope journals with lower (but still high) impact factor, such as Geophysical Research Letters, have offered me similar experiences. The following paper:
was rejected twice (by the Editor James Famiglietti based on a repeatedly strongly negative reviewer) in Geophysical Research Letters.
3. Having gathered a lot of experience from rejected papers of mine (I am an expert in rejections …), and having studied the impact of papers with respect to the journal in which they were published, I would advice the younger colleagues not to strive too much to publish their papers, particularly the good ones, in the journals with the highest impact factors. The good papers are very likely to be recognized and cited wherever they are published, provided that the journal is good quality and visible. The following excerpt from a recent study justifies this advice:
4. With the above observations, and given that we, the authors, are hydrologists, it was natural to us to publish this paper in a hydrological journal. And it is not true that Hydrological Sciences Journal (HSJ) has a low impact factor (IF). On the contrary, it is one of the top 10 journals, in terms of IF, in the category Water Resources (it is well known that the IF of a journal should be considered relatively to its peers, i.e. of the same category). It is true that I am the Deputy Editor of this journal but it happens also to belong to the editorial board of three other hydrological journals from the top ten (in terms of IF), which also happen to be the ones with scopes most closely related to the theme of the paper and those where I have published my previous research. So, this was not the criterion of the choice of journal to send our paper. Besides, in good journals being a member of the Editorial Board does not facilitate publication of your paper.
5. Among hydrological journals, HSJ was our first choice (and fortunately, it was not necessary to turn to the second, third, etc. choice; incidentally, we had an invitation from the Editor another top journal for this paper) for the following reasons.
5a. HSJ has already published numerous papers on climate and hydrology, not only “orthodox” ones but also with different views. For instance, my first paper on climate:
was published in HSJ journal, after it was rejected by another journal (I have narrated this story in another Climate Audit post, http://www.climateaudit.org/?p=483) In addition, HSJ has published a few special issues on themes related to climate, such as on historical hydrology and trend detection. Moreover, it is the journal where the authors of the IPCC AR4 chapter on freshwater have published their “official” summary:
5b. HSJ has the Open Access (OA) option (if the author agrees to pay the relevant fee) and this was important for us. We think that in the Internet era, OA is more important for dissemination of ideas than a stamp by Nature etc. (here Aesop’s fable on the fox who found the grapes sour may apply…)
5c. HSJ has recently established the option of Rapid Communications, which we judged very relevant for this paper — and indeed we submitted it to be considered as a Rapid Communication.
5d. HSJ strongly encourages formal discussions of papers, making all discussion papers OA without any payment by the author. This we also regarded as very important. By the way, the deadline for submission of discussions for Koutsoyiannis et al. (2008) is 1 February 2009, while that for Kundzewicz et al. (2008) mentioned above is 1 August 2008 (there are a few days left for discussion papers, if anyone is interested; I am working on one right now).
6. An noted by bender (in #8), all papers in HSJ are peer reviewed, typically by two reviewers; both anonymous and eponymous reviews are accepted. In the case of our paper we have been honoured and flattered to receive two reviews (both recommending publication) by a leading hydrologist, Zbyszek Kundzewicz, and a leading climatologist, Roger A. Pielke Sr. Kundzewicz is also the Editor of HSJ, as well as the lead author of IPCC AR4 for the chapter “Freshwater resources and their management” (as well as its “formal” summary mentioned above). He is a real scientist, respecting views different from his, and a great Editor, not censoring papers that contrast mainstream views.
7. As noted by Steve (in #10) who highlighted our acknowledgments, we also received two informal reviews (informal meaning that the paper was sent to the reviewers by us and not the Editor) and an additional comment. These, as well as the comments we indirectly received through discussions on blogs are additional to the formal peer reviews. We acknowledge them because they too helped us to improve the paper (including the negative comments by Gavin Schmidt in RC).
A point that people are not making in all the hectoring about models is that it is possible to be concerned over CO2 impact even if you are not sold on GCMs. I don’t understand why you need to be able to model every thing in the world to neverending complexity to understand the impact of CO2. It seems to me that the climate modeling community has, in a sense, used the valid concern over CO2 to increase the profile of GCM modeling.
But folks, keep firmly in mind – that even if the GCMs are no good, there are other lines of reasoning to be concerned about doubled CO2, which do not stand or fall on NAvier-Stokes divergence and stuff like that. This is a main reason why I think that it is important for people in the field to write out a careful “engineering quality” exposition of how doubled CO2 leads to 3 deg C in which all the key parameterizations and feedbacks are written down and described.
I rather hope they do. Given the well-documented incestuousness of the Paleo-Climate crowd, that would be another treat for the irony connoisseurs here at CA.
Steve’s personal Holy Grail – good luck with that!
I guess I would be more interested in assessing the model’s predictions/simulations versus the global average climatic conditions or on significant regional scales like continents, tropics, northern hemisphere, tropopause etc.
I didn’t expect the models to be very accurate for specific locations although they should certainly be reasonably close if we are also to have faith in the global or regional predictions. This paper shows the models are not accurate enough for specific locations to be relied on for their global and regional predictions in my opinion.
Re 21. as a fellow lukewarmer I could not have said it better myself.
Steve McIntyre says:
July 30th, 2008 at 5:20 am
OK with this.
Other lines of reasoning except the GCM with feed backs give concern for CO2? Do you have a link? Reasoning is not enough, of course. One needs numbers, i.e. calculations. The ones I am aware of give a minuscule role to anthropogenic CO2. It is the feed backs that amplify the small effects.
With you on this, but I doubt there is anything else to be studied than these fiddled GCModels.
Steve: I think that there’s lots that could be written and done.
Steve Mc:
On what grounds?
#24
Is that documented somewhere here? This IS an important point. Do we know who requested and authorized the deletion?
#28 Right. Also called: “we’ve moved on”.
#37 Good point about IF needing to be judged within field. A point well-known by trackers of IF – a group to which I do not belong.
#38 The issue here is not broadly whether or not the GCMs are credible on GHG scenario simulation. It’s much more precise than that. It’s to what extent their inability to simulate observations is a function of an incorrect specification of the internal background variability. Does the consensus mistake noise for signal in the 1990s and signal for noise in the 2000s, such that the GHG-related trend, while significantly non-zero, is nevertheless overestimated. Not warm. Lukewarm.
Steve is suggesting that because of this perhaps GCMs are the wrong type of model. Maybe EBMs are better. Myself, I have a hard time imagining the proper kind of background variability coming out of anything but a GCM. 3D space is required for heat to hide in remote places, for ocean clouds to do their thing.
Steve: That’s not really what I’m trying to say. All I’m trying to say is that it looks like whatever is driving the trends in a GCM can be modeled in a less complex subspace. We know this in a way because the model GLB trends can be approximated closely by very simple systems. Can this subspace be analysed? I suspect that it can. I’m not saying that it can, only that it would be worth trying.
There is a major industry that involves taking GCM output and using that to evaluate local impacts on crops, endangered species, and ecosystems, and often what gives the biggest impact is changes in the extremes, but even the mean climate at a local scale has not been demonstrated to be accurately simulated. The failure with respect to precipitation is particularly disturbing because this has a huge impact on vegetation. In order to get an “impact” all the GCM has to do is be wrong about local future weather, not even alarming, because the local animals and plants are not adapted to the wrong weather and will show an impact.
Steve: Craig, have you seen the CCSP report hot off the press? I’ll do a post linking to it.
Par Frank observes: “In essence, they found that climate models have no predictive value.”
We have known this since Edward Lorenz work in the early 1960’s. I have watched in astonishment for the last 20 years as large numbers of very smart people pretended GCM’s have predictive value.
Good point. I don’t need to model a missile down to its atomic behavior to create a 6DOF model that is extremely accurate in predicting the missile’s flight path.
Surely the GCM are supposed to predict temperature taking into account their understanding of the effects of CO2, which has been touted as the dominant element in climate change. The fact is that none of the models can accurately predict anything. For all we know, the temperature effect of CO2 might be negative (it certainly appears to have been for the past 8 years). The current theory (if it may be termed such) of CO2 induced warming is old and sketchy, there is no experimental evidence, there is no modeled evidence, and the Geological evidence, and current temperature record (unreliable as it is) evidence is against. Apparently, no-one can write out the theory in Mathematical terms, and certainly not in the depth which SteveM has been asking.
Now with regard to the models, compare and contrast with the IPCC TAR
IPCC TAR
The whole thing is wrong,wrong,wrong. No wonder Gerald Browning goes ballistic.
From the same report:
??????
Raven–
Echo G is getting lots of “weather noise” in GMST.
But
1) Echo G is just Echo G. The other model I looked at (The canadian one) didn’t have as much “weather noise” in GMST. Kosyannis didn’t include EchoG, so it may be that some models get too much noise and others too little. (I can’t say yet.)
2) Oddly enough, even with EchoG may or may not end up resulting in lots of “noise” for individual locations.
So, for example, it’s technically possible for the temperature of the entire planet to move up and down too much as a whole, but fronts don’t move around too much. So, for example, when the planet warms +1, we see Chicago goes up +1, New York goes up +1, and pretty much everywhere goes up +1.
It’s possible if a planet behaves like this, then the variability for GMST averaged over the whole planet could be too large, but the variability for Chicago would be too small.
Why? We know that even if the planet’s temperature as a whole doesn’t change, the temperature does fluctuate in Chicago, NewYork etc. So, it’s mathematically possible for the GMST to vary too much in some model but temperature averaged over cities or counties to vary too little.
And, lest someone suggest I’m saying “mathematically possible” to suggest something unlikely in practice… I’m not using it that way. I haven’t thought of any reason why it would be unlikely to see one type of variability be “too high” while the other is “too low”.
It’s also notable that the least squares fitting method used by Demetris and his group to interpolate GCM grid-point temperature and precipitation series into the eight test locales gave the most latitude possible to the GCMs. Their method actually derives empirical grid point weights that minimize the difference between the final interpolated GCM time series prediction and the test series, before evaluating the correspondence of the GCM predictions with the test series.
Other very reasonable ways of interpolating the grid point data could have been used, such as weighting the grid points for distance, and/or for altitude. These other methods would almost certainly have given a larger difference between the interpolated time series and the test data series. So, in a way, Demetris and his group used an evaluation method very friendly to GCMs.
lucia,
Maybe the planet’s temperature is really a constant, and we see those fluctuations due to sparse sampling and measurement errors. And then we try to find a theory that explains those fluctuations.. Some hot-spot theory needed for ice ages then, though 😉
SteveMc
Agreed. Even if GCMs are totally horrible (whatever horrible might be), there is still plenty of reason to expect that doubled CO2 raises temperature.
The reason for looking at models is not to disprove warming. It’s to determine the likely accuracy or precision of models with respect to predicting the rate of warming and the total amount of warming that may occur. It can be difficult for some people to believe, but in science and engineering, models that are off by a factor of 2 can be useful. Heck, sometimes even being off by a factor of 5 can be useful, provided we get a some idea how modifying a design might change performance.
That said, we want to know the accuracy or precision of models so we can properly weigh their predictions when making decisions.
re 56. Lucia, as I noted on your site have a look at the hurst coeff of Echo G.
Echo G looked underdamped.
Make sense? it bounced between boundary conditions with a raggedness and velocity that is above that viewed in nature and below that viewed in other models.
Eyeballing all the way, of course.
Can someone talk about (tables 4-6) why the correlation coefficient is quite high for the monthly data, but for the yearly data the models show little and negative correlation between the observed data and the modeled data?
And why is there no autocorrelation column for the monthly data (table 4)? Is this because there is a high degree of autocorrelation for the monthly data?
Tom D, you say:
Suppose I set up a program to generate an annual sine curve which is highest in August and lowest in February. Then I measure the correlation between that and monthly temperatures. Of course, since monthly temperatures go up and down in a roughly sinusoidal fashion, I’ll get good correlation with just about any monthly temperature series you can name.
However, when I go to check my sine wave against annual data, they will likely have very little correlation.
So this indicates that the models can reliably tell winter from summer, but are not much use other than that.
w.
Willis
Oh.. you’re probably being too tough on the models. I bet they can reliably tell the poles are colder than the equator too. In fact, I bet the prediction that the poles are colder than the equator is “robust”!
(As far as I can tell, all “robust” means is that at least 70% of models agree on some feature. So, if at least 70% of models show the poles are colder than the equator, that would be a “robust” finding. In this particular instance, it would happen to be both robust and qualitatively correct. Of course, some findings had darn well better be robust! )
Demetris, in his most excellent paper, has shown that the models are wrong. Given that is true, it raises a very interesting question. How is it that, after what is likely thousands of person-years of work refining and adjusting and fine-tuning, the models are still so wrong? I mean, if we haven’t built the killer model yet, it’s not for lack of trying.
My answer is that the models proceed from an very very basic a incorrect ssumption. This is the assumption that the action is taking place on a level substrate. By this I mean that the climate is free to go in any direction. If it gets pushed two forcing units north or south, that’s the way it goes. There is no preferred direction, all states are equally possible. There is no Le Chatelier principle pushing things back to the center. There is no equilibrium, or even quasi-equilibrium. It is a marble rolling around on a flat plain, with fences that represent extreme conditions. It bounces around between these fences like a billiard ball.
In reality, the climate as a flow system is heavily constrained by the Constructal Law (see the work of Bejan). It realigns itself constantly in order to maximize global performance subject to global constraints. A good example of a flow system following the Constructal Law is a river. You can build a breakwater, but the river may just go around it. It forms oxbows, and then cuts off the loops. It never settles in one state, and it establishes its own pattern. You can’t just push a river two forcing units north, and have it go two forcing units north. It has preferred states, and it adapts and changes to maintain those states, despite humans trying to force it.
That is why the models don’t work. They think the climate is made of Play-Do™, that when you push it with your fingers it just molds to that shape, and it holds that shape until something else moves it around. That is not the case. It is an active system, moving tera-watts of energy, with constant powerful dynamic adjustments that maintain the maximized state. It has an actively maintained quasi-equilibrium state that it revolves around, without ever actually reaching it. The current models are tinkertoys compared to that system.
I’m in the process of developing a constructal-based model, to see where that might lead … slow going and early days, though …
w.
Re #69: Willis, GREAT post! Made sense to me.
A short question related to Hurst coefficient, does the equation
hold, where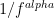 is the power spectrum of the series X, and H is defined as in [1] Eq. 3.,
is the power spectrum of the series X, and H is defined as in [1] Eq. 3.,
?
[1] D. Koutsoyiannis, Hydrological Persistence and the Hurst Phenomenon
(and how to put text on top and bottom of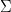 ? )
? )
…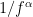 is the power spectrum …
is the power spectrum …
#21 (bender);
I completely agree with your review of Koutsoyiannis (2008). In addition to its rigor and clarity, the paper is also beautifully written and a pleasure to read.
Koutosyiannis asks an obvious question with respect to GCMs: Do GCM predictions correspond to the system they purport to represent? Based on a careful review of a small sample of sites, Koutsoyiannis finds substantial discrepancies between the models and reality. Apparently the GCMs have no predictive skill in many cases of practical importance. This is worrisome.
As always, more work is needed, and many details of Koutsoyiannis’s methods will need to be explored and confirmed. However, at the very least Koutsoyiannis has identified some extremely important issues.
IMHO, this is one paper that everyone interested in climate should read.
I thank SteveM for calling attention to it.
We should expect that at some point when you are ready, you will provide us with a Conceptual Design Document for this model, and eventually a Detail Design Document, as your thinking progresses sufficiently.
In other words, you will use engineering design principles to create your model — recognizing that its purpose is to support research activities, and therefore its design will ebb and flow significantly depending upon where the results of your research activities take it.
The fact that the design ebbs and flows significantly as the model is developed and perfected will not be used as an excuse not to document and archive the design at critical check points — the most important check points being whenever you decide to publish your initial and intermediate results.
Let us also expect that the model is designed from the git-go to be verified by physical measurements and observations, and that your conceptual and detail designs will descibe what kinds of testing methods will be applied, how, and when.
In other words, in your role as a climate research engineer, we expect you to maintain a very high standard of personal integrity and personal discipline in performing your work, just as we would expect of any licensed Professional Engineer.
Re #71
I haven’t checked the detail but the first equation surprised me, I would expect to see:
alpha = 2H – 1
… which is the equation I’m more familiar with. Not sure where 4H-2 comes from?
Re: #71, #75
Indeed it is 2H – 1; see equation 7 in same reference, where frequency is denoted by omega instead of f.
#45 bender,
See here
Willis,
Which is why they put in fudge factors like viscosities orders of magnitude higher than the real physical viscosities. Without them, the models rapidly go off the table. Rather than look for a climate mechanism that would keep the system constrained, they just fudged it. Initially, I don’t think they even had fences. They would ‘force’ the model with measured sea surface temperatures or some other parameter. I remember reading about how the modelers were so proud about achieving stability without the need for external input. My immediate thought was that now the variability was too low.
Maybe the planet’s temperature is really a constant, and we see those fluctuations due to sparse sampling and measurement errors.
I think nobody’s conclusively proven that there is such a thing as a “global average temperature”; the concept is, I would contend, nonsense.
Yet even if we have a single planetary temperature, as reflected in the anomaly as a proxy from samples of locations, there is no promise that number actually reflects a rise or fall in energy levels. All it tells us (perhaps) is how the departure from average for the locations looked at behaved; even if accurate, it’s quite possible that was offset by a location some distance away up, down or sideways. For example +.2 here and -.2 two feet up and eight feet over.
Oh, yeah, and over the 130 years, the “global mean temperature anomaly” has never been out of the range the samples are recorded, whole degrees.
Clutching at straws.
#75, #76
Thks, 4H-2 is from Pilgram & Kaplan, but I guess the definition for H is different in that one:
Pilgram and Kaplan, A comparison of estimators for 1/f noise, Physica D 114, 1998
Speaking of clutches, what do you suppose is the Global Mean Surface Temperature (GMST) of Alan B. Sheppard, Jr.’s golf balls on the Moon?
The Earth’s planetary temperature may be described as the sum of its air and surface temperatures, and it does constantly change. It is not constant.
I would love to see some good analysis of model predictions vers actual results. However in my opinion an analysis based on 8 stations is not enough. After all the ‘John V confirmation’ of the GISS temperature trend was on a similar number of stations and the consensus here was that it was not significant due to the low number.
Using my eyeball and looking at GISS temperature trend maps, and IPCC projections, I thought there was some resemblance with the warming pattern predicted by the models (eg more warming on far northern land masses), the biggest failure being a lack of warming in Antarctica.
Does anyone know of a test of the model predictions that uses more than 8 stations, and is more rigorous than using eyeballs to say ‘that looks about right’?
re 84. there are taylor diagrams for all the models.. somewhere on the web. Most do ok WRT to temp but totally miss on the precipation side of things. I’m not in the mood to hunt crap down for people. Go check the IPCC sites for your own self. knock yourself out.
Michael H, you say:
A very large underlying problem is that we don’t know how the models were tuned. My guess is that they were tuned to reflect the major features of the historical record. However, they’re all reticent about the exact tuning process. This makes any analysis of model hindcasts very suspect.
I base my guess on a couple things. One is that the models are able to get the big stuff right, but miss on the little stuff.
The other is an analysis I did last night, comparing the GISS Model E hindcast results with the GISS surface station record. I compared temperatures grid by grid, and found a very curious pattern that I’d never seen before. This was that the larger the warming in a given gridcell, the more successfully the model was able to hindcast the result. I’ll post the graph when I get home this evening, or on the weekend.
My next move will examine how well the GISS model agrees with the HadCRUT record. If the results are different, it would tend to indicate that the GISS Model E results are tuned to the GISS data … I’ll report back on that one.
w.
w.
RE 86 Willis. EXACTLY RIGHT! the other thing you will note is that modelE Misses the dips. those multi year downward dips. The only dips it gets right are the dips associated with volcanic forcing.
Koutsoyiannis makes clear that he analyzed only a few of the models used in IPCC TAR and AR4. His paper’s results are confined to those models that he analyzed, and do not apply to the models he did not test.
#88 — That rats can carry fleas transmitting bubonic plague applies only to those rats they tested for infected fleas, and does not apply to the rats they did not test.
“Whereas a common argument that models can perform better at larger spatial scales is unsupported.” Is the argument that they don’t perform better at larger spatial scales supported?
=============================================
#89 – But what about mice and squirrels? Is there any reason to believe that the set of models choosen is representative of the whole? For example, Echo-G seems to have a huge amount of weather noise at the GMST level which sets it apart from other models.
That’s a cute analogy. Are you arguing that the untested models are identical to the tested ones? If so, please explain why the differences between the models are insignificant.
#84
No need to criticize DrK on that point becausae he was self-critical on it already, right in the ms. Was John V self-critical or weasly defensive? I have my guess. Bottom line: yes, more is always better. Yawn.
Re # 84:
Michael Hauber, perhaps this article is interesting for you (and others):
‘Performance metrics for climate models’
P. J. Gleckler, K. E. Taylor, C. Doutriaux (2008)
JOURNAL OF GEOPHYSICAL RESEARCH, VOL. 113, D06104.
ABSTRACT
Objective measures of climate model performance are proposed and used to assess simulations of the 20th century, which are available from the Coupled Model Intercomparison Project (CMIP3) archive. The primary focus of this analysis is on the climatology of atmospheric fields. For each variable considered, the models are ranked according to a measure of relative error. Based on an average of the relative errors over all fields considered, some models appear to perform substantially better than others.
Back to Koutsoyiannis:
The statement in the Concluding Remarks that stands out:
“The huge negative values of coefficients of efficiency show that model predictions are much poorer than an elementary prediction based on the time average. This makes future climate projections at the examined locations not credible.”
This climate modeling all reminds me of Bob Euker’s advice to once baseball-playing Michael Jordan: “Keep swinging – eventually the ball will hit the bat!”.
re # 75,76, 80
Maybe I’m missing something ( discrete world vs. continuous etc), but random walk is commonly referred as 1/f^2, and then H would be 2/3. This code gives values close to 1 for random walk, which agrees more with the 4H-2.
Re #98
Interesting, very similar to code I wrote a while back based on one of DK’s papers. Attached below.
function HurstExponent = EstimateHurstExponent(TimeSeriesVector)
% Check TimeSeriesVector is a row vector
DataLength = length(TimeSeriesVector);
TimeSeriesRowVector = reshape(TimeSeriesVector, 1, DataLength);
% Take steps up to length/6
VarSteps = [1:floor(DataLength/6)];
% Store the variance results for each step
VarData = zeros(size(TimeSeriesRowVector,1), length(VarSteps));
for VarStepLoop = 1:length(VarSteps),
% Number of steps this time
ThisStep = VarSteps(VarStepLoop);
% Trim the data to exactly fit the number of steps
ExtentLimit = DataLength – mod(DataLength, ThisStep);
% Reshape so integral down column and standard deviation across row
ReshapedDataSeries = reshape(TimeSeriesRowVector(1:ExtentLimit), [ThisStep ExtentLimit./ThisStep]);
% Compute standard deviation
VarData(VarStepLoop) = std(sum(ReshapedDataSeries, 1), 0, 2);
end;
FitOutput = polyfit(log(VarSteps(:)), log(VarData(:)), 1);
HurstExponent = FitOutput(1);
This is very similar to the code you linked, except my code generates standard deviations at (1,2,3,4,5,6 …) steps compared to the code you linked which generates powers of two (1,2,4,8…). I tested this code on both a random walk:
TestData = (cumsum(randn(1,5000)));
HurstExponent = EstimateHurstExponent(TestData)
And on the flicker noise generator you posted here a while ago (single quotes on lines 4 and 5 may get mangled by WordPress):
NumXPoints = 2000;
cycles=25;
out=zeros(NumXPoints,1);
randn(‘state’,sum(100*clock))
rand(‘state’,sum(100*clock))
V=2*1/cycles;
sV=sqrt(V);
r=randn(1,cycles)*sV;
rphase=rand(1,cycles).*(2.^(1:cycles));
rphase=floor(rphase);
for i=1:NumXPoints
r(1)=randn*sV;
for z=1:cycles
if rem(i+rphase(z),2^z)==0
r(z)=randn*sV;
end
end
out(i,1)=sum( r );
end
The estimator yields values in the region 0.9 to 1.02 for the random walk, and around 0.75 to 0.95 for the flicker noise simulation. (I really should do a histogram) These seem similar to the values you report.
I’ve got an estimator based on rescaled range kicking around somewhere, which I think yields higher values for H. It is worth noting that most estimators for the Hurst exponent tend to have large confidence intervals and may be biased.
Comments?
Re #100
That code is in “pre” tags, but they don’t appear to work, so the code and commentary are all mixed up. Sorry ’bout that.
The HTML version loses the indents as well, making it a little less readable. Copy n paste into a MATLAB editor and ctrl-a ctrl-i as usual to fix!
Re#99:
Scott-in-WA. What’s your problem?. You can just go to the websites of the GISS modelE or the CCSM and find the documentation of the models. If the used models are not explicitly documented they give references. I’m not a climate modeller but with a bit of literature search I could find out what kind of subgrid models they use for the ocean and atmosphere.
#69
I am familiar with Bejan work but am not sure if this approach will give quantitatively usable results even if it is probably qualitatively the right way to look at this problem .
Actually I notice with a certain satisfaction that things are moving towards the position that has been mine sice I began to interest myself for climate matters some 10 years ago .
In the beginning people thought of the climate as a deterministic system . The climate trajectory was supposed to be computable and predictable and inaccuracies were only due to the lack of computing power and crudeness of the parametrizations .
After having multiplied the computing power by 100 – 150 in the last 10 years and the time spend on parametrizations by a similar factor , the models are still as inaccurate as they were and what increased is only the confidence that they indeed are inaccurate .
This in itself is a powerful signal that there is a very fundamental error somewhere in the approach .
If something like that had happened in a more serious scientific branch (like high energy physics f.ex) , people would have dropped the wrong methodology already long ago .
The approach begins to slightly change now .
First as there can be no trust in any individual model , the “ensemble theory” has been invented according to which every model gets “something” right (but nobody knows what) and something wrong (everything else) .
By averaging the model results , the wrongness cancels out or at least reduces but the rightness stays .
This theory seems to me silly and based on no serious physics .
Second the modellers grudgingly abandonned determinismus and try to heal the problem by ergodicity .
Schmidt even says that their models are “chaotic” showing hereby that he doesn’t know what chaos is .
What they try in fact is to handle the climate with statistics – while the evolution of every individual parameter that constitutes the climate can’t be computed and predicted , the AVERAGES (time and/or space) of the said parameters are robust and significant while any difference between a realisation of the parameter and its average obeys some statistical law .
That is the theory in which Realisation = Climate + Noise .
It is analogous to Kolmogorov turbulence theory and that’s why I guess Schmidt is calling that “chaos” .
Of course any analogy stops here because the assumptions taken by Kolmogorov (homogeneity and isotropy) that give sense to his theory are absent from the climate theory .
And of course , not surprisingly , according to D.Koutsoyannis and other work that begin to appear now the “healing” of the models by salvaging at least the time averages , fails too .
What is left and what looks like W.Eschenbach’s approach is the deterministic chaos .
The best example and analogy is the solar system problem .
It is clearly deterministic and even not very complex because there are only a few bodies and a few ODE .
Now it happens that it behaves like the Lorenz system – the trajectories of the bodies are not predictable .
While A trajectory is always computable by numerically solving the ODE for an arbitrary time period , this computed trajectory (that Dan Hughes would call “just a series of numbers”) has little to do with the real trajectory .
The system is not stochastic either – asking about probabilities of trajectory excentricity or time averages of distances (Body A – Body B) makes no sense .
Making N runs (N large) with varying initial conditions and varying time periods will give some insights about what the system MIGHT do but no insight at all about what it WILL do or indeed with what probability it MIGHT do this or that .
And the differences between trajectories are not just small numbers – it may be so dramatic as the difference between turning a circle 500 millions years and definitely leaving the solar system .
Fortunately there is at least ONE question that can be asked of such a system and that is the one of stability .
We may ask after having observed the system for a certain time , are the trajectories stable (e.g will there not be a catastrophic divergence) ?
There are mathematical tools for that like f.ex the KAM theorem .
Of course it is more than probable that the climate system is nowhere near to an integrable Hamiltonian system where KAM would apply but similar approaches could be attempted .
As there will be more and more results like those of D.Koutsoyannis , I am convinced that people will do one day the last step to be made .
Namely that the climate is neither deterministic nor ergodic .
1) The trajectories unpredictibly evolve between different quasi steady states . The causality is not clear cut and for instance there is an infinity of different initial conditions that lead to the same final state .
2) There is no particular time scale at which the system is more stable or predictable (e.g yearly averages don’t behave “better” than hourly averages)
3) There is no statistical law describing the distances between 2 different trajectories and no probabilities of achievemenet of the different quasi steady states .
4) Observation of the last 3 billions of years shows that the envelope of the possible trajectories is bounded so the system is stable .
5) The results above are independent of the computing power and the size of integration steps .
6) The variation of a single parameter (f.ex CO2 concentration) may lead to wide range of different final states and symmetrically those states can be reached without any variation of this parameter (f.ex CO2 concentration) .
Then and only then people will stop bothering about CO2 because they will understand that all kind of unexpected things
happen and will happen regardless of CO2 concentrations and the longer we observe , the more unexpected things will happen .
With the usual irrationnal resistance of people towards any change , most of these unexpected things will be perceived as bad and dangerous 🙂
However taking action with regard to a supposed qualitative impact of some climate variable on the final state afer a certain time would make sense only if the specific costs/inconvenients of the action were near to 0 or if the time horizont was very short .
#103
aka: The “Healing” Principle.
Thank you, Tom Vonk, for the pithy language that brings to light this dirty little assumption.
Tha averaging of GCM ensemble output as a “salvage” operation.
This has no scientific basis. It is a political device invented by IPCC. Political in the sense of being designed to be inclusive of the various modeling groups so that no one gets offended by being left out. This is nothing but a team-building, consensus-making device. Convenient for movie makers. But scientifically without merit.
Your turn, Gavin.
[Art Wegman: what about this ergodicity issue mentioned by Tom Vonk? Please examine the statistics of GCM “ensembles”.]
90 (kim) Can anyone help me with this question. I believe Demetris addresses it in the body of the article, but I don’t understand.
==================================================
Re: Kim’s question. The problem is that at small spatial scales we have better data and sometimes stronger trends, which makes testing more reliable. At continental scales, so much is averaged that trends are much less and it is harder to tell. A long thread at CA some months ago tested Hansen’s 1988 projections at regional scales vs estimates of what actually happened since 1988, and it is hard to say the model did well.
#92 — They all express the identical core physics, take the same approximations to suppress unresolved turbulence, apply the same general suite of parameterizations, and are adjusted to the same empirical climate. Variation within species.
Oof. If ever there existed a distortion of the CLT, this would be it. As bad as, if not worse, than applying the LLN to justify ridiculously accurate temperature readings of the planet (if such a physical concept even exists).
Mark
bender #105
Do you feel sure about this? It certainly sounds counterintuitive, but in other areas using weighted averages of disparate models is surprisingly effective so long as each model has access to unique information.
In the current Netflix movie prediction contest, for example, all the leaders are currently using this approach. I realize there are differences, but combining the results from multiple models indisputably helps to reduce the RMSE of movie predictions beyond the skill of the individual models.
This paper entitled “The use of the multi-model ensemble in probabilistic climate projections” by Claudia Tebaldi and Reto Knutti seems like it deals with the issue. I’ve only skimmed it (and don’t have the knowledge to critique it), but perhaps it would be of interest to you.
#114
I thank you for your skepticism.
Some context is required to explain the allegation more fully. It goes without saying that if models have predictive skill, then ensembles will perform better than individuals. However if the models have NO predictive skill then there is no “healing power” in the salve. What I am alleging with IPCC is that they put the cart before the horse, by deciding to accept ensemble avergaing on principle BEFORE asking people like Koutsoyiannis to investigate model skill. This is pure speculation as I was not in the room when the method was decided upon. [Don’t you wish you knew HOW this was decided upon, so that speculations would not be necessary?]
Accepting a method on principle, without a priori proof of skill, is not scientific. It’s legal. Just not scientific.
Thank you for the paper. I believe I’ve read that one, but I’ll check again.
Koutsoyiannis confirms what the NCPA said about climate models
http://www.ncpa.org/pub/st/st308
The Forecasting Models Are Unreliable. Complex forecasting methods are only accurate when there is little uncertainty about the data and the situation (in this case: how the climate system works), and causal variables can be forecast accurately. These conditions do not apply to climate forecasting. For example, a simple model that projected the effects of Pacific Ocean currents (El Niño-Southern Oscillation) by extrapolating past data into the future made more accurate three-month forecasts than 11 complex models. Every model performed poorly when forecasting further ahead.
The Forecasters Themselves Are Unreliable. Political considerations influence all stages of the IPCC process. For example, chapter by chapter drafts of the Fourth Assessment Report “Summary for Policymakers” were released months in advance of the full report, and the final version of the report was expressly written to reflect the language negotiated by political appointees to the IPCC. The conclusion of the audit is that there is no scientific forecast supporting the widespread belief in dangerous human-caused “global warming.” In fact, it has yet to be demonstrated that long-term forecasting of climate is possible.
gb
Based the wording in some of the papers describing the model, the climate modelers use subgrid models that are even more over simplified than those used by enginners used back in the 80s and 90s. Those engineering models kinda-sorta worked and kinda-sorta didn’t.
They were useful, but not very precise. In response, engineers developed better, more accurate models.
Indeed,One should read Gibbs on the problematic issues for the “observer”when using the present to predict the future.
#116 follow-up
Ever watch “Who wants to be a millionaire”? When the contestant is stumped on a multiple choice question they can decide to “poll the audience”. The contestant must then decide if the audience is, a priori, skillful. Sometimes the audience members are found to be reliable. Sometimes not.
GCMers are audience members. The public is the contestant. IPCC is the polling machinery. DrK is basically probing the audience members for individual reliability – something “Millionaire” does not allow. (Because it is such a laborious task it would put the viewing audience to sleep.) If the contestant had DrK’s insight, he would always know whether or not to rely on the audience. And that wouldn’t be any fun.
#117
NCPA is skeptical about GCM skill. However they fail to address the question of the source of the current warming trend. Being skeptical is fine, but a scientist is obliged to go further and speculate on mechanisms, to generate a working hypothesis. When it comes to decision time, precaution may dictate accepting the working hypothesis as tentatively correct. NCPA conveniently avoids the whole issue of (1) alternative explanations and (2) the wisdom of taking precaution against extreme risks.
Thanks for fixing my quote Mr. Editor.
Interesting analogy, bender. Extending that, i.e., averaging the audience members’ answers, does it improve the result? Nope, there could only be one in the audience qualified to answer, but his voice is lost in a sea of GIGO results.
Mark
I’ve moved some comments to Unthreaded. In my first post, I asked people:
I re-iterate this request – no more OT posts. Link to the paper.
#122 bender, thanks as always for your thought provoking comments. You say:
OK, fair enough. My working hypothesis is that there is absolutely no evidence at all that what we are seeing is anything other than natural variations in climate.
…
You are correct as far as you go, bender, but before you go, before demanding a hypothesis for something, you need to specify the “something” that you want the hypothesis to explain.
For example, you’re sitting watching a lovely river flow by. If someone comes along and says “that river is flowing strangely, and my hypothesis is that it is caused by increasing CO2”, what is the first question you would ask? I doubt that it would be to propose an alternative hypothesis for the alleged “strangeness”. I suspect you would ask “what do you mean by ‘strangely’?”
So, just what is the anomalous result, what is the peculiarity, what is the odd thing out, what is the “strangeness” for which you would like a hypothesis?
Please be specific, and show your work.
w.
Steve: Willis, c’mon. What does this have to do with Koutsoyiannis?
Steve, my understanding was that bender was implying that Koutsoyiannis was not acting in a scientific manner because he had not provided an alternative hypothesis to explain the phenomena.
If that is incorrect, if bender was not talking about Koutsoyiannis, then please snip my post with my apologies.
w.
#104 Willis, I was referring not to K2008, but to NCPA, cited in #96. DrK’s alternative hypothesis is clear to me: “trends” are just low-frequency noise of unknown origin. Like many, I think it is too early to dismiss this argument. There are too many ways for it to be correct.
My apologies for the misunderstanding, bender, my bad.
w.
The job of the NCPA was not to find the source of warming, but to valuate the IPCC forecast or prediction for the policy maker.
‘Although the IPCC’s 1,056-page report makes these dire predictions, nowhere does it refer to empirically-validated forecasting methods, despite the fact these are conveniently available in books and articles and on Web sites. These evidence-based forecasting principles have been validated through experiment and testing and comparison to actual outcomes. The evidence shows that adherence to the principles increases forecast accuracy. This paper uses these scientific forecasting principles to ask: Are the IPCC’s forecasts a good basis for developing public policy? The answer is “no.” ‘
Steve, rather than trying to close this discussion down (and I understand why) can we move it to it’s own thread.
Tom Vonk, brilliant explanation of the state of modelling, it’s so obvious I could have articulated it myself, if I had the clarity of reasoning that you clearly have. And thanks to to Willis & bender for useful contributions
Nathan #94 Tebaldi and Reto Knutti
From Drk’s
The difference in the two papers is clear. T&K are write and categorize problems with multi-model ensembles. DrK is falsifying certain claims (assumptions).
The two works overlap in several areas. DrK used Tebaldi, C. & Knutti, R. (2007) The use of the multi-model ensemble in probabilistic climate projections. Phil. Trans. Roy. Soc.
From DRK’s conslusion
Right. And now I have another job for them: find the source of warming.
Bender #110:
Not by NCPA but by CDC and ESRL, here is an attempt to find the source of recent warming, i.e. the climate system natural variability.
#111 Thank you for closing the loop and relating this back to DrK’s paper. I am very interested in internal i.e. natural climate variability. I am most interested in what ocean specialists such as Dr. Carl Wunsch have to say on the topic.
I don’t know is anyone has noticed this: http://www.climatescience.gov/Library/sap/sap3-1/final-report/default.htm
I’m reading through the report now. With every page, I say to myself, what would Gerald Browning, Tom Vonk, Tim Ball, Craig Loehle, Pat Frank, Demetris Koutsoyiannis, the physicist and commentator on scientific issues Freeman Dyson — among many others knowledgeable on this topic — say about this report?
It would also be useful, were one to be given the opportunity, to examine the entire end-to-end operational setting of these government-funded GCM models to see how they are being handled from a code base management perspective and design basis management perspective, and a data management perspective — i.e., are the models developed and operated in a way that is consistent with the software lifecycle QA standards commonly aopplied to other government funded activities such as national defense and nuclear production operations.
More concerning “Climate Models: An Assessment of Strengths and Limitations.”
Here is the press release from DOE’s web site at: http://www.energy.gov/news/6442.htm
Within the DOE press release, I’ve highlighted topics of particular interest relative to the paper which is the subject this discussion thread.
——————————————————————————-
July 31, 2008
Climate Change Science Program Issues Report on Climate Models
WASHINGTON, DC – The U.S. Climate Change Science Program (CCSP) today announced the release of the report “Climate Models: An Assessment of Strengths and Limitations,” the 10th in a series of 21 Synthesis and Assessment Products (SAPs) managed by U.S. federal agencies. Developed under the leadership of the U.S. Department of Energy (DOE), this report, SAP 3.1, describes computer models of the Earth’s climate and their ability to simulate current climate change.
“Complex climate models are tools that provide insights and knowledge into how future climate may evolve. To assure that future climate projections are used appropriately, it is crucial to understand what current models can simulate well, and where models need improvements,” said David Bader, with DOE’s Lawrence Livermore National Laboratory and the coordinating lead author for this SAP report. “This report makes an important contribution in helping to describe and explain the current state of high-end climate modeling for the non-specialist.”
The SAP 3.1 report describes complex mathematical models used to simulate the Earth’s climate on some of the most powerful supercomputers, and assesses their ability to reproduce observed climate features, and their sensitivity to changes in conditions such as atmospheric concentrations of carbon dioxide. The report notes that “the science of climate modeling has matured through finer spatial resolution, the inclusion of a greater number of physical processes, and through comparison to a rapidly expanding array of observations.” The authors find that the “models have important strengths and limitations.” The report assesses how well models simulate the recent observational period; it does not deal with climate change predictions.
The report organizes the discussion of these strengths and limitations around a series of questions, including: What are the major components and processes of the climate system that are included in present state-of-the-art climate models? How uncertain are climate model results? How well do climate models simulate natural variability? How well do climate models simulate regional climate variability and change?
The report documents the improvement in climate model fidelity over the past decade. As emphasized by the Intergovernmental Panel on Climate Change (IPCC), modern models faithfully simulate continental to global scale temperature patterns and trends observed during the 20th century. Despite this progress, a number of systematic biases across the set of climate models remain, particularly in the simulation of regional precipitation. On smaller geographic scales, when compared against the current climate, the simulated climate varies substantially from model to model. The report notes that “an average over the set of models clearly provides climate simulation superior to any individual model,” and concludes that “no current model is superior to others in all respects, but rather different models have differing strengths and weaknesses.”
The report also describes “downscaling,” which is the use of methodologies to generate higher resolution information from global models results for applications on the regional and local scales. Several downscaling examples such as applications focusing on water resources and surface climate change are illustrated to demonstrate how model results can be applied to a diverse set of problems.
To develop the SAP 3.1, DOE chartered a Federal Advisory Committee comprised of 29 members drawn from academia, government scientists, non-profit and for-profit organizations that drafted and oversaw the review of the report in accordance with the CCSP guidelines. The lead authors include David Bader (coordinating lead author) and Curt Covey, Lawrence Livermore National Laboratory; William J. Gutowski Jr., Iowa State University; Isaac Held, NOAA Geophysical Fluid Dynamics Laboratory; Kenneth Kunkel, Illinois State Water Survey; Ronald Miller, NASA Goddard Institute for Space Studies; Robin Tokmakian, Naval Postgraduate School; and Minghua Zhang, State University of New York, Stony Brook. SAP 3.1 is the third and final SAP that DOE coordinated for the CCSP.
The SAP 3.1 report and additional information about the CCSP are available from the Climate Change Science Program.
Information about DOE’s climate change research is available from the Office of Biological & Environmental Research.
Media contact(s):
Jeff Sherwood, (202) 586-5806
Scott-in-WA (#115),
I do not see a single well known mathematician or numerical analyst
on the committee. This is no surprise as these committees are carefully
selected to support the desired answer sought by the agency. How many committee members are dependent on climate funding (directly or indirectly)?
Jerry
Seeing a report of this kind coming from DOE is all the more irritating to me personally, in that few — if any — of these people could survive for long working in the nuclear side of the house, where exceptional process rigor and an exceptionally disciplined approach to all facets of the job is the day-to-day performance expectation for everyone who works there.
Gerald: Thanks for hanging around here. I appreciate your input.
Here
#119
Of course. The dodge. Thanks.
#120 Bender says:
“Of course. The dodge. Thanks.”
The RC argument is always:
1) A single realization that happens to match the models evidence that the models are valid.
2) A signal realization that does not happen to match the models is evidence of weather and cannot be used to cast doubt on the models.
Gavin is notorious for trying to discredit anyone that does good science.
As soon as a global climate model readjusts a vertical column to unphysically alter the large scale solution in order to maintain hydrostatic balance (overturning due to unrealistic heating parameterizations necessitate this adjustment), there is no mathematical
theory that can justify the nature of the ensuing numerical solution.
This is an ad hoc fix and nothing more.
Jerry
Gerald Browning,
Does the model redistribute the humidity when it makes the adjustment to maintain hydrostatic balance? That might explain a lot.
Okay, then. Explain why a single model run tested against single stations means that GCMs are bad at predicting long term global trends. I haven’t read K’s paper, but this seems to be an issue with his test.
Then, read it and quit speculating.
Done.
Didn’t answer the question for me.
So, please explain how this test proves GCMs are bad at global forecasting.
Borus, I’ll explain after the thread at RC has developed somewhat. (They need some rope before they can really hang themselves.)
Boris, without reading the Koutsoyiannis paper you say:
After reading the paper you say:
It appears to me that K. et al. did not say it proved that GCMs are bad at global forecasting. They said that they were bad at local forecasting. They also said that the idea that the models could be bad at local forecasting but good at global forcasting was an “unproved conjecture”.
So you’ve got the stick by the wrong end, K. et al. did not make the claim that you are arguing against.
If you want us to believe that the models are good at global forecasting, you need to establish it by testing their output. However, you need to test their output against something that they have not been tuned to. As Koutsoyiannis pointed out, for the IPCC TAR models we now have 18 years of data to run the tests against. So get on out there, Boris, and run the tests that you think should be run to prove your point.
Because as it stands, you seem to think that we have to establish your “unproven conjecture” for you.
w.
re 126
The question
was posed in relation to this assertion:
Isn’t the point being made is that the conjecture that an aggregation of GCM outputs is a valid projection of global climate, is unproved. The question is not to prove that GCMs are bad a global forecasting but to show that these models, and especially aggregated outputs from these models, are of any use.
Schmidt’s main point seems to be that the range of aggregated GCM outputs is so wide that any climate history will fit within it. It is not that they are “wrong”; it is that they have no real use. Schmidt mentions Popper in this blog post. C. S. Pierce is much more pertinent to this that Popper.
#124 Boris
There are two sides to this coin. The other one is “Explain why a single model run tested against anything means that GCMs are good at predicting long term global trends”. These two statements go hand-in-hand. If the latter statement is meaningful, so is the former. Since it is the habit of climate modelers to present a single run as a convincing demonstration of the “skill” of their models (see the IPCC reports and the latest wonder from CSIRO), one has to conclude that they must have criteria by which they can decide that these models are “good” enough on which to base their “very likely” conclusions. Tell us their criteria and I’ll tell you how to test if the GCMs are bad.
Okay.
Take a look at the last line of the abstract:
Is the whereas clause a comment or a conclusion?
131 (Boris) Good question. I believe that ‘whereas’ has the meaning of ‘on the contrary’ instead of ‘therefore’ or ‘since’.
==================================================================
Gavin weighs in. It turns out that, when you do things the way he wants to,
Let’s look forward to the AR5 definition of “mostly something similar” and how it accommodates all that LTP around the Antarctic in the diagram attributed to Blender et al, which is curiously absent from the picture preceding it.
132: Well, that’s the “consensus” definition. 🙂
I see that NASA employee and Hansen bulldog service provider Gavin Schmidt has again refused to provide a link at realclimate to climateaudit, but has linked to Google “climate Koutsoyannis” which brings people here. Of course, had he inserted a Google reference to “climate schmidt”, that would also have brought people here 🙂
Schmidt on Koutsoyiannis.
Poisoning the well and guilt by association. Two logical fallacies in one sentence. [Borus spotted that, though, I’m sure.] But, Gavin, who ELSE reviewed the paper? [And who, pray tell, reviewed MBH98, since we are now in the business of judging papers by their reviewers?]
No, it’s magic. Magic I tell you.
But not all circumstances?
See the sleight of hand? Who said Hurst coefficients ought to be constant? If this supposition makes the model unrealistic, then why would you suppose it? For the purpose of discrediting a model so that it can be summarily dismissed, rather than discussed?
More rope.
If Hurst coefficients in models and real climate system are high then (1) Schmidt’s black and white distinction between “weather” and “climate” is absurd and (2) his approach to “ensemble” forecasting is incorrect. The problem would be that there is no way to fit the forcing parameters to aerosols, GHGs, etc, because there is now way to distinguish internal noise from external signal. The “fit” MUST be a drastic overfit.
Put it this way. Ocean “weather” (recall weather is chaotic) operates on a time-scale comparable to that of atmospheric “climate” (also chaotic). Therefore the conjunction of the two must be chaotic. In which case his “ensembles” are not at all indicative of the true climate ensemble.
I was looking at the AR4 Ch. 8 supplemental material and came across a relationship that looks very unphysical to me.
Here is a graph of diurnal temperature range observations compared to the diurnal temperatures of the 24 models. The models consistently emulate a much smaller range. Near the equator only about 60% of the observed range.
Doesn’t this imply poor convection and or radiation modelling?
It’s worth reminding folks that, despite Gavin’s barking, the “Hurst” parameter originated in a climate time series – Nile River minima, that MAndelbrot calculated Hurst coefficients for many climate proxies – even some of our US tree ring series . I did a post quoting Mandelbrot on weather versus climate – his view was that no line could be drawn. LTP is particularly associated with hydrology, Klemeš having also written interestingly about this.
DeWitt Payne (#123),
The heating (e.g. latent heating is created by change of state of water and thus impacted by humidity) is redistributed until hydrostatic balance is restored.
Note that this means the modelers are unphysically trying to force the model to stay on a large scale (hydrostatic balanced) trajectory when the unphysical heating is trying to switch to a smaller scale trajectory.
And I have shown that if the models increase their resolution to properly resolve the smaller scales of motion, the hydrostatic models will grow unboundedly, i.e. they are ill posed.
Jerry
Roman (130)
The requirements for inclusion of your GCM (global climate model) into IPCC are as follows:
* be full 3D coupled ocean-atmospheric GCMs,
* be documented in the peer reviewed literature,
* have performed a multi-century control run (for stability reasons)and
* have participated in CMIP2 (Second Coupled Model Intercomparison Project).
http://www.ipcc-data.org/sres/gcm_data.html
For some reason I don’t understand, there are no actual criteria that show predictive skill. Also note the weasel word, should, in the actual wording.
re 129.
I thought I was the only person here who ever read CS Pierce.
DeWitt Payne (#123),
Do a google on convective adjustment or moist convective adjustment.
Jerry
DeWitt Payne (#123),
From the Glossary of Meterology
As originally developed, convective adjustment was applied when modeled lapse rates became adiabatically unstable. New temperatures were calculated for unstable layers by conserving static energy and imposing an adiabatic lapse rate. If, in addition, humidities exceeded saturation, they were adjusted to saturation, with excess water removed as precipitation. A related adjustment, (stable saturated adjustment), for stable layers with water vapor exceeding saturation, returned them to saturation, also conserving energy. More recently, convective adjustments have been developed that adjust to empirically based lapse rates, rather than adiabatic lapse rates, while still maintaining energy conservation. Convective adjustment is generally applied to temperature and humidity but, in principle, can also be applied to other fields affected by convection.
Jerry
Curious that the RC thread on Koutsoyiannis et al. 2008 is refenced by a url with the phrase “hypothesis testing and long-term memory” but that it is titled “hypothesis testing and long-range memory”.
The burning of books continues at RC:
Keep the faith.
A constant Hurst parameter is not imposed on the estimation. The data may yield it, but it is not imposed. Looking for a scale break at which H changes is one way to define climate as distinct from weather, but from the studies I’ve seen no such scale break occurs after a few months or, in one case, just under 2 years.
Bender, re #145, I call it the RC whitewash.
Jim Renwick is from New Zealand (where he works for NIWA) and he would be appalled to learn that he is cited out of context to support the notion that models are not reliable. Feel free to send him an email and ask him about it. He’d probably also have a good laugh about the “top UN IPCC scientist” bit.
Re #136, that quote by Gavin looks like it could be fun to play with:
How about if I rephrased it like this?
On a more serious note, many of the points Gavin is discussing have been extensively addressed by Koutsoyiannis or others in the past (e.g. Cohn and Lins). In this paper, Koutsoyiannis and Montanari point out that:
So – hold on, isn’t that agreeing with Gavin? No, Gavin has the nuance wrong. It is also clearly outlined in Cohn and Lins 2005:
The point Cohn, Lins, Koutsoyiannis et al make is that in the absence of better information, we cannot make the assumption that climate isn’t LTP. Gavin’s rephrasing of this into the idea that they are assuming LTP is a very different idea, and indeed a strawman. The problem is those that assume simple Markovian models are adequate – an implicit assumption that LTP is absent – not with those that design their tests to work whether LTP is present or not.
Perhaps it would be beneficial for someone to sit down with Gavin and explain the concept of modus ponens and modus tollens? It may help him to distinguish between “we are assuming LTP” cf. “we are not assuming it isn’t LTP”. They may sound similar, but under rigorous logic, they lead to quite different conclusions.
Bob Koss @ #138
Bob, the graph to which you linked presents another example of an ensemble of climate model results versus the actual single realization with the average and range of the models displayed. When push comes to shove, however, the point will be attempted that as long as the range of all the models “covers” the observed, we cannot say anything about how poorly the models results agree with the observed. (In that case why show the average.)
At equator it appears that the observed is well out of the range of the models, and, as you indicate, would seem to call for some major explaining of this difference even when using the range cover criterion.
Thanks very much, folks, for the warming up of this discussion after Gavin Schmidt’s posting in Real Climate (hereinafter referred to as GS-RC). I am particularly grateful to those who defend my and my colleagues’ work (Koutsoyiannis et al., 2008, hereinafter referred to as Kea08) against criticisms. Despite criticisms, I have several reasons to feel satisfied by GS-RC – and one reason not to be satisfied, as I explain below. I apologize for this reaction, here in Climate Audit, for a post in Real Climate. I confess it is not very kind of me – but here the discussion is “warmer”. Besides, I have a difficulty in writing again in Real Climate after eristic discussions mentioned in my point 3 below. I hope that Gavin will make a formal discussion paper in Hydrological Sciences Journal so that we make this dialogue formal, in a peer reviewed journal. I also address an open invitation to everybody interested for a discussion paper.
1. The first reason I am satisfied is the posting (GS-RC) itself. Gavin did not behave as his readers might expect. Here I refer to the comment in GS-RC, which was also quoted by bender in #146 above:
Not only did Gavin studied the paper and reacted with his article, but he also found some interest in this; quoting GS-RC:
2. The second reason is that GS-RC does not try to report any potential flaw in our methodology and results. In contrast to many others that have criticized the paper on such grounds, Gavin does not state that the locations are too few, or that our interpolation is not correct, or it does not correspond in principle to the observations. In fact there is little room for such disputes of our methodology because, as correctly observed by Pat Frank in #51,
Rather, the central point of Gavin’s criticism is contained in his conclusion:
Obvious? Perhaps – but this does not discredit our research. There are many obvious things worth of several publications in order to fight obvious fallacies. Well known? I doubt. For instance, IPCC would avoid providing maps with geographical distribution of temperature and precipitation changes if the poor GCM performance at a point basis were well known. Gavin prompts the readers to do a Google search with keywords “Koutsoyiannis 2008 climate”. I did this and Google resulted in 7040 entries (among which first is Climate Audit – as already observed by Steve in #135, and second is Climate Science, Roger Pielke Sr. Research Group News). So following Gavin’s proposal, I conclude that the problem we addressed and our “obvious” results were not “well known ahead of time” before our publication. Otherwise these discussions in blogs would have not appeared.
3. The third reason is that GS-RC highly promotes the idea of long term persistence (LTP), or long range dependence (LRD), or Hurst-Kolmogorov (HK) behaviour, and its relevance to climate. (I avoid repeating his term “memory” here because I think it is a misnomer as I have explained elsewhere – but this is just a difference in terminology). He also puts several questions to be investigated with respect to HK and climate. I am particularly glad for all this because I am consistently supporting the idea of the relevance of HK with climate for years, and I had strong difficulties in doing that.
For instance, had Gavin written this piece three years ago, he would help the scientific community and RC to better understand the importance of Cohn and Lins (2005), discussed in http://www.realclimate.org/index.php/archives/2005/12/naturally-trendy, and would help reach in consensus with Rasmus et al. in the discussion in this thread. In addition he would help avoid eristic discussions later in Real Climate in http://www.realclimate.org/index.php/archives/2006/05/how-red-are-my-proxies/.
In addition, had Gavin written this piece a couple of years ago, and given the influence of Real Climate in climatologists, I am sure that I and my colleague Alberto had no difficulty in publishing our paper:
(as I also mentioned in #37), so that we would have devoted our time in the advancement of our research rather than struggling for months to publish a single paper. For transparency, all prehistory of this paper, which shows our struggling, is available in http://www.itia.ntua.gr/en/docinfo/781 (click on “prehistory…”). By the way I strongly recommend reading this paper to the RC new comers in HK, as well as this one:
A more comprehensive list of my HK papers is given in http://www.itia.ntua.gr/en/documents/?authors=koutsoyiannis&tags=Hurst. These will help avoid misinterpretations of the HK behaviour, such as this one in GS-RC:
For, soil moisture imposes Markov-type dependence and not HK-type, which in fact is imposed in hydrological processes by climate.
Also, they would help in avoiding statements like:
For, good statistical models reflect/make physics, as the statistical thermophysics paradigm has taught us.
4. The fourth reason that makes me satisfied is that most of the specific issues raised in GS-RC are already replied in Kea08. Below I give a few examples:
4a. From GS-RC:
From Kea08:
4b. From GS-RC:
From Kea08:
4c. From GS-RC:
From Kea08:
4d. From GS-RC:
From Kea08:
and
4e. From GS-RC:
From Kea08:
4f. From GS-RC:
From Kea08:
I think I must stop here replying GS-RC comments; my comment became already too long and I apologize for this.
5. The reason that makes me not satisfied is the way Gavin refers to the reviewers of the paper. First, he does not mention at all the “formal” reviewers, Zbyszek Kundzewicz and Roger Pielke Sr. Second, he tries to depreciate the “informal” reviewers, Willie Soon, Pat Frank and Larry Gould (as scientists, but without referring to their works). For this reason, I feel that I have to repeat here my special thanks to these colleagues for their reviews and my deep appreciation of their works.
bender, RM,
Regarding Hurst/Holder exponents I have a question. This talk about constant Hurst is that inter or intra time series?
About 10 years ago my colleagues and I developed synthetic terrains using fBm texturing of measured measured material types for overlaying onto faceted topo maps. We used a variety of techniques and eventually got results that are still used today. One of the things we learned is that Holder is a pretty finicky beasty to estimate. We performed a variety of experiments generating 1 and 2-D fBm surfaces with known fractal dimension, then estimating Holder to get a feel for how things behaved. The estimators we used were sensitive to sampling frequency and would always breakdown at both ends of the resolution spectrum. That is, there was always a sweet spot in terms of range of scales. Above and below that sweet spot the estimators would start to diverge. So, from my experience, regardless of the time series, Holder/Hurst estimation is going to be “band limited”
#24
Where has this been discussed? Especially pertinent given Gavin clearly accepts the LTP/LRD concept and the use of the Hurst coeffs. Who is it dared disagree with GS by omitting this paragraph from AR4? And wWill it be put back into AR5?
Gavin Schmidt says:
Clearly he has already done the calculations, because he reports the results right here. Curious, though, that he waited until Kea08 was published before reporting his results, which were, quote: “mostly something similar”. Any chance of clarifying that result, Dr. S?
Doesn’t support doesn’t mean is wrong.
Kenneth Fritsch (#151),
Near the equator the heating is dominant and the reduced system that describes the fluid motion is very simple. The reduced system is
u_t + u u_x + v u_y + H u_z + p_x / rho_0 – f v = 0
v_t + u v_x + v v_y + H v_z + p_y / rho_0 + f u = 0
u_x + v_y = – H_z + H (g rho_0 /p_0)
where (u,v) is the horizontal velocity, p is the pressure, f is the Coriolis parameter, rho_0 and p_0 are the horizontal means of the density and pressure, and H is the total heating. Note that the vertical component of velocity w has been replaced by H because of the necessary balance between it and the total heating (Browning and Kreiss, 2002).
Thus near the equator any errors in the total heating lead directly to errors in the fluid motion, i.e. inaccurate climate model parameterizations
near the equator immediately lead to inaccurate models. In large-scale midlatitude flows, the heating in not dominate and geostrophic balance is valid. That is why NWP models can stay on course for a day or so, but they still must be updated every 6-12 hours with new obs or they will go off course because of inaccurate parameterizations. As soon as one proceeds to smaller scales in the midlatitudes, the above reduced system holds and that is why there has been so many problems with mesoscale models providing any accurate forecasts.
Jerry
bender,
I find it funny that gavin notes taminos post on Hurst.
Who do you think asked Tamino to do that post?
Hehe.
At some point one wizard said Hurst only applied to hydrology and not temperature….
because in hydrology they had resesvoirs.
I looked at the ocean. thought about heat storage, and chuckled.
All,
One can form the time dependent equation for the vertical component
of vorticity (- u_y + v_x) from the first two equations of the reduced system and the horizontal divergence (u_x + v_y) is given by the third equation as a known function of the total heating. These two equations then uncouple from the pressure and are sufficient to determine the horizontal wind. The pressure can be determined by differentiating the third equation w.r.t. t (similar to the incompressible NS equations) resulting in a diagnostic elliptic equation for the pressure.
Very easy to understand the importance of the total heating (or errors in such) on the solution near the equator or for smaller scales of motion in the midlatitudes. NWP forecasts and climate models have always done poorly in these areas and this simple system explains why that is the case.
It is worth spending some time to understand the system.
I will be happy to answer any questions or explain in additional detail
if desired. Once this system is understood, many issues will become more transparent, i.e. there is less wiggle room for RC.
Jerry
re: 152
Dr. K,
Thank you for your comment. It is much appreciated.
steven,
I remember ocean mentioned in some 1/f text (my bolds) ,
Anderson & Mandell, Fractal Time and the Foundations of Consciousness
Gerald Browning,
Am I correct in assuming that this implies that the behavior of the temperature and humidity profiles of the tropical troposphere is in fact a critical indicator of model performance or lack thereof?
Hope this isn’t too far off-topic.
William Gray also raised the point about how the models achieve hydrostatic balance in his presentation that was so roundly dissed by Judith Curry, among others. See his fig. 11 and 12 here.
DeWitt Payne (#162),
Yes. And note that any errors in the total heating profiles near the equator can propagate laterally into higher latitudes.
Jerry
Gavin Schmidt is right to argue that it would be better to use GCM ensembles than individual runs when comparing predictions to observations. DrK, is it possible for you to do this? Perhaps you and DrS can work this out together in a joint paper?
bender, #165
I would be glad to work together Dr. S. for a joint paper as a result of a joint experiment, provided that the experiment is well defined (including a rigorous definition on an ensemble), jointly agreed and fully transparent (everything made available on the internet) and that we find some funds. (As noted in the paper, so far this research has not been funded — even the publication cost for open access etc. was covered by the authors — but we cannot continue this for long). I trust my colleagues would be glad too to contribute in such an experiment.
But I doubt if Dr. S. could accept a joint research on this issue, because the result is again obvious and from his posting it seems that he knows the obvious things (see also my comment above in #152.2) and perhaps he dislikes them. Do you really believe that using ensembles, the models would perform any better with respect to reality/history? Please take a look at IPCC 2007, Figure SPM.4, panel entitled “Global”, and focus on two periods, 1940-50 and 1900-10. Does any member of the ensemble (more precisely, any member of the 90% of simulations that are plotted, as confidence bands, in the figure) capture the globally falling trend in 1940-50? And why does the figure exclude the period 1900-10 (even though model outputs include it)? As we can see in http://www.cru.uea.ac.uk/cru/info/warming/, the trend in 1900-10 was falling again (not to mention that the latter period of global cooling was even longer, as it started before 1880. If we move from the global scale to finer spatial scales, the frequency of having falling trends, their length and magnitude, all increase in reality, but I doubt if they increase in models. So I do not think that ensemble outputs of climate models would perform better at any local scale than at the global scale. If there are such departures (in the sign of trends) at the global scale in PCC 2007 Figure SPM.4, how can climate model ensembles capture the bigger local falling trends?
#116
No, not substantially. (And that’s why I didn’t raise this objection in my review.) But it is worth a look. If only to satisfy the critic.
RE 166. Dr. K.
As you note the GCMs categorically miss cast these cooling trends.
( there is a thread here on ModelE where I pointed this out, Basil noted it as well I believe) Now, they do tend to get the cooling trends right when the cause is volcanoes ( no great feat) But their inability to get “natural” cooling right, could indicate a missing negative forcing or a failure to represent certain processes.
Anyway.
My second favorite Hurst
http://www.hurst-shifters.com/hurst-shifter/default.html
#168 mosh
G. Schmidt would likely argue that some small percentage of the runs actually do show cooling. Recall, for example – this is how he “refuted” the tropical troposheric data: temporary cooling is not inconsistent with long-term warming [paraphrase].
9 simulations out of 55 model runs in IPCC AR4 have negative trends over the 8y period 2000-2008:
http://www.realclimate.org/index.php/archives/2008/05/what-the-ipcc-models-really-say/
9/55 = 16%
Is 9 enough? Should it be 19? Good question.
bender, you say:
Do you have any citation for this claim? And do you have any theoretical justification for this claim?
The models are tuned to the past. Therefore, we are not looking at random realizations. As a result, the models as a group will tend to cluster around the historical record, with an average outperforming a single model. What I’ve never seen is any formal argument that they will do the same for an out-of-sample study. Do you have one?
I just did an analysis of the GISS Model E hindcast (1880-2000). It did not perform as well as a straight line in hindcasting the GMST. Since an average of models with “random” errors will approximate a straight line better than a single model, we can say that averaging improves the results … but so what? Substituting a straight line improves the results as well, but I don’t see that as a recommended procedure.
Generally, the models have a greater variance in their results than do the observations. Because of this, any operation that reduces the variance will reduce the RMS error w.r.t. the observations. But again, so what? As an example, consider a 6-sided die with the numbers 4,5,6,7,8,9. We roll a random set of fifty numbers, these are “observations”.
Now, suppose we “model” this with an “ensemble” of ten 12-sided dice, each with the numbers 1-12 on it. We roll each of the ten dice fifty times, these are our “model runs”. Two questions:
1) Which will have a smaller RMS error w.r.t. the “observations”: a single “model” run, or the average of all of the runs?
2) Does that mean anything?
You see, if your (and Gavin’s) theory were correct, predicting the stock market would be easy. We’d just take the average of all of the failed stock market prediction programs (there’s hundreds of failed programs out there) and average them, and make millions of dollars … what’s wrong with this picture?
w.
PS – bear in mind that the results of any and all of these models can be replicated (minus weather “noise”) by a simple model (MAGICC) which uses only four parameters. This means that we are not looking at a universe of models of the earth, but only a very small subset consisting of a single type of models.
And within that type of model, we are not using all of the possible realizations, only those few that correspond to the possibilities in the range of the four parameters actually used. These are the forcing from a doubling of CO2 (3.09 to 4.06 w/m2 are the values actually used in the FAR), the climate sensitivity (1.9 to 5.9°C/doubling), the ocean diffusivity (0.8 to 4.6 cm^2/s) and the land/ocean temperature ratio (1.1 to 1.7).
Next, within the parameters, we further restrict the choices to those that give some kind of reasonable match to the historical model.
Finally, we know that of these four parameters, the climate sensitivity is set by the choice of forcings used in the model. Once the overall size of the forcings are selected (which of course includes the forcing assumed for a doubling of CO2) and the climate sensitivity is thus set, we are left with only two parameters to distinguish the models … which is the same number of parameters that Lucia uses in her lovely model “Lumpy”. Which means that we are dealing with a very reduced set of models. This makes the “averaging” of a group of model results very far from a random sample of possible model outputs.
So … have any out-of-sample studies of this question been done?
I ask in part because
a) I don’t know of any other field of science where a straight unweighted average of different models is used. Could well be one, but I don’t know of one. I find there’s Bayesian Model Averaging, but that’s done based on reliability of each model.
And I find the use of a Kalman Filter with a model ensemble, which also makes sense. But I find nothing about “let’s average 10 inaccurate models to get the right answer”.
b) I know of no theoretical reason that the average of a bunch of bad models would outperform a bad single model, and I can think of several reasons why they would not.
It’s an opinion, not a claim. It is based on an understanding of how these models work. A single run has fixed initial condition. If the initial condition does not equal actual initial conditions then the subsequent deviation away from observations is expected to be large. No suprise. If you can’t fix the initial condition to something that is appropriate then your only alternative is to vary them, and generate an ensemble.
I think it’s a good idea – for a suitably large area (not a point-wise weather station).
I would prefer to see ensembles generated from fixed inital conditions, but that may not be possible, as it is not possible to know with perfect accuracy the distribution of heat in every grid cell around the planet.
But the fact remains: these models seem to fail to generate enough of the right kind of Hurst-like internal LTP noise. Gavin Schmidt dodges this issue every single chance he has to address it squarely. [My prediction is that he will start to promote that viewpoint vociferously should temperatures continue to flatline through 2010-12.]
bender, thanks for your response. I agree w.r.t. long term persistence, the models don’t duplicate it, among many other equally important failings.
I fear we are dealing with problems of definitions here. First, you say:
To me, an “ensemble” is a group of different models running the same set of forcings. Three or twelve runs from the same model are a series of model runs. I was under the impression we were talking about ensembles, not re-runs of the same model with different initial conditions.
Finally, you say:
To me, that is very different from saying
To me, one is an opinion, the other is a claim requiring some kind of backup.
Like I said, differing definitions.
All the best to you,
w.
That is the unfortunate legacy of the way IPCC is using what I will call pseudo-ensembles, and calling them “ensembles”. When I use the term I use it in its proper, statistical sense. Using a single model, and perturbing the inputs (either at the start or during simulation) generates a true ensemble.
While maybe not relevant, I had a lot of experience applying Monte Carlo models to financial projections of mining projects in the 1970s, 80s and into the 90s. We would identify the 6 most important independent variables, and attribute probability distributions to each of those according either to historical detail, or perhaps engineering style limits (trumpet curve). We would run 1000 runs (using a great progam called @risk in the later years) to get a distribution of the outcome.
The Capital Asset Pricing Model (CAPM) has methods for calculating appropriate discount using beta, a measure of stock price volatility relative to the “market” as a whole. The CAPM discount rate was supposed to be all you would need to arrive at a reliable valuation.
The big issue in mining project assessments is that the metal price (and exchange rates) is highly volatile over the (say) 20 year project life, often being 50% or more about the long term mean.
In 1989 I did a valuation of a large mining project using CAPM and got a “value” of $1100m. This project was in an industrial commodity with stable pricing. At about the same time I did a valuation of a smaller coal project and got a “value” of $33m. According to CAPM, these two valuations are equivalently reliable. The larger one had used a discount rate of 8% and the smaller one a discount rate of 12%, both arrived at by beta analysis.
The Monte Carlo outcomes though were VERY interesting. The larger project had a 1SD of $55m, ie about 5%. The smaller project had a 1SD of $75m. The kurtosis of the larger project study was tightly clustered around the median value giving a high reliability rating (and thus financeability) to the larger project. The kurtosis of the smaller project study was very flat. The 68% range of 1SD was from -$42m up to $108m.
Clearly, a purchaser could afford to purchase the larger project at a price up to the valuation and secure finance for it (relying on option elements to deliver ‘super’ returns, but there is no way that a purchaser could afford to pay more than a few million for the option value in the coal project. But hang on, didn’t CAPM say that the project is ‘worth’ $33m? And after Monte Carlo it is evident that any astute player would not pay more than (say) $5m? So how valuable is CAPM in this instance.
BTW, the leading Corporate Finance textbook at the time discussed Monte Carlo, and concluded that it was without merit!
I won’t go into the reasons these outcomes eventuated (we do understand them, and what to do about them). The big lesson we learned is that the Monte Carlo method gives a very good measure of the reliability of the valuation arrived at by CAPM. In the case of the larger project, the valuation was highly reliable. In the case of the smaller project, the valuation was of very low reliability again.
The reason for delving into this seemingly unrelated topic is that I wonder if the climate scientists run Monte Carlo simulations on their models, and so establish the 1SD of their projections. I think that we can be pretty confident that if done properly, the 1 SD would be pretty wide and kurtosis flat, which can be expressed as “pretty much equal probability of any outccome”. Or to put it another way – not reliable.
bender, thanks for the clarification. You say:
In that context, what you say makes more sense.
However, in climate science, the IPCC usage is the common usage. For example, you used it when you refer to “GCM emsembles” in your statement for which I asked for a citation:
“Gavin Schmidt is right to argue that it would be better to use GCM ensembles …”
… surely you are using the IPCC meaning there, and Gavin is using the IPCC meaning, no? Because Gavin routinely uses “ensembles” to mean “multi-model ensembles”, and a “GCM ensemble” must mean an ensemble of GCMs, no?
In any case, given that you and Gavin were talking about ensembles of runs from a single GCM, rather than a GCM ensemble, I would agree, but that may not be meaningful. An average of an ensemble of runs from one GCM using different starting points should outperform a single run … but even there, it may be real but not meaningful.
This question is of interest to me because I just took a look at the GISS EH model’s historical runs. Here’s what they look like:
There were five runs, and the R^2 of those runs w.r.t. HadCRUT3 is:
R0, 0.43
R1, 0.30
R2, 0.44
R3, 0.41
R4, 0.44
Avg Model, 0.50
Now, the average does better than any of the individual runs … but what does that mean? It becomes clearer when we see that the R^2 of a straight line w.r.t. HadCRUT3 does better than either the average or any of the models.
So the question is … does the average do better because it is actually a better representation of reality, or does the average do better because any average will generally be closer to a straight line than its component parts?
Finally, there is the question of autocorrelation. If we were to average say 100,000 runs of a single model, we will get a very highly autocorrelated result. While that result may have a better correlation to HadCRUT3, the correllation may not be statistically significant.
However, your point is well taken, it would be good to do a multi-run comparison with the Koutsoyiannis data, just to get it out of the way.
w.
A single run has more noise than a set of runs. More variance. The more linear (lower variance) the average output in two models, the higher the r2, purely as a result of increased autocorrelation. The r2 between two models, where each is predicting a linear trend, is meaningless. Especially where you expect it.
Note that a true ensemble has NO noise in it. It is all deterministic response to external forcings. These ensembles only exist in theory. In practice you need many, many simulations to approximate the ensemble mean – and that is ASSUMING the “mean” actually exists! (An average is not a mean. If you have to chuck out 10% of the runs where the model crashes or yields “unphysical” solutions, then you know what I mean.)
Suppose you have two stochastic models that predict positive warming in response to increasing GHGs. The r2 between the two ensembles (which are now determinstic), one for model A and one for model B, is, by definition, 1.
Meaningless.
Bender # 172 wrote
Yes , right .
Here is what T.Tao has to say to EXACTLY this issue in the much better specified problem of N-S regularity .
When I say “better specified” that means that we understand the question and are able to formulate it mathematically without ambiguity (on top T.Tao obviously understands very precisely what he is talking about)
Often I regret that the probably most brilliant brain on this world , G.Perelman is not interested to cast an eye on the climate pseudo-science , he would wipe out the floor with the whole bunch of Schmidts and Hansens faster than they could say “pwned” .
The above quotes are an extract of T.Tao’s recommendations in order to make progress on the N-S problem .
The whole text is on http://terrytao.wordpress.com/2007/03/18/why-global-regularity-for-navier-stokes-is-hard/ and I have already warmly recommended its lecture .
Beside its high scientific content , it is quite relaxing to read something intelligent and well written especially after having waded through the Nacht und Nebel (in german “night and fog”) of places like RC .
I have now read this paper, and skimmed again the comments in this thread. The impression I was left with was most closely echoed by John Lang in #40 and Willis Eschenbach in #128. This is that, though K. seems to establish that the models are rubbish on a local scale (over a period of 30 or more years), they might be OK on a global scale. Others have said that K has not actually claimed that the models are poor globally, only that they have their work cut out given the local performance.
I would have to say that I do not find this point well treated in K’s Introduction nor Concluding remarks, where a quick read seems to rubbish the GCMs completely.
A second point, and I note that this paper is open for discussion until 20090201, is that it looks like cherry picking to me to present approximately the worst site, Albany, in the figures and tables. I suggest it would be better to present a better one, and say how poor even that one is. To that end I found Figure 8 (showing local climate changes versus model spread) to be the most useful, and telling, part of the whole paper.
Rich.
Re #179
And yet despite those problems it has been possible for some time to use CFD models of the N-S equations to design complete aircraft and consequently greatly reduce the necessity for the use of very large wind tunnels (and the associated expense). In other words these models have now become a virtual wind tunnel, no major aircraft manufacturer designs an aircraft without substantial input from CFD, the difference being that in the 80’s we used main-frames Crays and the like, then minis and now it can done on laptops. One of my friends who is the leading light in this area stunned everyone when in one of his presentations at a conference some years back he ran a wing optimization on his PC which was completed during his lecture.
#181 Surely you are not suggesting that earth’s climate is a lot like the tip of a wing?
Re #182
In that models are required to solve the N-S equations in both cases and in #179 we saw a discussion of what was needed ‘to make progress on the N-S problem’. And yet even without that progress the models allow us to design a complete aircraft and model the flow around it in complicated flight situations. I was not referring to a wing tip but the whole aircraft.
Phil,
CFD is fine if you have wind tunnel to tune your model. Don’t tell me that aeronautical engineers design a plane without physical testing. Less testing, which is more expensive than computer time, but not no testing. Ferrari and McLaren haven’t dismantled their wind tunnels even though the both have large CFD programs. In fact, someone just recently built a new full scale moving floor tunnel to test race cars. CFD for planes and cars is not in the same league with the complexity of an AOGCM. You only have one fluid, air. There are no external temperature and pressure gradients, only those associated with air flow over the surface, etc.
Phil, as you point out, all scientific and engineering disciplines use models. The difference is in how the model results are treated.
In climate science, people come out all the time saying their new you-beaut computer model has provided the “smoking gun” that proves that AGM is real. Or they say their model has found the “fingerprint” of AGW, in a clear claim of unshakeable identification. In other words, in the climate science field computer model results are treated as evidence.
In other engineering and scientific fields, this is absolutely not the case. Model results are treated as guides, as indications, as insights, as probes into unknown realms, as learning tools … but not as evidence. Nobody would be so foolish as to claim that their computer model is the “smoking gun” that establishes beyond doubt that cold fusion is real and we should invest billions of dollars in it. People would laugh that person out of the physics fraternity. No one is dumb enough to claim that their CFD model is the “smoking gun” that proves that their new airliner wing is better than all the rest, so no testing is required.
Those things can only be established in the real world, never in computerspace. That’s why, even with all of the computer horsepower we have available to us, we still have proving grounds, and R&D labs, and test pilots, and “proof-of-concept” experiments, and prototype airplanes. To date, in any case, all computers can do is speed up the calculations. They cannot make sure that the assumptions are correct, or that the variables are realistic, or that the parameters are correctly adjusted, or even that the units are right (see the Mars probe crash …). All they can do is compute the results of the understandings of the programmers. If those are wrong, so is the computer result, and there’s no way to tell in advance whether they are wrong or not.
This is all just common sense. Suppose a man comes in to say “I’ve discovered a new sub-atomic particle”. When you asked what experiments he performed, he tells you “Oh, I don’t need any confirmation, my wonderful new computer model predicts it!” Your response would most likely be, “Riiiiight … interesting … tell you what, why don’t you come back when you have experimental results that confirm your model”.
However, with climate models, it seems that common sense goes out the window. A guy comes in and says “My model shows the earth will be overheating in a hundred years, it proves we should spend billions on the problem right now”. And people go “Oooooo, he did it on a computer, it must be right” and start inventing carbon taxes and tradable carbon credits … I gotta confess, how people can simultaneously believe that computer models are inaccurate and can’t be trusted to forecast the weather as far as next week, and at the same time believe that computer models can be trusted to forecast the climate for centuries, is an eternal mystery to me …
Finally, modeling an airplane wing is much, much, much simpler than modeling the climate for three huge reasons: equilibrium, knowledge of variables and conditions, and complexity.
1) Equilibrium. Generally, wing modeling is a problem involving a steady state of equilibrium flow. The wind is at a certain unchanging speed, the wing is at a certain angle, the wing has a fixed shape that does not change, the air is at a certain fixed density and temperature.
Compare this stable situation with the earth, with changing winds, variable angles, clouds folding and unfolding, differing atmosphere densities, ever-changing chemical interactions, wide-ranging temperatures, and the like. All of these are varying over time scales ranging from milliseconds to millennia, and at spatial scales from the microscopic to planet-wide.
2) Known conditions. When modeling a wing, all of the conditions are known exactly, and to a high degree of accuracy. We know the exact shape of the wing, the exact density of the air, the exact velocity of the plane, and the like. Compare and contrast that with the earth, where many of those things are either unknown, or in certain cases, may be unknowable. While we can, for example, measure what goes on inside a single thunderstorm at a single time, we will likely never have simultaneous information on what is happening inside all of the thunderstorms.
In addition, in modeling an airplane wing, we have a very good grasp on exactly what the variables are – density, temperature, speed, smoothness of the wing and the like. In contrast, with the climate we discover new forcings every year. So we not only don’t know the values for many of the variables, we don’t even know all of the variables. It was recently discovered, for example, that the forest canopy stays at about the same temperature from the tropics to the poles … what effect does that have on climate? We don’t even know the sign of some of the variables, much less their values.
3) Complexity. In a wing model, you only really have to model one thing – the air as it flows. Climate, on the other hand, involves modeling at least six major subsystems (ocean, atmosphere, lithosphere, biosphere, cryosphere, electromagnetosphere). Each of these systems has its own forcings, resonances, and feedbacks, both internal and external. So in addition to modeling the subsystems themselves, we have to model the interactions between the systems.
For example, where in the “model a wing tip” problem is there anything like the El Nino? Where is there anything like the mutual feedback between the ocean, the polar ice cap, the clouds, and the atmosphere? Where is there anything that even begins to approximate the computational difficulty of modeling the vagaries of atmospheric water at its triple point temperature?
In short, modeling an airplane wing is at least several, and likely many, orders of magnitude simpler than modeling the climate. Because of this, N-S approximations which are perfectly adequate for modeling an airplane wing fail miserably when confronted with the ugly reality of climate. To model the climate in this manner requires a solution, or at a minimum, much much better approximations, of the N-S equations and, as T. Tao has pointed out, we don’t have the know-how yet to do that.
All the best,
w.
PS – There is another difference between the climate models, and other computer models used in “industrial strength” or “mission-critical” situations. This is V&V and SQA … but that’s a whole other topic.
Re #184
The wind tunnels aren’t used to tune the models, they are used for validation, most of the work is done with CFD. The aim (which is not far away) is to do away with real wind tunnels.
A key difference with cars is that you can do full scale testing, and if you don’t have a moving floor you’re wasting your time. Not so easy with a Boeing 747 where you have to use scaling. The heavy lifting in the design phase is by CFD, wind tunnels are just a final validation.
Don’t take my post out of context, I was responding to a post that was quoting statements about what needed to be done to solve ‘the N-S problem’ with the implication that this imposed significant limitations on the use of models. I was pointing out that even without those problems being solved the present state of the art of modelling allowed extremely accurate simulations to be done. If you want to see what’s being done check out Tony Jameson’s work:CFD
By the way in the slide towards the end showing how Grumman used to design in the 60’s guess who the guy at the back with his feet on the desk is supposed to be!
Also the aircraft design problem is far from the most complex flow for which CFD is used successfully, Fluent’s codes for example are used in combustion flows involving multiphase flow, temperature variation, pressure variation, variable geometry etc.
Re #185
Willis you miss the point which is in response to the use of Tao’s paper on N-S equations from a mathematical perspective (he freely admits that CFD is ‘beyond his expertise’). His paper was not limited to climate flows but was completely general. Those mathematical points shouldn’t be construed as some fundamental limitation on our abilities to treat the equations in models (although it seemed that the poster wanted us to think that).
Your points are fine but they don’t address the point, by the way it seems that you’re unaware of the degree to which the CFD designs are relied on without further testing, e.g.:
“Design decisions were made from CFD because powered nacelle wind
tunnel testing could not be performed in time”
Mark Goldhammer, Manager, 777 Aerodynamics Development
Phil,
Have you looked at the Exponential Growth threads? Gerald Browning and lucia among others, who know far more about the subject than I, had much to say about solving N-S problems on small scale vs. the much larger scale of a planetary atmosphere.
RE: 186
So how would you rate the validation process for a man rated vehicle vs GCM’s. What about the quality of the data collection, comparison of model output with test results, unit testing, regression testing, blah, blah, blah. You know they still actually flight test the planes, modify designs, update the code, etc. all before the first paying passenger sets foot on the first 787. Mostly, they use sims because its cheaper to use sims for a variety of reasons.
snip
Steve: please stop editorializing on what modelers are asking us “to do”
#180, Rich
Take a look at Kerr’s article of today’s Science (Climate Change Hot Spots Mapped Across the United States) to understand why it important to know that the models are poor (or rubbish, as you say) on a local scale. For, geographically distributed model results are everyday used (with or without downncaling) as if they were credible (as in this case, characterized in Science as ‘the beginning of a possible new avenue … towards a clearer picture of where regional climate change matters’).
Now on the global scale, since there is not (and cannot be) any proof by deduction that the models perform adequately, let me turn to induction and say that knowing the poor performance on local scales increases the probability of poor performance on the global scale.
Up the road from where I live is the small town of Moses Lake, Washington, which has an airport with a very substantial runway where Boeing spends a lot of time putting their new aircraft through real-world operational testing.
Wind tunnels or no wind tunnels, no paying passenger gets on a Boeing passenger airplane without its design having been rigorously exercised and tested in a representative real-world operational setting.
It has been my observation of the kinds of engineers and computer scientists who are now engaged in creating and maintaining these GCM models that the whole effort seems to be a mere abstraction to them, not unlike the effort that would go into creating some kind of large-scale video game — Grand Theft Climate, if you will.
In contrast, Boeing’s engineers, scientists, and Boeing’s management all know that regardless of what decisions they make in managing the balance between computer modeling and wind tunnel testing, the airplane will spend a lot of time at Moses Lake proving out whether or not it is performing to expectations; and therefore if the computer models they created did the job expected of them and had value in more economically producing a safe and efficient airplane.
To draw another parallel here, in contrast with Boeing’s engineers and computer scientists — and again from my personal observation — there seems to be little interest among most of the climate modeling engineers and the climate modeling computer scientists as to what actually is physically happening up there in the sky.
In other words, do they care much to ask themselves if there really is some tight connection between how their computer models operate and the actual physical processes operative in nature which they are tasked with modeling? My observation is no, it’s all a big video game to them, with a paycheck at the end as their reward.
Steve: It is unhelpful and pointless to speculate adversely on motives.
Willis, I was a bit suprised in your point #2 of comment 185 that you did not point out the qualities of the known boundaries in a wind tunnel and point out how that simplifies, by itself, the problem. Especially compared to the changing, and somewhat flexible boundaries of our planet. I am sure GS, breathed a sigh of relief. IIRC, the design of a good wind tunnel was similar in cost and complexity of the design of the object in the wind tunnel.
Great effort was required to control variables such that the data and conclusions would be useful.
I find one part of this discussion particularly relevant to DrK’s work. Using what we know of a successful effort to parameterize an intractable problem, doesn’t the historical approach made by the modellers indicate that DrK could restate their probable failure with more certainty? The history of known working (useful) models was from small advancements and small victories in wind tunnel design and computer model design until a unit was proven. However, with AGCM’s we have the opposite paradigm. They have started with large envelopes and have reduced it to a smaller scale without verification. The smaller scale has been shown not to be correct, Based on past successfull developments, the failure on small scales and lack of validation on large scales would preclude the large scales could possible be correct for N-S if one determining parameter could be shown to be wrong. i.e. the hyperviscous layer that is used which precludes that the mass energy transfers were modelled correctly.
Scott-in-WA, methinks you denigrate their motives WAY too much. I believe they really do care about the planet. Note the tragedy of Geoff S’s friend in another thread. People do not commit suicide over frivolous games nor paychecks. However, the anguish of honestly believing our planet is dying, and people are not “fixing” it, could be crazy-making as some would say.
Having so much false confidence in our data and models that one is fully committed to the outcome — willing to make personal and global life/death decisions — is horrifying to me. We are nowhere close to such confidence levels.
Scott-in-Wa, #191 is very well said.
For what it’s worth, back on a K-type topic, I’ve experimented a little with confidence intervals on trends. initially trying to replicate results of Cohn and Lins (which I meant to post on), because I thought that they were interesting. But the general idea was to to do the same sort of likelihood interval calculation under different error models, including LTP modeled through fracdiff in R.
The results actually give a little food for both sides. What happens (and this is just analyzing the trend) is that the uncertainty intervals to the trend spread out a lot under LTP so that the case of no trend is not excluded. However it also spreads out at the top, so that even Hansen’s worst scenario isn’t excluded either.
I’m issuing a clarification notice: any post that contains ANY complaining or moaning about what climate modelers asking “us to do” will be deleted in its entirety. Similarly any invidious comparison of climate models to airline models or quality standards or that sort of thing. IT’s not that I don’t think that there is much to be said, it’s just that the point’s been made ad nauseam; I’m sick of reading these complaints; and I’m doing this for editorial reasons.
Re #195
This is very true, and a point I’ve tried to make at Lucia’s place – for example, LTP would result in the IPCC projections no longer being falsified because the CIs would grow. This would make the AGW side happier. But then the 20th century warming would be insignificant, making the sceptics happier.
I haven’t done the calcs on Hansen’s scenarios, and can believe this to be the case (although they must be marginal – didn’t Cohn and Lins get 7% p-value for the 20th century trend?) one of the points being made is that it might be possible that Hansen’s A scenario could occur from natural variability alone. This is bought out in Cohn and Lins 2005:
Of course, if there is a 6 deg C / doubling CO2 hiding under LTP, then we still have a problem, and furthermore, that problem is far more difficult to detect. It is essential that we address this uncertainty head on though, and not sweep it under the carpet.
Re #190
But doesn’t tell us anything about the usefulness of the global scale, you’re basically guessing.
Consider this detail of an image, it looks a rather poor representation, however when we look at the full image we can see that it did a good job.
#195, #197
Yes, LTP assumption would increase ambiguity about how to interpret 20th c. temp. rise and 21st c. flatline.
But it would accomplish much more than that. It would put the infamous parameterization exercise (figuring out how much instrumental global temp change is due to solar, volcanoes, aerosols, GHGs, etc.) right back on the table … where it belongs. And if half the variation attributed to determinsitic forcings is actually stochastic (LTP), then the GHG coefficent may drop by half. It is very unlikely to rise. [Alarm bells /off]
Summary: This is not just about whether observed temperature trends exceed model confidence intervals. It is about causal attribution, the magnitude of the various forcings, which were historically “estimated” by trial and error, and are therefore likely an overfit.
#198
The question is whether DrK’s “proof by induction” is legitimate when you are talking about extrapolating from one grid cell to all grid cells. If errors cancel as you scale, then the inductive step is flawed logic. This is an open question in climatology, is it not?
Of course, there are many who disagree. I would ask them to prove their case. If it is “settled science” that local errors cancel as you scale from point to globe, I would like to see the proof. I understand the principle. No need for analogies. I want the mathematical proof.
#198, Phil.:
Do you think you will get a realistic image of a lion, if each pixel produced by your model is irrelevant with the corresponding one of the lion?
#200, bender:
Did I say “proof by induction”? I only mentioned increased probability.
If… (Can you prove that errors cancel? – in a validation context?)
PS. A good reading about deduction and induction (and not only):
No. One would assume that this has been proven beyond a doubt in the mainstream literature, given how often it is stridently asserted that “weather is chaotic, but climate is not” and “GCMs don’t work well locally, but work very well globally”.
Is this fact, or belief?
Well, let us assume that it is a fact that locally the GCM is wrong, but on a global scale it is (very) accurate. I would say, keep the data but please chuck the model. The model cannot be right unless, we live in a magic world.
No one disputes that. What is disputed is whether they are “good enough”.
And on that topic, Rind (2008) suggests that if you can’t predict high-latitude and low-latitude sensitivity, you can’t predict (sorry, PROJECT) much.
Interesting read.
bender 203: Dessai, L and Hulme, Limited Sensitivity Analysis of Regional Climate Change Probabilities for the 21st Century shows regional skill scores are not consistent trends across regions, seasons, or variables (Figure 3).
In my recent post, http://landshape.org/enm/temperature-index-drought/ I look at the value of the strategy of regionalizing to improve accuracy and find no consistent performance in regional models at predicting drought across 1900-1949 and 1950-98, hence no value in trying to improve accuracy by selecting the best models by region — the cornerstone of Australian regional climate prediction.
Comments welcome
THE MIND PROJECTION FALLACY
It is very difficult to get this point across to those who think that in doing probability calculations their equations are describing the real world. But that is claiming something that one could never know to be true; we call it the Mind Projection Fallacy. The analogy is to a movie projector, whereby things that exist only as marks on a tiny strip of film appear to be real objects moving across a large screen. Similarly, we are all under an ego{driven temptation to project our private thoughts out onto the real world, by supposing that the creations of one’s own imagination are real properties of Nature, or that one’s own ignorance signifies some kind of indecision on the part of Nature
Jaynes on probability theory as noted by DK ABOVE
The two dozen of current CGMs MUST do well what they are intended to do, that is to hindcast or project a monotonic rise in global surface temperature, as it happened (more or less) in the last decades of the 20th century.
That’s a fact.
Models can’t do well what they are not intendent to do, that is to hindcast a non monotonic behaviour of GST, as it happened it the middle of the 20th century or is happening in this decade.
But, much more important, models are not intended to predict well all the remaining physical variables of the weather-climate system that are all local in their essence: 3D-temperature(atmosphere and ocean), precipitation, 3D-wind (and ocean currents), 3D-radiance, 3D-cloudness, 3D-moisture content, 3D-aerosol concentration and transport, etc, etc, etc…
So I think is useless to discuss if models are good in the global scale when it is a fact that they are. But only for the global temperature and in the right years!
Current CGMs are not a tool to predict the future state of climate (both regional and global); they are an over-complicated tool to predict a monotonic rise in global temperature, nothing more.
Demetris #190
Many thanks for responding to my #180. (Especially since to me responses to my CA postings seem relatively rare 😦 ).
I agree with all you say in #190, but I still think that those points could have been made with greater clarity in the Concluding Remarks of your paper. Still – I shall use them in arguments with my friends!
Rich.
Since Rich is seeking feedback …
1. This is a kind of cherry-picking that is done all the time in the literature. It is done for a number of resaons (space limitation, demonstrative purposes), all reasonable. Best to identify explicitly in the Figure caption when a particularly extreme result is being expounded upon for demonstrative purposes. I will agree with that.
2. Cherrypicking is discussed a lot at CA. This case is not at all in the same league as selectively using or archiving data. Not even close. One good strategy to keep things honest is to provide similar figures for all cases in the SI.
Re #202
I don’t know if this is what you had in mind, I’ve added 56% uniform noise?
Here’s a detail from a similar region to last time.
And here’s the full noisy image.
.
Still looks good to me.
Edit:direct images shown
bender, the climate scientists and climate modelers who work for the same organization I do are quite adamant in stating that there has been nothing resembling a flatlining of global mean temperature over the past decade.
Their position is that global mean temperature over the last decade remains on a strongly upward trend — no “ifs”, “ands”, or “buts” about it.
So, in the spirit of supporting my erstwhile colleagues — and in a spirit of not questioning in any way their motives for doubting the assertion of a flatlining curve — I ask the same question of you that they ask of me: where is the data and the analysis that supports a definitive conclusion that there has in fact been a ten-year flatlining trend in global mean temperature?
More importantly, from their stated perspective, where is a peer-reviewed research paper — one produced by “reputable climate scientists” — which acknowledges and documents this purported ten-year flatlining trend in global mean temperature?
#212 The upward 10-year trend of the 1990s has been decelerating ever since. The 1998-2007 trend is now flat. Shall I locate the analyses by Gavin and by lucia demonstrating this, or do you want to search yourself? And BTW it doesn’t matter what source you use – GISS, satellite – they show the same thing: a deceleration to flat. And it also doesn’t matter what length of time frame you choose either; the pattern is robust. Post some global temp numbers and I’ll post a script showing the analysis.
As for your colleagues, the only way you can interpret current temperatures as being on an upward trend is if you choose a long time frame greater than 10 years. And this then gets into the issue about what’s the appropriate noise model. A linear regression trend line with normal iid error gets to the heart of what Mandelbrot was questioning. Why white noise?
If your colleagues argue that temperatures are trending up, ask them where there evidence is, and post it here. Just don’t send me the same graphic you did last week. Because I just explained to you what a statistical analysis of those data will show.
Schmidt 8-year trend analysis
Ok, shoot me – so you have to shrink the window down to t=6 to get a flatline for 2002-2007. But wait til the 2008 data are in. Then you can expand the analysis to 7 years and still get the flatline. No bets on 2009.
Scott, I am not implying GHGs warming has abataed. I’m saying the previous rising trend has simply not kept pace. This is not news. Do your collleagues read?
Scott (#213), I hear what you are saying about colleagues who
but I’m curious as to what data they are citing. For example, UAH data (graph here) shows a lot of interesting variability during the past decade, but it is much more consistent with LTP and flatline trend than with a non-LTP model and positive trend (for one thing, July 2008 is actually cooler than July 1998, [and also cooler than July 1988, for what it’s worth). GISS data also show little or no upward trend over the past decade; the same with CRU.
Do you know what data your colleagues rely on?
bender, realize that I’m on one side of a very tall organizational fence, and they are on the other.
The boundary is far more than organizational; however. There is a fundamental difference in philosophy as to what constitutes evidence in defense of a position, and as to how the pursuit of scientific knowledge in general is to be approached.
Regardless of that situation, both parties to a debate have to define the groundrules before they can play the game.
This means that what is good for the goose is good for the gander as far as citing references is concerned, and as far as clearly documenting which evidentiary basis is being used for making a broad-scope statement such as “…there is a chance that the current GMT flatline is as misleading as the 1990s uptick….”
re 213 Bender
This is of course one of the limiting qualities in the predictive horizon.
Edward Ott shows us why here.
For small it becomes very difficult to improve predictive capacity (i.e., to predict the attractor from the initial condition) by reducing the uncertainty. For example, if , to reduce by a factor of 10, the uncertainty would have to be reduced by a factor of 10^5 . Thus, fractal basin boundaries (analogous to the butterfly effect of chaotic attractors) pose a barrier to prediction, and this barrier is related to the presence of chaos
The limitations of the temporal horizon are also mentioned in Nicolis and Nicolis 2007
Click to access 6253_chap01.pdf
There is also some interesting discussion on the Hurst exponent,and markov processes which have not been discussed here.
In addition there is on page 225 and illustration of how the “ensemble forecasts tend to be unrepresentive over time.
#212 — Scott-in-Wa wrote (concerning collegial views) that, “Their position is that global mean temperature over the last decade remains on a strongly upward trend — no “ifs”, “ands”, or “buts” about it.
According to Roy Spencer here, “after [2002 global] temperatures have once again remained flat.” That’s just his not-peer-reviewed opinion, of course, but Roy Spencer is definitely a “reputable climate scientist” and to my own not-peer-reviewed eyeballs, the temperature trend plotted there certainly seems to corroborate Roy Spencer’s view.
In fact, putting the origin of the evaluation a decade to the rear puts us right on top of the 1998 El Nino excursion. Hazarding a guess here, any linear trend fitted to 1998-2008 data would show a precipitous decline in global temperature.
So, you’d be right about the “ten-year flatlining trend in global mean temperature” being merely purported. In actuality, the most recent decadal trend looks positively negative.
Apart from the El Nino, the upward trend of the 1990’s doesn’t seem very up, either. There’s just been a rise from 2000-2002, followed by a commensurate decline from 2007-2008.5. No predictions implied.
Phil #211, 198: Your illustration is based on a model where the pixel representations, noisy are not, are perfectly correlated to the underlying picture. The noise you added perfectly cancels out as well.
Here’s a more realistic example set, illustrating a distorted proxy and analysis (This is PhotoShop “Chrome” with minimum distortion and highest resolution, then color-matched — using that “data model” these are the sharpest, “closest to reality” images I could get; I could easily have made it worse.)
Reality:
Model:
Is there a tiger staring us in the face, or is it a bowl of (good?) food?
My brother once made a reproduction of our father’s picture by using a typewriter. The image he made was made up of digits and letters, ie each “pixel” had no relation whatsoever with the photograph. However, the result was a very good representation of it.
Perhaps this is a useful analogy to distinguish between weather and climate?
Bart, your example does have pixels relating to the photo. In fact, the method has been automated in a variety of ways. One method takes as input a set of source photos, and an image to be matched. Each source is treated as a “pixel” and a composite is built. Fun!
In offering a source of scientific support for their position, they cite the latest IPCC report as their general catch-all reference document, as in “Scott…. please….. if you will just read the IPCC report, you will finally be informed on the substance of climate change issues….. And, better than that, you will be a better human being for the experience.”
In getting down to the nitty-gritty specifics of whether or not a flatline trend is actually in progress, they do like to cite the following theme, now familiar to CA readers of this thread, of which the following graphic represents the distilled essence of their scientific evidence: The All-Purpose IPCC Truth Squad “AGW is Real” Graphic
OK, what is my take on this kind of interaction with my erstwhile colleagues, given that a flatlining trend of some kind — important, unimportant, significant, insignificant, however you want to characterize it — now seems to be in progress, regardless of the various assertions being offered about it from various quarters?
My take is that for people in their kind of position — occupying important supporting roles deep in the bowels of the Global-Warming Industrial Complex — anything said to them of a questioning nature is, more often than not, interpreted as an arrow fired at their position by a band of Hated AGW Denialist Indians (The HADI tribe.) And so the whole discussion has a tendency to degenerate into a cowboys-and-indians type of movie drama, complete with bugle calls, cavalry charges, war whoops, and scalpings to spice up the action.
Anyway, I am becoming ever more convinced of the need for Steve McIntyre’s 2xCO2 Yields 3C Warming engineering study as a tool for managing these AGW debates.
I am also just as convinced that: (1) Steve and his team must write a formal, peer-reviewed, reasonably detailed specification for what is expected of this study, and (2) the study must go beyond simply citing a list of references and must include a Knowledge Management Engine which tightly links each central tenant of the study to its specific supporting information within the reference body of applicable scientific knowledge.
Scott, look at the “trend” from 1917-1947. Did CO2 cause that? The attribution exercise that calculates the external forcing effects is fundamentally flawed because it lowballs “interal climate variability”. The exercise is BIASED. As I’ve said more than a dozen times, I am not questioning the non-zero effect of GHGs. I am questioning the methods by which the CO2 coefficient is derived – which is NOT by physics, it’s by a leap of statistical trickery. Grant your colleagues the 1C to which they may be entitled. Ask them to explain the other 2C. Ask them if it is statistically correct to assume as much of the variation as possible is attributable to external cause (signal), and ASSUME the residual is internal “noise”. It is not. Ask Wegman. The higher and redder the noise, the lower the fraction attributed to GHGs must drop.
Why do you think the Team is in love with AR(1) (i.e. pinkish) noise models?
Phil, Mr Pete
The photograph example is simply confused, and perhaps illustrative of the broader confusions over models and realities. The accuracy of the picture of the tiger initially depends on the quality of the physical lens through which the image of the real tiger was captured. That the stored data for the image can be resolved as pixels is just a reflection of current technology – we don’t use silver salts any more.
You can put together a large image by arraying lots of tiny images of anything whatsoever – you could draw George Bush with thousands of little Che Guevaras – but only if you already know accurately what Mr Bush looks like. That is, the result is known ahead of time, and the particular nature of the pixels, characters, little revolutionaries is irrelevant.
The “Global Climate” on the other hand is an abstraction, hypothesised to behave according to a number of known physical laws, modified by a range of unknowns. The GCMs provide pictures of how it might be if so, and so, and so….
The models can be tested against data. But both in practice and in theory it matters what the data actually are – a collection of low temperatures is not at all like a collection of high temperatures. Each datum has both a qualitative and quantitative individual effect on the whole.
So Dr K’s appeal to induction is not at all addressed by reference to pixelation.
Phil. (#211) I, too, am having trouble seeing the point of your pixelation example. Perhaps we are talking at cross-purposes?
Suppose our question is something like this: How well do the GCMs correspond to the physical processes they purport to represent?
Obviously there are lots of criteria for judging correspondence, and we certainly don’t expect a model to reproduce everything about a physical system (“all models are wrong; some models are useful”).
However, it is reasonable to come up with some practical ways to check (validate and verify) a model — some criteria that one might expect a reasonably well constructed model to meet.
To be fair, some criteria have been offered up freely. For example, my sense is that the GCMs have been shown to do a reasonable job of “predicting” the past — defined as an aggregate — in the time domain. However, because the GCMs are tuned to the historical record, this is a relatively poor test of the predictive skill of the models.
What else might we look at? Well, as DrK did, one could consider how well GCMs predict for a given set of specific locations. That exercise indicated some problems that ought to be explored.
One might consider how well GCMs reproduce the spectrum of the noise — do reflect the topology of the climate system. My sense is that GCMs exhibit serious problems in this area, too (admittedly, I have not checked all of the models).
One could go on and on, of course. In fact, model developers should go on and on.
Do any of these tests and criteria matter? In a practical sense, it is very hard to know. Perhaps, flawed as they are, GCMs are satisfactory for the purposes at hand.
But how would we know?
Suppose, for whatever reason, the concept of “trusting the experts” is not good enough?
The dearth of forthright answers to such questions is troubling. Where are the reports that justify failure to reproduce the spectrum (or, alternatively, show that GCMs do in fact reproduce the spectrum despite all the evidence to the contrary), for example?
To be clear, I understand that the climate system involves complex physics (e.g. N-S equations) and intractable numerical problems. IMHO, however, that argues for a more cautious and detailed assessment of errors, not a more cavalier approach.
Returning to DrK for a moment, it is worth pointing out that he conducted a test of the GCMs using rigorously defined criteria. In fact, he selected the most important criteria available: How well do GCMs describe the local system? (Like politics, all problems are local; this is not an academic criterion).
I, for one, do not see how DrK’s results can be dismissed.
Finally, IMHO, the pixellated tiger corresponds to nothing more than a red herring.
Michael, TAC: exactly. My “distortion” example was intended to visually illustrate the issue. We do not know ahead of time what the image should look like. If our measurement system captures a distorted (rather than just noisy) view of reality, and we do not know what the distortion is, then we cannot derive a realistic model from our measurements.
As you and others have illustrated, there are many limitations in the models and DrK’s concerns are not so easily dismissed.
Another illustration may help some readers: consider a compass. It points to magnetic north rather than true north. If you have no idea where magnetic north is nor the timing and amplitude of its motion, the compass is not going to tell you anything useful. You’ll end up in the wrong place every time. (Yes you can calibrate a compass… and then you have solved the unknown…at least until magnetic north moves.)
Re #225
Yes, I think we are. K’s point was: Now on the global scale, since there is not (and cannot be) any proof by deduction that the models perform adequately, let me turn to induction and say that knowing the poor performance on local scales increases the probability of poor performance on the global scale.
I tried to show that even though we had a poor local representation we could still get an acceptable global view by using images with added noise, hopefully the following will make it clear.
This is a of the original photo of the tigercub.
This is the same of the noisy image with 56% uniform noise added.
Clearly the pixels (local representation) in the noisy image are very different from the ‘true’ values yet the ‘global’ view is not too bad. So inference from the poor ‘local’ result does not necessarily mean that the ‘global’ picture won’t be useful.
bender, thank you for your thought-provoking ideas. You say:
Looking at the MAGICC estimates of the various model factors for 19 of the models used in the FAR, I find that the forcing change in W/m2 for a modeled doubling of CO2 ranges from a low of 3.1 to a high of 4.1. The models are all over the place.
And it’s worse with the climate sensitivity, which the models report as being from 0.5°C per W-m^2 to 1.9°C per W-m^2, a range of about four to one.
So any search for an “engineering quality” exposition of either the watts per doubling (anywhere from 3.1 to 4.1 W/m2) or the sensitivity (varies by a factor of four) is perforce going to have to be very vague, in order to give answers that vary that widely. Accordingly, I can only agree with you that at present, neither of these numbers (watts per doubling, degrees per watt) is derived from the underlying physical principles.
w.
I tend to agree with TAC and others; the pixellated tiger, just like comparisons of weather/climate to the Lorenz attractors, are not relevant arguments here. They are analogies; and poor, unrepresentative analogies at that.
To my mind, the problem can be split into two parts: the error propagation of the models, and the mitigation of those errors through scale averaging. We know at short scales (i.e. weather) the error propagation rapidly outstrips any benefits that scale averaging can supply. That’s why we have a very limited time horizon that we can predict weather over. So in order to recover predictability, we need the error propagation to go over some kind of a knee in the curve, or even just a flatline, to allow the scale averaging to bring the noise back down.
How is Hurst relevant? The Hurst parameter describes the rate at which scale averaging brings down the error. Double the scale and the noise power reduces by a factor proportional to the Hurst exponent; if H=0.5 (white noise), the noise power reduces by one half, if H=1, the noise power does not reduce at all (i.e. scale averaging does not help). But we need to understand the error propagation model as well.
The Lorenz attractor is often cited as a popular example – as an analogy to weather / climate. But the Hurst exponent for the Lorenz attractor eventually tends to 0.5, and the error propagation model flatlines once the fine scale behaviour is fully decorrelated. So we can see from the error propagation model of the system and the scaling behaviour of the system that some kind of predictability could be recovered.
This is where I see DrK’s paper kicking in. The error propagation model is being assessed, and if climate is to become more predictable at longer timescales, we should see the error “flatlining” or reducing at some scale. But it simply doesn’t; the error continues to grow even at the 30-year scale. The error is at a minimum at shorter scales.
Even if we introduce spatial averaging to reduce the error, spatial averaging sits on top of the time averaging, and the minimum error for time averaging is at the monthly scale. This means that even if spatial averaging were to reduce the error further, the best predictability would still occur for the global behaviour at the monthly scale. But I don’t see anyone claiming this to be the case.
What does the pixellated tiger teach us? Very little. It tells us nothing about the error propagation of climate models. All it shows us is that if the Hurst exponent is 0.5 (which it will be for the uniform noise Phil has added), then scaling reduces the error by one half. So what? The Hurst exponent of weather/climate is not 0.5 (either temporally or spatially), we’ve seen that demonstrated over and over again. So the tiger tells us nothing useful or relevant to the actual problem at hand.
Well said, Spence_UK:
I.e. uniform noise is not an error that propagates; noise can be filtered out. Distortion is an error that propagates, which is why I used it in my counter-example. If the problem were as simple as noise, we’d be long past this issue.
Phil. (#227),
You and I, as well as DrK, undoubtedly agree with this point.
I think we would also agree that there is room for improvement in
possibly something like:
That’s more-or-less what I assumed DrK meant. In any case, it’s semantics, and if that’s your point, let’s just agree and move on to a more interesting discussion — what about the topology of climate?
😉
I would be in agreement too .
It’s at least as misguided analogy as the one equating fundamental understanding of N-S with steady flows along wing tips .
It only shows that the author has no insight in the problem that is actually discussed here .
A comment on :
I consider this being the single most important question on which the very existence of climatology as science depends .
There should actually be a specific thread treating with only this question while it is (unfortunately) treated in many different threads (this one , the exponetial divergence , Mandelbrot etc) .
It is indeed worrying that this single most important question hasn’t been treated theoretically and that there has been no clear , unambiguous answer despite the large investment put in the development of GCMs .
Of course I can’t answer it either but I can try to cut off all the unnecessary and confusing garbage around this question .
Every physical theory can be basically reduced to the mathematical problem of solving a more or less large amount of ugly non linear PED/ODE that generally describe LOCALLY the conservation laws (energy , momentums , mass) and symetries .
There are 4 posible strategies to determine the dynamics of the system .
1) Find a solution analytically
2) Find a solution numerically
3) Do a perturbative treatement
4) Do a stochastic treatment
Application to the Earth system eliminates at once the strategies 1) , 2) and 3) .
1) because we can’t even solve N-S alone and there is much more than only N-S in the Earth system
2) because everybody agrees that the spatial resolution (100 km) doesn’t allow to solve anything let alone N-S . The spatial resolutions if we should go to Kolmogorov scales where such a strategy would make some (limited) sense and find some support from established physics are a factor 10^8 below . So that is clearly beyond any present or future computing ability . Noteworthy is that this would be only a necessary condition but not sufficient .
3) because as T.Tao says , it is necessary to have something small and that this something stays small for a long time . Unfortunately that is not a property of fluid dynamics where small differencies get amplified . Even to obtain boundedness results is highly non trivial and actually not realised in the general case .
So now whether we like it or not , if we want to do climatology we are stuck with only the stochastic strategy .
I’ll try to define it .
If we want to obtain a function T(x,y,z,t) obeying certain non linear PED/ODE we will look for a PARTICULAR type type of solution :
T(x,y,z,t) = Ta(x,y,z) + u(x,y,z,t) where Ta(x,y,z) is a time average of T(x,y,z,t) over a certain period L (eventually a bit space averaged around the point (x,y,z)) AND u(x,y,z,t) is a random variable with a known probability density distribution .
The advantage of looking for this type of solution is obvious – Ta is time independent so we have a steady state type equations defining it that are much easier .
As for u that now concentrates all the difficulties related to the time dependency we have quite effectively eliminated them because it is a random variable with a known distribution law .
Needless to say that it of course doesn’t work with N-S because the probability distribution of u is not known in the general case but the whole Kolmogorov turbulence theory is precisely based on assumptions leading to “reasonable” distributions of u that work in some precisely specified cases .
So now it is quite easy to understand intuitively some very popular questions about the climate .
1)
Why isn’t climate precisely defined ?
Because climate is T(x,y,z,t) – u(x,y,z,t) and if you have no clue about u , you have no clue about what the climate is .
2)
What is the “right” scale of time averaging ?
It is the scale at which u has a stable known probability distribution . Of course that doesn’t say that there is a unique scale because the properties of u can change when the scales change . This problem is nicely expressed by T.Tao when he recommends “understand pseudo randomness” because u may SEEM white at a certain scale but reveal itself as being not random at all at bigger scales .
So this scale is unknown and it may well be that there is no such unique specific scale (notably the case of deterministic chaos) .
3)
Does u cancel ? This is better than “Do errors cancel ?” because u is not an error – it is a difference to a mean .
If u is white it does . If it is not , it does not . What is u we don’t know , see 2) .
On top of this problem comes the true error propagation due to numerical treatments but that is another issue .
4) Why would be weather not predictible and climate yes ?
Because weather is T(x,y,z,t) and it incorporates the full difficulty of non linearities and divergences and we well know that this leads to unpredictability .
Climate is Ta(x,y,z) and as we eliminated the complications through statistics of u , Ta is a solution of steady state equations where the conservation laws and symetries are easy to formulate and to solve (numerically anyway but in simple cases even analytically) .
So Ta (=climate) is simply deterministic and predictable .
Actually to be more precise , Ta is mathematically NOT defined for time scales less than that famous typical scale L so the climate doesn’t even exist for scales less than L .
A climate scale “point” has a duration of L .
The climate is quantified (in the sense of quantum mechanics) by time segments of length L – the 2 following climate points are separated by L years and there is nothing between them only weather .
Of course all that is only relevant subject to an adequate answer on 2) .
I have been longer than what I intended even if I only wanted to say that basically all climate issues are self-referentially contained in stochastic properties of u and that’s why the statisticians will play a bigger and bigger role .
Yet it has not been proven and cannot be sofar that u is a random variable with known probability distributions .
It might well be that mother Nature is instead only playing with us her favorite game of “pseudorandomness” by offering us a mix of high frequency and low frequency interacting events and mischievously rejoices that we are missing all the low frequency ones .
Re #222 Scott-in_WA
Try showing your colleagues some real higher resolution data:
Image (on the Forum) of HadCRUT3 1997-2008 and then let them argue about no flat-lining. Yeah, it’s 10-year long weather noise.
Rich.
Willis # 185
The infinite variable dilemma. How does one quantify these sorts of things? Will the anomaly be +1 any time soon? Throw your dart.
MrPete #226
You have to know the magnetic declination. Adjustable compasses are good for that sort of thing. Should one understand the difference between compass, magnetic and true, and have the available data, the problem is simply resolved.
So, the question is, if you’re in 17T NJ 62770 22808 then what three streets are you standing by, in what city?
🙂
The New Scientist editorial says that there will be a lot of studies that show actual climate is not following the models, and that the actual Climate may cool for the next ten years.
But they say there is nothing wrong with the underlying science models, or the predictions. They say anyone who has doubts is talking nonsense!
Not so sure about this myself, don’t profess to understand the models, but do understand the actual weather.
If the climate cools for 20 years or 30 years, will the models still be correct ? according to the New Scientist logic the answer is yes !
#232 Thank you, Tom, for the validation, and yet another thought-provoking comment. Regarding the presumed cancelation of errors with increasing time-space scale, you say:
I agree, and I think the inaugural issue of Journal of Statistical Climatology (online, free) should be devoted to this foundational question. I would love to see Gavin Schmidt working as Editor under Art Wegman, Editor-in-Chief, JSC. Gerry “Wingin It” North is the guy who can put it all together.
Phil,
Your picture of the tiger analogy leaves out a lot. You’re assuming the global picture has sufficient resolution to see a detailed image of the tiger. When you add white noise, you seem to be assuming that the tiger isn’t moving and you will be able to take enough independent pictures to average out the noise. But for climate modeling, what you really need to do is take a picture of the entire planet with sufficient resolution to see an object the size of a tiger in some detail. In fact, the global picture, if resolved on the meter scale horizontally and vertically, which isn’t nearly good enough to see a tiger, has to have on the order of 1E19 elements. The GCM modeling resolution is more like 1.5E8 elements, 10km horizontally and 1 km vertical. Ignoring vertical resolution, that would be a 5E6 pixel picture of the planet. That seems like high resolution and the complete picture would be easily recognizable as the Earth, but not nearly good enough to count tigers. Now add pink noise and non-stationary tigers.
Read Turing on morphogenesis. For a tiger to develop its stripes (ok, leopards and spots, to stick with Turing), each cell must communicate with neighboring cells. The expression of coloration is extremely tightly controlled at the genetic and molecular levels. This is why coloration is so heritable, but vulnerable to environmental perturbation. The relevant comparison that Phil might have made is a tiger whose cells are excommunicated from one another. You don’t get stripes. You get mutants. Which is hard to imagine (but has been experimented with in the case of butterflies). But this only goes to show why I loathe climate analogies. They are difficult to construct, and impossible to extrapolate from. It’s not about the tiger’s image; it’s about the tiger iteslf. And it’s not about error; it’s about error propagation.
As TAC, DrK, Spence_UK, etc. have outlined.
If local “weather” errors do not in fact cancel at some time and space scale, then the climate concept is a convenient untruth.
There are so many convenient untruths in predicting climate, weather or the next roll of a die. In the short term the die can confound the predictions but eventually the die will meet predictions unless it it weighted. Weather predictions, while less than perfect, average to a reasonable accuracy in the short term after decades of tweaking. Climate estimates for future decades warrant reasonable skepticism. Especially if there is a chance the climate die is weighted.
At least weather models include reasonable uncertainty. Compare a five day tropical weather prediction cone with a 50 year climate prediction cone. This thought just came to me while sitting through tropical storm Fay. Not to say climate scientists are ignorant, but there is an air of overconfidence.
Natural variation in climate can easily exceed 1 degree C per century. To assume the past thirty years rise in temperature is predominately due to AGW is difficult to accept unless one is gambling on the outcome. I really hope that A. Tsonis has a good presentation in Sicily. It could enlighten a few to the chaos that is weather/climate.
A die has an expectation, E(x). It is 3.5. This can be proven empirically through trials of realization (rolls of the die). Additionally, it is known how quickly a sample of x’s converges to its expectation. In contrast, what I am asking is whether it is known how quickly weather converges to the climatic “expectation”. Is a given expectation justified? Is convergence rapid enough for the expectation to ever be realized? Or does the expectation change faster than it can be realized? You see why simple analogies break down …
You have all these dice rolling in all these grid cells, but the roll in one cell affects the roll in another cell. Probability fields. How will these sum? How will they average over time? You have dice on land, dice in the oceans, dice in troposphere, dice in the cryosphere. Each roll affecting the others. All the rolls happening at their own characteristic time-scales, each die a little bit different in expectation and influence.
I think Steve M discourages the use of simple analogies. In part because they have little to do with auditing.
Bender, I am sure he does but simplicity is elegance. The further in the future you wish to predict the more die casts you have to predict. I read one AGW blog that I can’t remember that stated warming through 1950 was solar influenced then GHG warming overtook natural forcing. That is a loaded die. Based on the Lean solar reconstruction that over compensated for temperature variation.
Then Spencer uses the same Lean reconstruction to prove global cooling is happening. Also a loaded die.
CO2 doubling sensitivity is based on an attempt to explain glacial/interglacial temperature variations by a scientist with an epiphany over a hundred years ago. Then another scientist comes up with a different estimate of sensitivity. Then another scientist adds the two estimates and divides by two. That is the science behind 3 watts/meter squared. (Wacko psudo-science in my opinion).
For this debate to return to science the validity of each proxy and model used to illustrate a scientific thought needs to validated. Steve can substitute audit for validated if he likes.
In the real world there are hundreds of climate dice rolling. Each attempt to quantify one of the die is a step. With enough properly documented step evaluations the science can produce reasonable predictions. We ain’t there yet.
241 myself,
That wasn’t all that eloquent but hopefully you can see my point as a fence straddling by stander. To quote a bad sexist joke, “Statistics are like are like women. Once you get them down you can do anything you want.” Standardizing statistical methodology is crucial for proxy reconstruction and general climate modeling to approach the reliability of hurricane track forecasting. 🙂
242
Anther bad statistical joke is that the average number of testicles per person in the US is close to 1.0.
Re the tiger, I was somewhat surprised to learn that under the fur the skin of the tiger is also striped.
captdallas2,
Yes.
No.
The forcing estimate comes from detailed calculation of radiative transfer based on hundreds of thousand absorption lines of about 40 molecules including molecules with different isotopes of carbon, oxygen, hydrogen, etc. and their behavior as temperature and pressure change with altitude as well as the physics of scattering by water droplets and other aerosols. The characteristics of most of these lines have been accurately measured in the lab and the field. You may see different forcing estimates quoted from time to time, but the IPCC 4AR value has a lot more than “wacko pseudo-science” going for it. It is, in fact, the part of AGW that is both best understood and is least uncertain. If you want to make statements like that, the bulletin board has a lot of people who apparently think like you.
Do you believe that satellite temperature measurements are accurate? The calculations used to convert microwave intensity readings taken by satellite are done using the same physical principles as are used to estimate forcing from doubled CO2. Converting the forcing into surface temperatures is a different story. That’s the indirect topic of this thread.
bender, you raise an important question when you ask:
I have a separate question which is even more basic than that. If (as appears to be the case) many or most weather phenomena exhibit self-organized criticality, do averages of weather ever converge to anything significant?
Or as another way to ask it, what is the physical meaning of the “average” of things which obey a power law rather than having a Gaussian distribution?
And finally, phenomena which obey a power law often do so within a bounded range (temporal or spatial), and above or below that range may approximate a Gaussian or other distribution … what does an average of such phenomena tell us?
w.
DeWitt, you say:
Say what?
If that is the case, if the forcing is the “best understood and least uncertain” part of AGW, then why do the models use values for the forcing from CO2 doubling that vary all the way from 3.1 to 4.1? Did they not get the memo?
Or perhaps you are aware that this “least uncertain” part of AGW does have a huge range, and are saying that the rest of the AGW hypothesis is even worse … your statement makes more sense that way, at least, although I doubt that’s what you meant.
w.
This question has been asked at RC. And dodged. I think it’s a good question. I don’t think it has an answer. What do I know. Let’s ask Lord May.
Willis,
No, that’s fairly close. Take a look at the uncertainties on the other forcings in the 4AR. They’re pretty bad. A range of 3 to 4 W/m2 looks very good by comparison. I’d like to see the citation for 3 W/m2, btw, to see if it does result from a difference in definition rather than calculation or it’s from a faulty model. It certainly isn’t the current official IPCC value or 4.1 W/m2.
Forcing varies a lot geographically. See these graphs from GISS, based on Hansen, et.al., 2005. Then there’s forcing nomenclature. There’s forcing at the top of the atmosphere, the troposphere, etc. Then there’s instantaneous forcing and forcing after the stratosphere equilibrates. Those numbers can all be different even though the forcing calculated according to the IPCC definition (forcing at TOA after stratosphere equilibrates, IIRC) is the same. Look at the tables in Hansen, 2005 for example. When you get to models, the radiative transfer calculations are highly parameterized and those parameterizations have been known to have been wrong in the past for some models. Global average forcing isn’t a number fed into the model, it comes from the model. That means it depends not only on how well the radiative transfer calculations are done, but also on how each model calculates the temperature, pressure and ghg concentration profiles at each grid point. Those calculations are parameterized too.
However, all that hardly means that the number was picked out of the air.
Re: 232 Tom Vonk provides an inciteful analysis of why GCM’s can’t solve climate prediction problems. I would urge some review and commentary on his analysis, which I follow generally, and appears plausible; but is otherwise “above my pay grade’.
Dr. K, if you are still reading this … or anyone else knowledgeable …
I find a host of ways to estimate the Hurst coefficient: R/S, Whittle fit, wavelets, and a long, long list of others. At times, they give contradictory answers. At times, some give answers greater than 1.0.
In all of this, I feel like the man who foolishly bought a second wrist watch, and now is never certain what time it really is … what’s wrong with Hurst’s original estimator to bring out all the alternatives?
w.
I’d love to see that too 🙂
To understand the relationships between fluid dynamics and statistics , the most rewarding way is to study Kolmogorov’s turbulence theory .
This is an asymptotic field theory of energy dissipation showing many analogies with the kinetic statistical theory of gases .
Kolmogorov has also surrendered and avoided to ask the question of the velocity field and its evolution in time because that is the famous unsolved N-S problem .
He asked instead an easier and much weaker question of what can we say about energy dissipation in fluids .
This question has 2 advantages – you ask about a scalar and not a vector so directions don’t matter and you may get rid of the time when the energy dissipation happens in a steady state asymptotically .
How did he do this ?
Well he realised that the energy dissipation was happening at very small scales where all the small eddies looked very similar .
Therefore you can do what Boltzmann did with molecules and add an additional hypothesis that the very small eddies are homogeneous and isotropic .
Follows that the anisotropy and non homogeneity at large scales don’t matter for what happens at dissipation scales .
Now the homogeneity condition (constant specific KE) and the isotropy condition (the averages of all velocity components squared are equal) enables to make statistics on the scalar V² at small temporal and spatial scales
In other words the small scale statistics have a universal form that can be deduced from the fluid characteristics .
Of course the theory is valid if the assumptions of isotropy and homogeneity at small scales are valid and that demands for high Reynolds (fully developped turbulence) and intuitively we can indeed visualise that a very turbulent flow will have plenty of small eddies everywhere .
If the Reynolds are low , the flow is no more homogeneous and isotropic and the theory fails – there are no more universal statistics even for very small scales .
As we are lucky , the most important fluids water and air move with high Reynolds in their natural state and that explains
the ability to make statements about energy and energy dissipation with high accuracy despite the fact that we are unable to know the velocity field and its evolution in time .
Of course the price to pay is that those universal statistics of eddies are only valid below the Kolmogorov scale (above the things are no more isotropic and homogeneous) and this scale is very small (millimeter and submillimeter) .
This spatial and temporal resolution is NECESSARY to be able to do DNS and that’s why GCMs can’t and will never do DNS .
What they can do instead is LES where the smaller scales are treated by a subgrid parametrization what means that they can get energy questions approximately right because they happen at large scales but the energy dissipation more or less wrong (this last subject is the favorite one of Jerry) .
So by analogy with Kolmogorov what is the problem of the statistical approach to climatology which is the only one possible as I have developped it above with the T = Ta + u model ?
Well the “residual” u plays here the same role as the eddies in Kolmogorov’s theory .
Is there some characteristic space scale at which u has universal statistics ?
If we could make an isotropy and homogeneity assumption , it might have – not sure but it could give a hint .
Unfortunately “u” which is temperature or humidity or ice mass or whatever climate variable you choose is clearly neither isotropic nor homogeneous so the “Kolmogorov’s program” stops right here .
As for the temporal scales , here the problem is not so much the small scales (where we have weather as Kolmogorov has his eddies)
but the large scales (the characteristic L time that defines the climate) which is a concept that doesn’t make sense for Kolmogorov’s theory .
In other words the Kolmogorov approach of the statistical laws of fully developped turbulence might be useful to treat the weather but not really the climate whatever “climate” may be .
So again we are back to the foundations which are to ask what the universal statistics of “u” are if any .
244 DeWitt
Almost 30 years ago, Jule Charney made the first modern estimate of the range of climate sensitivity to a doubling of CO2. He took the average from two climate models (2ºC from Suki Manabe at GFDL, 4ºC from Jim Hansen at GISS) to get a mean of 3ºC, added half a degree on either side for the error and produced the canonical 1.5-4.5ºC range which survived unscathed even up to the IPCC TAR (2001) report. Admittedly, this was not the most sophisticated calculation ever,…” Gavin post on RC
Note: I did use the incorrect units W/M2 instead of degree C. The Pseudo science mainly comes from Hansen’s estimate of sensitivity using paleo reconstruction. Using just the physics of the radiative transfer of GHG then comparing to instrumental climate data allowing for realistic natural climate variability to estimate feedback/forcing. Allowing of course for uncertainties, would make sense. That might produce the elusive engineering quality report.
Willis (#245), bender,
I am not sure I understand the question, but I might be able to answer a different question. 🙂
If one assumes that a stochastic process is stationary (Hurst’s Hunit root test), which would be consistent with DrK’s Hurst-Kolmogorov pragmaticity, then the process has a finite mean.
Of course any finite realization of a stochastic process, stationary or not, has a finite mean (you can always compute the average of a bunch of numbers).
One of the interesting properties of stationary LTP processes, however, is how slowly sample means converge to population means (sample size requirements often involve numbers best represented in exponential notation).
Is that what you were looking for?
Emeritus Professor Garth Paltridge was a Chief Research Scientist, CSIRO Div of Atmospheric Research and CEO of the Antarctic CRC. Writing somewhat informally for “the Skeptic” 27,4, (2007) with some deletions for brevity here:
I find this whole article readable, credible and composed by an expert. It covers many of the posts above, without so much of the maths.
Re Tom Vonk at 251, how are you going to predict the frequency of formation of your “packaged” eddies, let alone their position and direction? Sure, it’s a simplification, but it leaves many, many variables still unmeasurable.
Is it not time to set benchmarks, so that progess in GCMs has to be demonstrated before they drain the GDP in the next phase? Knowing when to get into a project is one third of the skill. Knowing when to exit is two-thirds.
#254 I agree with your point – and you do have the nub of it. But I do not actually know if Earth climate is stationary. Is it? I do not even know if it is ergodic. Do you? Over what time-scales can Earth climate be considered stationary and ergodic?
Probably that’s why the US guvmint decided to sponsor the Climate Change Research with $1,8 Billion annually….
Click to access ccsp08p.pdf
captdallas2,
We’re pretty much on the same page on climate sensitivity. Going from forcing to surface temperature is not trivial as posts on this thread demonstrate. The derivation of the sensitivity range from Gavin’s quote comes very close to wacko pseudo-science, otherwise known as a SWAG (Scientific Wild-A$$ Guess).
Willis,
I went back and checked the AR4 WG1 report. The official IPCC estimate of forcing from doubling CO2 is 3.78 W/m2 +/- 10% or 3.4 to 4.2 W/m2. The 10% error estimate comes from the results of five different line-by-line programs. Estimates of LLGHG (Long Lived Greenhouse Gases) forcing from GCM’s are considered likely to be less precise than that. Other forcings are less well understood and have correspondingly larger uncertainty. Several have ranges that include zero.
Geoff Sherington
I am not going to predict the frequency of the eddies and even less their movement or direction .
THAT would necessitate to solve N-S what nobody is able to do .
What I will be able to do (at least with high Reynolds , e.g a fully developped turbulence) is to develop a statistical description (so many eddies of that size and that much Joules dissipated per kg) of where the energy is and where it goes .
I speak only about energy – a scalar , not about velocity field – vectors .
Now while the example of the cigarette smoke is a good example of deterministic chaos and unpredictability (the N-S problem) it is NOT a good example of the Kolmogorov theory of turbulence or of some stochastic approach of fluids .
Clearly your cigarette smoke is neither isotropic nor homogeneous (and has too low Reynolds anyway) and if you remeber well , I said that the theory fails in this case – there are no universal statistics even at the very small scales when the isotropy and homogeneity requirements are not met .
I think that you can predict fairly little about this smoke plume even statistically .
Broadly you can say 3 things
– the flow goes up because it is hot
– the flow gets more and more irregular as you go up (more and more swirls and eddies) because there is the exponential divergence at work where a very small instability gets fast amplified .
– there is an average height where the energy of the plume finishes by being dissipated and the molecules of the smoke achieve thermodynamical equilibrium with the air .
That’s better than nothing but it will tell you nothing about what the velocity field of the smoke plume (e.g its form) will be and how it will evolve in time .
This prediction is not feasible even if DNS would yield you a quite realistic and believable cigarette smoke (submillimeter resolution) but sadly not the one you will observe because the slightest eror on the initial conditions would produce numerically a very different plume than the one you see .
Then you can play with the initial conditions and produce millions of different cigarette smokes and compare them among themselves .
You can produce an “average” cigarette smoke by averaging the million of simulations .
You will notice that all simulated smokes have definitely caught the essence of what makes the smoke-pluminess so N-S has obvoulsy a role to play .
Yet when you light a cigarette , you will observe something that is all the time different of all the simulations or averages of simulations regardless how many millions of simulations you do .
Sometimes you will be very close (say 5 %) to a particular simulation and sometimes you will be very far from all of them .
That is exactly what Schmidt is doing when he is “generating” weather noise in his GCMs even if the model does something infinitely crudest than DNS .
But this issue you raised also contributes a bit to the question if a model can be wrong locally and right globally .
In the exemple you choose , the model is wrong locally (the swirl is not at the right place in one realisation) but also globally
(however many averages of simulations I do , the averaged swirls are also not at the right place and have not the right sizes) .
After all the discussions here , I guess that nobody is surprised about this result anymore because everybody knows that
the cigarette smoke form is deterministic chaos and deterministic chaos is unpredictible even by statistical means .
Such clarity of prose must come from clarity of mind.
================================
I could not imagine that our paper would trigger so thought provoking discussions and profound thoughts even about the most fundamental questions about climate. I am really happy for this. I take the opportunity to discuss three elementary questions closely related to several of the above comments.
Question 1. What is climate?
An authoritative answer is given in NOAA’s glossary (http://www.cpc.noaa.gov/products/outreach/glossary.shtml):
I see that this definition is quoted several times in RealClimate. In their recent “Comprehensive climate glossary”, NOAA’s glossary is their first link. Also, this definition is quoted in a comment in the thread “Hypothesis testing and long range memory”, parallel to this one, where this question is also discussed with interesting contributions.
You may find my Question 1 silly, but what about this answer? Well, according to my Greek standards, I would not call this definition scientific. Is there anything special with the 30-year time scale, which is put as a minimum? Even IPCC provides records of observed climate on a 30-yr, as well as a 10-yr, basis (http://www.ipcc-data.org/obs/index.html). Is it a surprise that “the climate taken over different periods of time (30 years, 1000 years) may be different”, so as to justify the inclusion of this sentence? Apparently, yes, for those who formulated the definition, in an intuitive expectation of a fast convergence of the process to a stable average. But the most non-scientific part is the reference to the old saying, “climate is what we expect and weather is what we get”. Its incorporation into the definition, in combination with the implication in the previous phrase (fast convergence) gives away the intentness of the definition introducers to the classical (IID) statistical paradigm, which is totally inappropriate for climate.
Given that the mainstream climatologists seem to recognize now the Hurst-Kolmogorov pragmaticity in climate, I would recommend them to study its implications to the very notion of climate. I give an example from the paper:
The quotation is the following (where an SSS process stands for a simple scaling stochastic process, synonymous to a Hurst-Kolmogorov process).
The mentioned Fig. 5 refers to runoff, with a Hurst coefficient H = 0.79. Note that most long time series of temperature indicate greater H, particularly on large spatial scales (e.g. H > 0.90) and make things even worse than described in the quotation.
Accordingly, I propose the following rephrasing of the old saying, to make it more scientific:
(I hope that TAC can correct the English and perhaps the logic here as he did in my previous comment).
Question 2. What is climate change?
The NOAA definition (from the same glossary) is:
Again I have problems to accept this as a scientific definition. What is the meaning of “non-random”? Isn’t the reference to “non-random” a confusion of a natural process with the modeling convenience we use and our ability to explain the change (attribute it to some causative mechanism)? If a change in climate is random (we cannot explain it), isn’t it a “climate change”?
As random is usually identified with “noise”, this brings to my third question, also related to some of the comments above (e.g. the tiger example):
Question 3: What is noise and what is signal?
Questions 2 and 3 would require long discussions. Here I give my view very briefly, using a quotation from the paper:
The quotation is:
I apologize for this monologue, the self-quotations and for my disregard of authorities such as NOAA.
Willis, #250
The Hurst coefficient is uncertain (see K&M 2007 mentioned in #262) so it is not a surprise that different methods give different answers. Unfortunately most methods are not consistent in estimating H 1 (Koutsoyiannis, D., Climate change, the Hurst phenomenon, and hydrological statistics, Hydrological Sciences Journal, 48 (1), 3–24, 2003).
I think that still we need better methods and that the problem of the estimation of H needs additional research.
Previous comment corrupted – here is the correct version (hopefully)
The Hurst coefficient is uncertain (see K&M 2007 mentioned in #262) so it is not a surprise that different methods give different answers. Unfortunately most methods are not consistent in estimating H < 1 as they should, and they do not give any warning about it. Particularly the original method by Hurst is inclinable to this inconsistency and I do not recommend it.
My favourite method is that of the aggregated standard deviation. I prefer it because of its (a) easy understandability and transparency in order to enable perception of the behaviour and not to hide its implications – particularly the involved uncertainty which other methods may hide; (b) simplicity, in order to enable a probabilistic description of the concept it uses (only the standard deviation) and hence a statistical framework of estimation and testing; (c ) objectivity, in order prevent arbitrary choices by the user. I have proposed a version of the method that precludes H > 1 (Koutsoyiannis, D., Climate change, the Hurst phenomenon, and hydrological statistics, Hydrological Sciences Journal, 48 (1), 3–24, 2003).
I think that still we need better methods and the problem of the estimation of H needs additional research.
Dr. K, and TAC, many thanks for your answers to my questions about the estimation of the Hurst parameter. I am reading the paper you cite above.
I must admit to a great confusion about the thought processes of the AGW enthusiasts. Their arguments often come down to “I will use I.I.D. statistics, which I know are only valid for stationary processes, to prove that the climate is warming” …
w.
Climate is an average, an expected. The first is 30 days. Or even still, perhaps t_mean from the high and low of the day.
I know if I count my girlfiend and myself, we average 1 testicle per person.
TAC, you say:
Sorry for the lack of clarity.
The climate over the past say million years has alternated between frozen and not. Over the last 10,000 years, it has varied from warmer than now to cooler than now.
So … if climate is the average of weather over thirty years, we would get very different answers depending on whether we chose the period 1961 to 1990, 1661 to 1690, or -25090 to -25061.
Or if we wanted the averages more “converged”, we could average over a hundred years around those different points … but what would the answers tell us? Would they give us more information than the 30-year averages?
So that was my question. As we increase the time period, do the averages “converge” to anything meaningful, anything which is clearly “climate” as distinguished from “weather”?
Or to put it another way, is “climate” to a human just “weather” to a thousand year old tree?
w.
Willis,
To build on DrK’s thoughts, don’t forget that you have an estimation problem here. i.e. The issue is not just how to calculate a Hurst coefficient, but how to estimate it, given a limited sample (=one short realization drawn from a theoretical ensemble of all possible infinitely long realizations). No doubt the estimator of the Hurst coefficient is extremely slow to converge to expectation. Also: any idea how the estimator performs when subject to noise (e.g. measurement error)?
#267
A series ensemble may have an expectation that is not realizable in any instance. Discrete state machines (or dice) are an example. Does Earth persistently alternate between black and white (warm and cold) states, such as during D-O oscillations? That is where the Urbinto “Female:Male 0 vs 2 testicles” analogy becomes relevant. An average (such as a GMT, integrated over 30 years) may not be a meaningful descriptor in the case of a multi-state system.
IPCC asserts that a 30-year integrating window is sufficient to distinguish between weather noise vs. climate trend. Insipred by the motto of the Royal Society, I question that.
RC asserts that the poor performance of the GCMs at a local scale does not imply poor performance at a global scale. I would like to see a proof.
This is why DrK’s papers (not just this one, but ALL of them) are relevant. He is questioning some foundational assumptions that underpin the whole of “climate” science.
Gavin Schmidt says DrK’s results in this paper are correct, but trivial. I think these results open up a Pandora’s box that the consensus would like kept closed. I am curious to see it opened.
Willis (#267),
What a lovely and poetic analogy!
Table 1 of Koutsoyiannis and Montanari [WRR, 2007] quantifies one of the consequences of your counter-intuitive, but nonetheless correct (IMHO), observation:
[italics mine].
To All,
I buy all contrubutors to this thread a drink. I also extend my thanks.
I am only halfway through the posts. This thread should become a climate science 101 read. I have been at it all day long. Every post has been worthy of perusal.
It is fun to read posts from rocketeers, quantum mechanics, climate scientists to old engineers.
Am I wrong in contending that there seems to be the beginning of a cascade of evidence descrediting contemporary global warming mantra.
Again, I truly appreciate this forum and all the contributors.
PS – Bender gets a case of Chivas Regal. Does the dude ever sleep? If not, then this will help:) …
Bender: “This is where I see DrK’s paper kicking in. The error propagation model is being assessed, and if climate is to become more predictable at longer timescales, we should see the error “flatlining” or reducing at some scale. But it simply doesn’t; the error continues to grow even at the 30-year scale. The error is at a minimum at shorter scales.”
Aghhemmm!
Guess the source.
Gavin may say the Dr. K’s results are trivial but he wasn’t all that impressed with Hansen’s logic. For models to truly model climate various models have to be averaged with reasonable uncertainty factored in the results.
Hansen’s models use 4.0 degree C as a basis for sensitivity. He admits he use 4.0 degrees C implying he may be over estimating. Why the heck is someone not adjusting estimated sensitivity to fit the results?
Please note that the geologically inclined are watching all this from the sidelines, many in rocking chairs. They snicker amongst themselves at the silly, at least in their geologically defined terms, of the climate scientists and their 0.7 degrees and a 1.7 m of sealevel datum change.
They seem overconfident to me, but geologically speaking, are they? And if not, then why the uproar over a degree C of warming. Several hundred feet of sea level change have happened before, recently during the assent out of the last ice age.
I personally want the most competent geologist as my right hand man.
PSS – I have to agree w/ Scott in WA
Having not met any of these people, but only reading their posts and replies to emails, they portend an attitude that is not only obtuse, but clickish and disrespectful. More like juvenile video game software kids.
Paolo M, #111: Has that paper, “Oceanic Influences on Recent Continental Warming”, been published yet?
Abstract
Evidence is presented that the recent worldwide land warming has occurred largely in response to a worldwide warming of the oceans rather than as a direct response to increasing greenhouse gases (GHGs) over land. Atmospheric model simulations of the last half-century with prescribed observed ocean temperature changes, but without prescribed GHG changes, account for most of the land warming. The oceanic influence has occurred through hydrodynamic-radiative teleconnections, primarily by moistening and warming the air over land and increasing the downward longwave radiation at the surface. The oceans may themselves have warmed from a combination of natural and anthropogenic influences.
Compo,G.P., and P.D. Sardeshmukh, 2008: Oceanic influences on recent continental warming. Climate Dynamics, in press.
Must read. Can’t wait for the RC review.
Dr. K and all, thanks for your thoughts. bender, you say:
An excellent point, and one which I had in fact forgotten …
w.
I’m taking my case of Chivas Regal down to the beach and start a fire with these spare IPCC reports that no one wants to read. Anyone else in?
I am obviously in. I am going to take that case of scotch after you fall asleep.
I think what we need is the International Journal of Computational Climatology.
A more nearly complete statement, as I understand it, of the current position relative to chaotic response, weather, and climate is as follows;
It is a strange situation when it is specified up front that the calculations do not correspond to the nature of the physical phenomena and processes that are the objective of the modeling/calculational approach. How can it be that climate is not chaotic, but every calculated realization of climate is chaotic.
The very foundation of GCM application procedures are based on this assumption. Some would call it an hypothesis, but I think that nomenclature implicitly assigns far too much creditability to the situation. It’s at best an EWAG and very likely is just plain wrong. There is no theoretical evidence that I am aware of to support the assumption.
Importantly, the entire concept of ensemble averaging follows from the assumption. All calculated results by all GCM models and codes and application procedures can be a part of the processes. There are no basis or protocols available to eliminate any calculation. Even tho none of the calculations may contain the range of states obtained by the actual physical system.
There are no procedures applied to the calculated numbers that attempt to determine that the results display realizations of the physical states of the actual physical system. Additionally, the temporal variations in a global solution meta-functional are assigned to ‘weather noise’. This ‘weather noise’ is assumed to be obtained from the calculations even tho the models/codes/application procedures do not resolve ‘weather’. Isn’t that much like assigning ‘chaotic looking’ calculated results to relativistic effects when the fundamental model equations used in the calculation do not include relativistic effects. “See those wiggles, that’s relativistic noise.”
Until it can be determined that the states calculated by GCMs correspond to states of the actual physical system there are no basis whatsoever to the assumption that ensemble averaging all these numbers, without consideration of the actual state of the physical system, can lead to valid numbers. Averages of incorrect numbers cannot ever give correct numbers. If, for example, all the calculated numbers fall outside the range experienced by the actual physical system of interest, no averaging procedure of any kind can make the numbers agree with the state of the physical system.
There is no a prior way to know that the system of continuous equations, (a system that is comprised of PDEs, ODEs, algebraic equations, plus discontinuous on-off switches plus discontinuities in many of the aspects of the physical system, in addition to the discontinuities introduced by the discrete approximations applied to the continuous equations and the solution domain) has chaotic response properties.
The appeal to ‘chaotic response’ is also used to avoid the hard, but critically necessary, work of investigating all the crucial aspects of computational methods; consistency, stability, and convergence. These concepts, the very foundation of all other computational applications, aren’t even paid lip service. Again, given the lack of appreciation of the importance of these concepts, how are we to know that the presented results have any relationship whatsoever to actual solutions of the continuous equation system? Algebraic IF-THEN-ELSE constructs, for one example, are easy ways to keep calculated numbers within bounds.
Verification of the coding of the equations and Verification of the numerical solution methods are absolutely required before any calculated numbers can be considered to have any relationship to the continuous equations. It is well known that no GCM has yet to be capable of demonstrating independence of the calculated numbers from the temporal and spatial resolution of the discrete approximation increments.
Given the lack of any fundamental basis for the guess that the numbers calculated by GCMs are chaotic realizations of a physical system for which chaotic response is not obtained, and given that the coding and numerical solution methods have not been Verified, on what basis are the calculated numbers assigned to physical properties of the system?
The existence of the potential for chaotic response is not good enough, in my opinion.
#280
Always enjoy your posts, Dan.
The hope, presumably, is that the chaotic individual GCM realizations, when averaged, produce an ensemble where the deterministic randomness that must ensue averages out enough across the globe that external forcings will dominate the global signal at all time scales.
If that is the hope, then the question is: where is the proof that this is the case? They assert it, but do not prove it*. (That is one of DrK’s central points.)
*Not only that, they use the term “ensemble” to mean something very different from what it means to a qualified statistician. They do not study “ensembles”, sensu stricto.
RE:277
Hurst is extremely sensitive to sampling rate and sample size. For discrete time series its only valid over a finite range of scales.
Is “Weather is chaotic, climate is not” a true statement?
Well, being a practical sort of guy, I just went and got the GISS ER 20th century hindcasts (1880-2003). I chose that because a) there are nine runs available and b) the GISS model is one of the more complex models and c) it’s one of the longest historical runs (n=1488 months). I took the Hurst (aggregated variance) coefficient of each of the runs separately.
Then I averaged the data, and took the Hurst coefficient of the average. Here’s the results:
[1] “Run 1 : 0.92”
[1] “Run 2 : 0.94”
[1] “Run 3 : 0.95”
[1] “Run 4 : 0.91”
[1] “Run 5 : 0.92”
[1] “Run 6 : 0.93”
[1] “Run 7 : 0.94”
[1] “Run 8 : 0.89”
[1] “Run 9 : 0.93”
[1] “Average : 0.93”
The Hurst coefficient of the average is about the same as the average of the Hurst coefficients … which is only a single data point, but which makes the statement that “Weather is chaotic, climate is not” less probable for modeled weather and climate …
w.
re problems estimating H
http://www.climateaudit.org/?p=3361#comment-283125 #60
http://www.climateaudit.org/?p=3361#comment-283200 # 65
http://www.climateaudit.org/?p=3361#comment-283642 # 84
http://www.climateaudit.org/?p=3361#comment-290178 # 250
The problem I see here is that in [1] it is assumed that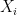 is a stationary process. Then, when using Eq. (3) of [1] with 1/f or 1/f2,
is a stationary process. Then, when using Eq. (3) of [1] with 1/f or 1/f2,  does not exist. Allan Variance includes difference operator to get rid of such a problem.
does not exist. Allan Variance includes difference operator to get rid of such a problem.
[1] Koutsoyiannis, Hydrological Persistence and the Hurst Phenomenon
Re # 260 Tom Vonk,
I suspect we agree with each other apart from some small defintional and applicability differences. To be fair, the whole Paltridge paper should be read. There is great material on feedbacks.
An analogy with your “packaged” eddies: Biologists know that human cells are complicated, yet they “package” them into entities for ease of handling. In the vast majority of reproductive cases, initial bundles of human cells emerge as complete people, who have many characteristics in common. However, I have not seen a quantitative description of the influences that cause a homo sapiens and not a pixellated tiger to be produced.
The cell might be labelled “weather” if that helps the thinking, and the human is “climate”. But does it help the thinking? Is a GCM just as ambitious as deriving the mechanisms of conception (which takes only 1 testicle, owned or borrowed) to maturity of a human being?
As a long time lurker (and another lukewarmer geologist/geochemist), with reference to Dr K’s #262 and the definition of climate:
Surely the occurrence of semi-predictable multi-decadal cycles (PDO/ENSO, AMO, sun spot cycles – things that we know roughly when they are going to change, the direction of the change but not necessarily much about the scale of that change) which are known or suspected to have an effect on regional and global weather, particularly temperature, means that 30 years is far too short a period over which to judge climate variability if climate is weather averaged out for noise. A number of these cycles would have to be considered before they could meaningfully be averaged out, especially given that these cycles are of different lengths and so go in and out of phase and so at times reinforce each other and at other times effectively cancel out.
The problem is that logically then climate change (and long-term climate shange) cannot be judged on a scale less than several centuries, and that brings in a whole new scale of potential solar and orbital variations.
Anyway, back to waiting for the British summer to start.
Ian (#286) ignoring the external solar cycles or even “sun weather”, wouldn’t the other cycles you talk about be potentially affected by climate change? If subtle warming from CO2 affects the pattern of NAO shifts, wouldn’t that be detected in the climate of Albany (NY)? If not Albany, then surely in some of the 7 other places tested in the paper. I can only make two conclusions, (1) there are no predictable changes in the large scale circulation patterns (e.g. frequency, length, phase) or (2) the models cannot accurately model the changes. In the most simple example possible, the earth warms, NAO goes more negative, Albany cools. Or the earth warms, NAO goes more positive, Albany warms. Perhaps that’s too simple.
Before my sojourn into nuclear, my background was in the mineral industry —- as in Admiral Rickover, meet J. Harlen Bretz.
As I observe them, the AGW video kid’s attitude is only a surface feature of their operative psychology. The underlying psychology is that — in addition to making a decent middle class living — they are on a mission to save Planet Earth, and nothing can be allowed to interfere with that mission. So one is either with them, or against them, there is no in between. Lukewarmers such as myself are, by definition, in the wrong camp.
I will note that one of Admiral Rickover’s strongest pieces of advice, something he shared with J. Harlen Bretz, was to always maintain a questioning attitude, as in “The evidence will make its own statement, regardless of what philosphical context we view it from.”
Willis (#283),
That is a neat experiment, and, IMHO, it does show something important: The Hurst coefficient is a topological constant of a stochastic process. While (time-domain) realizations of an LTP process exhibit dramatic excursions, the corresponding fitted values of (frequency-domain) H remain relatively stable.
I would also like to comment on your earlier point:
DrK already addressed this; I would add that the existence of more than one estimator for a sample statistic should not be cause for alarm. For example, there are also multiple estimators for a sample’s central tendency: Mean; Median; Geometric mean; Trimmed mean; Averaged endpoints’ etc. Depending on one’s criteria — bias, variance, robustness, computational simplicity, etc. — and situation (i.e. distribution of the data), one might choose to use any of these estimators.
Having said that, however, I would agree that for a given situation there should be a very strong prejudice in favor of consistency and convention. IMHO, if a statistic is usually estimated in a certain way (e.g. the mean with respect to central tendency), then one should always report the conventional statistic (the mean, e.g.) even if one prefers for some reason to employ a more exotic statistic (e.g. a trimmed mean). Otherwise, there may be a lingering suspicion that a result is an artifact of statistical method employed rather than a characteristic of the sample.
DrK # 262
This is exactly the point I tried to make with the T(x,y,z,t) = Ta(x,y,z) + u(x,y,z,t) model and by saying :
Actually if we take the climate defintion of NOAA it means that Ta(x,y,z) is a 30 years time average of T(x,y,z,t) at a point P(x,y,z) .
It follows trivially by construction that the time average of u over the SAME 30 years , Ua(x,y,z) is 0 .
This way to write climate reads : weather at the point P = climate at the point P + (fluctuation/perturbation/difference to the mean) .
From this way to write a variable does not follow that climate = signal and fluctuation (or weather) = noise .
From the trivial tautology that average u cancels over 30 years (what would f.ex happen if u was random normally distributed or even if it had any kind of symetrical distribution wrt the mean) follows neither that u is a random variable nor that it cancels over any other period than 30 years .
For instance if we take ANY period of length = 30 years and if Ta(x,y,z) doesn’t exist , u is not defined .
Concretely that means that with such a definition we have only 3 points of climate data per century and that is notoriously not enough to make any statistics .
What is the climate in Bruxelles today ?
Is it an average over [1978 , 2007] in which case I will need to wait 30 years to get the next climate point in Bruxelles ?
Or is it an average over [1994 – 2023] where 2008 is in the middle in which case I don’t know it yet and will need to wait 45 years to get the next climate point ?
As we don’t deal with a Markovian process , how do we compare time averages of overlapping intervals ?
And I don’t even mention the question what are the special properties of the dynamics of the system that show that a 30 year time quantification plays a particular role wrt other possible quantifications – with QM analogy the question would be “Why are there time quanta in the climate system and why are they equal to 30 years ?”
However the time averaging doesn’t seem to be the issue because Schmidt admits himself that it is trivial to see that they get all the Ta(x,y,z) wrong .
So what might he possible mean by saying that they got the predictions right “globally” ?
Obviously it means that one must do SPACE averaging on top of the time averaging .
But that is another issue altogether that we have not mentionned here yet .
How large the space averaging ? 1000 km ? More ? Less ? It depends ?
Ta (x,y,z) can be assimilated to climate because it is well defined and because the climate is local .
But a space average of climates over a square of 2000 km side can it still be called climate ?
Obviously not because there are 1000 km between Paris and Berlin and they have completely different climates .
Montreal and Paris have same latitude and also have completely different climates .
Etc .
So the only option that is left is to space average over the whole planet (e.g averaging climates as wildly different as Antarctics and Indonesia)
And we fall again on the same question – what is the reason that space averaging wrong local 30 years averages magically produces a “gobal” unique parameter that is right , relevant and predictible ?
Tom #251
You might as well ask where the material to make the universe comes from, or debate if the universe is infinite and discuss what might be beyond the end if it isn’t. We could also always try and count how many grains of sand exist on the planet.
REAL, OFFICIAL, WE’RE NOT KIDDING MODEL RESULTS … AND “OUTLIERS”
Here’s another oddity with relevance to Dr. K’s paper. I got to thinking about the results of a model run. How often do they make it into the “Useable” pile, and how often are they thrown out as not being representative of whatever the programmer is hoping to find?
I chanced upon a partial answer to this question yesterday, while going through some GISS Model E simulations. These are available (among other places) at NASA’s data portal.
I took a look at the 1800-2003 simulations here. When I called up the map for the “All Forcings Combined, Lat-Long” (go here and click on the “Show Map” button), I noticed a curious thing. Down at the bottom of the map you can download the data in various forms. The very last one says “View outliers map as GIF or PDF.”
“Outlier’s map?”, sez I, “what is that?”
So I clicked on it, with the result shown here.
Now, the oddity in the case is this. All of the areas shown as “Outliers” are results which are cooler than the official results of the run … coincidence? I’ve checked a sampling of other runs as well, and have not found a single cases where the “Outliers” (which clearly are removed from the official run results) are warmer than the official results … they may be there, but I haven’t come across them yet.
So the question with relevance to Dr. K’s paper is, how representative of the actual results were the results that he used in his paper? Are there other runs which are sitting on the cutting room floor, adjudged (on some as-yet unknown basis) as being too cool to handle? …
Now I’m on a quest to find out what makes an “outlier” on Planet NASA …
w.
Willis: Maybe the modelers have adopted one of the special scientific principles of dendroclimatology: “You have to pick cherries to make cherry pie.”
#293 In a way they have. Their criterion is not the GMT, but whether the model converges on a realistic solution (whatever that means). But who’s to say whether the two are correlated? Maybe the warmer runs are more likely to be convergent solutions? I’ve asked before at RC how they choose which runs to toss and got no reply. Try asking again. To my knowledge it is not documented precisely anywhere. It’s an important question.
#292, 293, 294
So an ensemble average is not used; only some kind of quasi- or pseudo- ensemble average.
I prefer the pseudo designation.
lucia’s at it again:
IPCC Central Tendency of 2C/century: still rejected
This is for Scott-in-WA’s denialist colleagues – the ones who deny that the current temperature trend is flat:

No sig. rise since 1979. See July 2008 Global Temperatures. Just trying to go one better!
#298 That analysis not credible. That is not how you test for a temperature trend. lucia’s analysis is credible.
Why not? I would like to know. Lucia’s is credible too.
I didn’t say I was testing for a trend. I am testing temperature now
and temperature thirty years ago. Consider an investment.
If it doubles and then goes back down to the original price what is
your return on investment? Zero. What matters is the temperature
now, and then, not what happened in between.
#301 The test you describe is irrelevant and misleading. My advice is to quit while you’re ahead. Lucia’s analysis is not just credible. It’s correct, it’s relevant, its assumptions and caveats are well-outlined, and it’s a problem for the consesus.
I wrote to Dr. Ruedy at NASA to see what I can find out about the outliers, viz:
While I was writing it, I realized that the outlier maps did not look like averages of entire runs which had been classed as “outliers”. They look more as if an individual gridcells have been individually judged to be “outliers” (which means “too cold”, near as I can tell), and the average of these individual rejects has been removed from the results, and that is what is shown on the “outliers” map.
Now, if it is indeed the case that the “N-run ensembles” have been selectively culled and individual “too-cold for comfort” gridcells have been removed from the N-run ensemble … ooooh, I will not be happy.
w.
#292-294 Willis and bender,
Note the article “in press” at GRL:
Obviously Dr. Knutti is talking about hindcasts and not the discrepancies that Lucia is demonstrating so well in short terms trends. In the introduction he says:
Dr. Knutti starts to tred on remarkable territory:
This is starting to get interesting:
Plausible. I like that word.
Dr. Knutti goes on to compare the impact on models resuts depending on different forcing by aerosols, minerals dust, etc. I won’t go throgh all the aspects but he concludes that aerosol effects would be smaller than most models suggest. If aerosol forcings turn out to be large, then
Again Dr. Knutti ackowledges the “human observation ” factor:
Now thinking about model usefullness, the following quote struck me
He goes on with the common statement that the hindcasts cannot be made to work with natural forcings alone. Perhaps this would be more convincing if we really knew the natural and anthropogenic forcing better.
As Trenberth has once again recently pointed out, modelers seem to know well about model limitations (“George Box is credited with saying ‘All models are wrong, some are useful'”). Somehow the message doesn’t all come across as clearly as this in most policy documents.
For me, one quote sort of sums it up:
Wouldn’t this seem to suggest that “It’s the Physics” is no longer an acceptable answer to questions about models?
Over on The Blackboard, bender and lucia are now in direct communication with the temperature flatline skeptics. With any luck, it will be a most interesting and productive discussion for all concerned, assuming these flatline skeptics choose to stay engaged.
A word of warning coming from my “nuclear side of the house” type of perspective:
One cannot place absolute trust in data and in analyses which have not been subjected to a reasonably tight Quality Assurance program of some kind, one which is based upon a graded approach and which is commensurate with the potential public safety impacts and potential economic impacts of a quality assurance failure in either the data or in the analyses.
Remember too that in the world of nuclear, a failure in the Quality Assurance program is viewed as being every bit as serious as an actual quality assurance deficiency in the Q-listed system or component itself.
Tom, thanks for the equation, RC should use the same in their response.
The 1/f noise problem, block averages are not easier to predict than the original series, might exist in space as well. Take two thermometers that are separated 100m. Is the difference in annual average of those thermometer readings of the same magnitude as annual NH-SH ? (Just an example, I don’t know the answer )
It’s not “the physics”. It’s “the tuning”. Here’s the Kiehl on tuning GCMs thread for context.
Hi bender,
Too right. Dr. Knutti quotes and parallels Kiehl. Now that it’s established “it’s the tuning”, it would seem to be time to have some clear expositions of how the tunings and paramerizations were made and how models are established to be “useful”. When Dr. Knutti says “it is impossible to know what decisions are made in the development process of each model”, I guess he doesn’t mean it’s theoretical impossible, just that he wasn’t there and doesn’t know. Who was there and who does know?
#308
When I asked Gavin Schmidt about this at RC he denied the role that tuning plays in getting the backcasts fit so well. Ask others and they’ll tell you “it’s an art” – which, for a scientist, is the ultimate dodge. Tuning models to past data should impress no one. Correct forecasts are what are impressive. And you see what lucia is obtaining. Our familiar friend: divergence.
#292 — Willis, throwing out the cool outliers was exactly what the ClimatePrediction people did in preparing their 2005 Nature article (Stainforth (2005) Nature 433, 403-406). So, maybe that’s standard practice. Everyone knows for absolute sure, after all, that increasing CO2 *must* increase global average temperature.
CP rationalized doing so on the basis that cool runs (nearly 50% of the control runs) were not realistic and reflected, e.g., the simple slab ocean in their model. Of course, the simple slab ocean didn’t obviate the hot runs they kept. The maximal 11 C of centennial warming they reported still gets bandied about as a likely possibility.
#302 — You get to make oracular pronouncements of truth, bender? David is an honest researcher. You owe him an analytical answer, if for no other reason than pedagogy. We’d all benefit from that.
UC,
From Dr.K’s comment above (#264), it seems the ASD method is not suitable for H .gt. 1, compared to the R/S method which is not reliable for H .lt. 1.
(Sorry about the fortranisms, I don’t trust wordpress with the greater-than or less-than symbols. I really should use TeX)
Spatially, at small scales, I think there is evidence of spatial 1/f behaviour in the tropics but less so at higher latitudes. Possibly related to tropical convection processes, turbulence over the equator etc. Mainly IMHO at the moment, although there are one or two studies which hint at this (I did try and link one paper on a few occasions but the spam filter seemed to take issue with it)
Well, kudos to Dr. Rito Ruedy at NASA, who has been very quick to reply to my question above. He says:
So, the answer is that they are not outliers at all, just a different way of color coding the same map …
In any case, this is the kind of co-operation that makes science much easier. I appreciate it very much, and I acknowledge Dr. Ruedy’s prompt, cheerful, and detailed response.
Perhaps he could give classes in scientific communication to some of the more recalcitrant members of the tribe …
Best to all,
w.
#311 Anyone claiming that they’ve proven something must show that their work is correct. So, I’m sorry, but the burden of proof is NOT on me to fix someone else’s work. I’ve told you what’s wrong with the analysis Stockwell linked to: it was a comparison of one year to a bunch of other years. How is that relevant to the question of GHG caused AGW trend? I’ve told you what a proper analysis looks like (lucia’s). I’ve not called anyone dishonest; I merely claimed a particular analysis was not credible. By your standards you now owe me an apology on two counts: for the use of the word “oracular” in reference to my clear and substantive criticism and for suggesting I called anybody dishonest.
But to answer your question: no one gets to make oracular pronouncements on truth. That’s the Royal Society’s motto.
Now – at the risk of going OT – are you trying to tell me that you think temperatures haven’t risen since 1979? A distortion of that magnitude would be noteworthy.
Stockwell says:
This is nonsense. Two observations don’t tell you anything about what climate is doing, let alone why. I don’t owe anybody an “analytical explanation” for something that an 8th grader understands. Two datapoints gives you one degree of freedom, which gives you no ability to make any kind of inference whatsoever. The end. I suppose I now owe you a lexical analysis of the meaning of the word “inference”?
Do not insult me further by insisting I respond to trash. There is not enough time in the world to correct all the nonsensical propaganda floating around out there. Anyone who wants to argue that temperature did not rise through the 1970s, 80s, 90s is most assuredly using highly torqued data processing methods that an undergraduate could debunk in 10 minutes.
I will ask Steve to snip this discussion as it is off-topic and risks developing into a foodfight.
The only reason I mentioned lucia’s analysis in the first place is because she is seriously interested in addressing DrK’s LTP problem. Stockwell is a big boy and can defend himself. He’s the one who chose to post here, OT. He knew there was heat in this kitchen.
“Perhaps he could give classes in scientific communication to some of the more recalcitrant members of the tribe ”
But haven’t they been silenced by the Bush Administation? No point them learning to communicate if that’s the case 😉
(Sorry, couldn’t resist the open goal).
Perhaps though if Hansen and his colleagues were as clear and forthcoming in their descriptions and documentation of code as Dr Ruedy, they would get much less flak about their revisions of the past and about the ‘tuning ‘ of models.
Hi All, The reason I did not respond to bender is that I have a policy of not arguing,
as I don’t think it serves any purpose. I may take up the issues of
LTP and wandering sets in dynamical theory elsewhere,
as I think it is an interesting and relevant generalization
of the GHG questions at issue.
#314 — bender, regrets about using “oracular.” I didn’t mean any insult. Nor did I mean to imply you were calling David dishonest. By “honest researcher,” I only meant that David does serious work and deserves a serious reply. I’m sorry there was so much misunderstanding and for upsetting you so. That said, your dismissal seemed very peremptory to me. That Lucia does very good analyses does not mean that other approaches to analysis are invalid or trivial.
David showed the entire trend in temperature, and the normal curve comparison included the entire 30-year July data set, not just two datums. His point seemed to be, in part anyway, that after 30 years the difference in temperature is no more than a fairly ordinary yearly transition one sees every 8 years, on average. A similar case could have been made after 10, 13, and 20 years, e.g., and in the negative sense at 4, 7, and 14 years.
Sure there has been warming over the last 30 years, but one point raised by David’s analysis is whether the warming passes the ‘So, what?’ test. Maybe the recent time series is little more than a random walk, with a bit of a trend here, and another one in opposition there.
#311,
If it’s developling into a foodfight, it’s only because you are being quite rude. No one asked you to fix anything. No one even asked you for a response. You chose to do so. And if you choose to respond, then you should do so appropriately and not come off like the second coming of Gavin Schmidt.
Sorry, that was 314 Bender, not 311 Pat Frank.
Well, I now have to apologize to the modeling folks at NASA about comparing their scientific principles to those of the dendros. Mea culpa, mea culpa, mea culpa.
Bender@314
Can you please clarify that? In my naivety, it would seem that no significant rise since 1979 would imply that the heat content of the system now is the same as the heat content in 1979. All heat added to the system since 1979 has subsequently been lost. Intuitively, I would think that global warming has to now “start over” from the 1979 starting-state. What am I misunderstanding?
Thank you.
And what would be the proper way to test that hypothesis?
scp: prove it.
All incorrect statements merit correction. And honest analysts seek to be corrected. So I disagree. But are you suggesting it’s ok to let errors pass as truth?
Call me rude if it makes you feel good. All that matters is correctness. If I say something incorrect, let me know. Like I said: science is bloodsport.
jae, do you have anything substantive to add, or just your usual cheerleading shlock?
Jonathan Schafer says:
But note when bender said:
David Stockwell replied:
So, Jonathon, you are wrong. David asked to be corrected. No need to apologize though.
Prompted by the number of comments here I revisited the site noted by Stockwell just to be fair and make sure I didn’t miss anything in that, errr, analysis. I stand by my statements. That is high school trash. Consider it your homework to explain why. If you can’t do that by now you’ve not been reading the blog as it should be read.
Sorry for being rude. Sorry for sounding like the oracle. But trash is trash. David should take lucia’s method and apply it to his data and report the result. That would not be trash. It would be correct. Beyond distortion. His analysis is a tortured distortion and his interpretation is absurd.
If anyone here thinks it’s so insightful, why don’t you post it at RC and see what kinds of comments it generates. That would be fun.
#324 — bender wrote, “Like I said: science is bloodsport.” Several years ago, Carl Djerassi, a very prominent chemist, wrote a letter to Chemical & Engineering News, saying that science was about “Nobel Prize lust.” He was wrong, too. Science isn’t about lust for glory or a sport, certainly not a blood sport, no matter that greedy personalities or kill-players enter it. Science itself is about objective knowledge for its own sake, and nothing else. The juvenilities or perversities of individual scientists notwithstanding.
The point is, bender, you didn’t correct David’s analysis. You just dismissed it with asperity.
Re: #322 — You tell us. You’re the expert.
Pat Frank:
1. The correct approach is lucia’s. How many times do you need me to repeat it?
2. You have failed to explain why Stockwell’s analysis is correct and meaningful, and why his interpretation is not retarded. You keep trying to shift the burden of disproof on me, when I assure you that the burden of proof is with the proponent.
3. “Objective search for truth” requires a clash of models. A clash of ideas. A clash between data and theory. And most often a clash between individuals, labs, research groups or whole paradigms. If there’s no intellectual blood being spilled, you’re not trying.
4. Oh, you’re quite an expert yourself. Please justify Stockwell’s methods if they’re so easily defended.
Go ahead and have the last word.
bender, Pat Frank, and everybody else — please else step back a minute and take a look at the big picture.
Climate Audit has reached a plateau on which many are still fighting in a cowboys-and-indians mode, but who have not yet gone forward pursuing the real work of building a nation.
To build a nation, you need railroads. This means laying railroad track that has a starting point and a destination.
A knowledge management engine is needed which links the starting points and the destinations of each climate study, and which links each central tenant of those studies to their specific supporting information within the reference body of applicable scientific knowledge.
The goal is end-to-end access and auditability of the scientific knowledge and processes which go into forming some set of intermediate and final conclusions about the earth’s climate and where it might be headed.
Re #321
That it not about the ‘heat content of the system’, it’s about the the thermal profile of the atmosphere in response to solar input to the ‘system’. The atmosphere doesn’t take years to respond to a change, consider the difference between night and day temperatures.
#324,
No Bender, it doens’t make me feel good to call you rude. It’s a simple statment of fact that your responses to David Stockwell and now Pat Frank are inappropriate. I don’t see that calling someone’s work trash and retarded adds anything to the discussion. It may or may not be quality work, and you certainly have a right to criticize it. All work should be looked at with a critical eye. That’s how science moves forward. But not by the disparaging comments you offered.
Telling someone why you think something is wrong isn’t fixing it for them either. You may in fact be the person who is wrong. That’s what discussion is all about. Coming to conclusions after presenting many arguments and accepting or rejecting the work. And frankly, a good reviewer would help in fixing things if the originator agrees with the criticisms and applies it to his/her work.
Do as you wish, but don’t be surprised that people are put off by your attitude. It certainly doesn’t help foster the type of scientific cooperation that seems to be lacking at other sites and in research in general.
Pat Frank says
One person’s perspective. By no means is that either proven or universally held. Recognizing that the question of what science “is about” can incorporate methods, purpose, and goals, means this can become a far reaching discussion (quite OT in this thread 😉 ).
Whether the verificationist Bacon, or falsificationist Popper, they saw science as providing insight for a purpose, whether the value of knowing God or the value of prediction. (Popper said he was partly motivated by frustration about Marxism, for example.)
In fact, knowing that you much appreciate falsificationism, I’ll comment that falsificationism is fundamentally about proving what we do not know. I.e., a falsification purist would say we cannot know anything scientifically, we can only prove what is false.
Reminds me of the story about sculpting: it’s the simple process of removing everything that’s not part of the final image.
And with that, I’ll bow out 🙂
(Re: several requests for knowledge management, etc… I do hope to soon have time to set up an appropriate engine in CA. Perhaps today? We’ll see what distractions come my way.)
# 240
Bad analogies are like feathers on a snake.
Spence #312,
Hmmm, more points to Allan Variance then 😉 As stated in #264, additional research is needed. This stuff is by no means limited to climate science, that’s why I’m interested.
Re: 330 and 321. What was the “thermal profile of the atmosphere” in 1979? What is it today? How does this term differ from “heat content of the system”? !979 VS today? Anyone. Thanks in advance.
What I see in David’s observation, it’s just looking at things in a different way. Rather than dealing with trends, instead we ask how much has the TLT satellite brightness temperature vertically relative weighted average changed in absolute levels, compared to what we’d find year to year or within groups of years.
In absolute values, and I’m assuming the change and SD are correct, David’s simply observing that the value for TLT of .295 over the period is not significant compared to the year to year SD of .252
Now what value one puts on that observation is another subject. It doesn’t make looking at it this way wrong, just perhaps not particularly meaningful. To me it’s interesting if the TLT is at the same place now as it was over the entire period. Some don’t find it interesting it seems.
But I like trends. According to RSS/MSU, from 1979 to Jul 2008, the TLT trend is .17 K per decade (Christy and Spencer, .147) But there are 3 other bands. Although I’m sure they need to be averaged or weighted or corrected or something and you can’t just add them. That would be too simple. But I’ll do it anyway. If you add the trends for all 4 since the MSU started, you get a total trend of -0.084 a decade over the last 30 years.
TLT .17
TMT .097
TTS -.016
TLS -.335
So the trends added show a total “cooling”. But as they say elsewhere:
330 Phil.
I basically agree, it’s about thermal response (as a proxy for heat content AKA energy levels) from readings/calculations of the atmosphere’s thermal profile in bands, if we’re speaking of satellites. In the case of the land/sea, the ground via air samples from randomly placed station of various density and and sea via shipping lane surface water samples. These responses over time form the anomaly, which then supposedly reflects energy levels in the form of temperature levels.
What it actually reflects? Who knows. I’m not impressed by trends of +.05 or -.08 per decade regardless, so it doesn’t really matter.
I will attempt a move toward the “power of numeracy” for the discussion about David Stockwell’s post on “July 2008 Global Temperatures”. It seems to me that what David has done is a special case of application of the test statistic D_i,l(k) := X_i(k) – X_i-l(k) that is studied in Koutsoyiannis and Montanari (2007), based on the earlier work by Rybski et al. (2006), for testing whether or not a climate variable X(k), defined on a timescale k, has changed in a statistically significant sense, over a period of l years. As we observe in the paper, this has some advantages over the more common linear trend tests, i.e.: (1) D_i,l(k) does not depend on a fitted model (as e.g., a linear fitting to the data); (2) it is flexible and convenient as it allows choosing the climatic timescale k and the lag l/k (defined on scale k); (3) it yields a simple, general (not dependent on the process type), convenient and exact expression for the standard deviation of the test statistic (equation 10 in the paper). This expresses the standard deviation of the test statistic as a function of the standard deviation sigma(k) of the process X(k) at scale k and the autocorrelation coefficient rho_l/k(k) at scale k and lag l/k, both of which, however, depend on the process type, i.e. its autocorrelation function (unfortunately, there is a typo in the published paper: the subscript l/k in rho has been printed as l,k).
David has assumed scale k = 1, which is not a climatic scale, but I do not see any reason that his question whether or not there is a significant change at the global temperature in July during the last 30 years cannot be asked/tested. Second, it seems that David’s calculations of the standard deviation are indirectly based on the lag one autocorrelation (he calculated temperature changes for each July to July). If he used the lag 30 autocorrelation as in equation (10), it seems that the standard deviation would be even larger (notice the term 1 – rho_l/k(k)), which would render the observed change less significant.
Equations to calculate sigma and rho for any scale and lag are given in the paper for both the AR(1) and the SSS (simple scaling or Hurst-Kolmogorov) cases.
Heat content of a volume of air is a function of temperature, humidity, pressure and velocity. Temperature alone doesn’t tell you all that much. The heat contents of the hydrosphere and cryosphere are much larger than the atmosphere. Heat can move into and out of the atmosphere from the other reservoirs quite rapidly, El Nino/La Nina for example. If anything bender is understating the point, two points don’t tell you anything. Adding a column of figures for layers of the atmosphere where pressure and humidity differs by orders of magnitude tells you even less.
bender,
You may be brilliant, or simply deluded. Nonetheless your insistance on leaving a steaming pile on the front lawn of every discussion merits your inclusion in my mental killfile. Whatever insights you may provide just aren’t worth the price of putting up with you.
Do any of the folks dismissing David Stockwell’s approach have a response to Dr K’s post in #337? Hopefully one that is not just opinion and is temperate.
For those wondering about RSS/MSU TLT, instead of going Jan 1979 – Dec 2007, Jul-Jul removes an average value for Jan-Jun 1979 of -.246 and adds Jan-Jul 2008 of +.027
One question I do have for David; You said the data is from RSS/MSU TLT satellite measurements. But you say ‘when you calculate the global surface temperatures’; are you using lower troposphere or surface? Or are you treating the lower troposphere as equivalent to the surface? I don’t agree with that.
I graphed out that period from the RSS/MSU TLT anomaly for atmosphere over both land and ocean, for Jul 1979-Jul 2008 and the trend is -.16 to +.32 or .48 7/79 to 6/80 averaged .012 and summed to .14 — So I’m wondering where you got .295 from.
#312, 334:
Does H .gt. 1 really have any meaning? Note that H characterizes two closely associated processes, a self similar process and the process of the stationary stationary intervals of the self similar process. The former is the cumulative of the latter and obviously is nonstationary, whereas the latter is stationary. But both are characterized by the same value of H, in the interval (0, 1). More details in Mandelbrot, B.B. and van Ness, J. W. (1968) Fractional Brownian motions, fractional noises and applications, SIAM Review 10(4), 422-437.
I know that several researchers have published values of H greater than 1, but I think this is a misconception and relies either on treating the cumulative process as if it were stationary or on deficient algorithms for the estimation of H.
I think the simple approach of asking what was it like then compared to what is it like now is a valid way to express a possible change. This is exactly the method used in the UK to state the annual inflation rate. You take the price index from the same month a year ago and compare it with the index for the current month, ignoring whatever changes may have happened in the intervening months.
This clear and understandable procedure was adopted many years ago for public use to prevent political rows about various ways of calculating inflation. On one notable occasion, there were three competing methods giving wildly varying results. One took the change from last month to this month and multiplied by 12, giving an answer of around 30%. The second was the simple one and showed about 5% and the third, which fitted a linear trend through all the monthly data points, showed about 2%. Of course, the government preferred the 2% figure, and the opposition, the one showing 30%. 🙂
Let’s put this in terms of hypothesis testing. If your null hypothesis is that some measure of global average temperature hasn’t changed since 1979, then I’m reasonably certain that having the same temperature in 2008 as 1979 means you cannot reject that hypothesis. But that’s a long way from saying that it proves that the temperature hasn’t changed, which is how I read David Stockwell’s post. That’s a different hypothesis altogether, specifically, the temperature has changed by some amount since 1979. The same two temperatures alone are insufficient to test that hypothesis. You need the statistics. Dr.K provided a valid approach to calculate the relevant statistics from the data from 1979 to 2008 to test the temperature change hypothesis using a point in 1979 and a point in 2008. David Stockwell didn’t and bender called him on it.
335 Joe Solters:
To answer your questions.
I would define the “thermal profile of the atmosphere” as the satellite readings of the brightness levels converted to temperature/anomaly.
I would define the “heat content of the system” as a measurement of the energy levels of the seas, ground and atmosphere combined.
Merged land/sea doesn’t track the atmosphere, it tracks surface temps by proxies, air temps from digital sensors ~5 feet up for the ground and (however deep they go) engine inlets in water. So to answer the question of the atmosphere, we use the satellites.
RSS/MSU has (ballpark from graphs) from 1979-2007 Ref: http://www.remss.com/msu/msu_data_description.html
TLT – Lower Troposphere 1979 -.3 2007 +.1
Change +.4 Trend +.51
TMT – Middle Troposphere 1979 -.1 2007 0
Change +.1 Trend +.28
TLS – Troposphere/Stratosphere 1979 +.5 2007 -.5
Change -1 Trend -1
TTS – Lower Stratosphere 1979 N/A 2007 -.2
Change -.4 Trend -.48
TTS starts in 1987 at +.2
All are from 82.5S-82.5N except for TLT 70S-82.5N
#341: The file is
TLT
David: Irk, seems that got cut. I’m just curious what you were using, since nothing I came up with was .295 I am guessing you’re just using land, but I thought it would be easier to just ask than to hunt. 🙂
But onto other things. What are we trying to accomplish? What are we looking for? The question to answer is “What are human activities doing to the amount of energy on the planet?” Isn’t it?
The closest we can probably get would be to combine the global mean temperature anomalies for the two, land/sea and atmosphere. If one is satisfied the anomalies of samples and calculations of various temperatures reflects the heat content (I’m not).
But let’s say they do (they could, right?) The last 30 years, the decade trend:
Satellite: -.084
Land/Sea: +.160
So the rise in the anomaly trend for both is +.076 C per decade, or a “temperature increase” of .228 C over the last 30.
The nice thing about combining the sat anomaly with the land/sea anomaly in 1979, we get rid of all the pesky past readings with buckets and thermometers and pretty much only include engine intakes and digital sensors. So we’re not splicing one set of instrumentation and methods with another. Pretty much…
For those who think AGHGs are a major portion for this, you may be interested in knowing carbon dioxide’s gone up 46.83 during the same time period, or ~14% of 1979 levels. That’s about 1/7th of a doubling.
So if carbon dioxide were 100% responsible for whatever the anomaly trend does, looking at the last 30 years, going from 337 ppmv to 674 would give us a sensitivity of 1.4 C for a doubling.
Or should I say, the last 30 years of sat/air/water anomaly data shows at most a 1.4 C for a doubling. Unless the anomaly stops showing a seeming switch back to lower monthly and annual numbers and resumes its march towards +.1 Will the trend accelerate on its apparent continually upward rise in the future? Assuming there’s any correlation or causation between AGHG and anomaly, with the anomaly following that is.
Whichever, here’s the last few years of Jan-Jul only:
2004 .57
2005 .76
2006 .60
2007 .75
2008 .48
FYI, 2000 was the last year the annual anomaly was under .48
So if you’re of the opinion there is correlation, causation and sign, and the opinion is that carbon dioxide is 50% of the anomaly rise or fall, then it all shows a .7 C for a doubling or halving.
Unless of course the anomaly is vastly understating (underreflecting) any change in energy levels, they’re much higher than thought, and the AGHG play a much larger role in energy levels.
I feel like I’m trying to figure out what the stock market will do in the future based upon past performance.
Sam,
Exactly. It’s not whether you have a paper gain or loss on a given day, it’s whether to buy, sell or hold. Unless you have a large profit or loss or have something better to do with the money, I suspect you would be unlikely to make that decision based just on your purchase price and the price today. And it’s still a bad analogy.
I will put the file at the bottom in case it gets cut again.
This is running really slow for me. It think you are using
6 month averages, while I am using month of July values.
I will post some code next time.
DrK’s reference is helpful for putting more rigor into it.
He expresses exactly my aim in his point 1. post 337,
a statistic that does not depend on the fitted model.
That formalizes my sentiment, that it does
not matter what happened in between
the two temperatures. It makes more sense to me to use
the statistic he proposes in an LTP setting than to use trends.
The issue is that the ACF or partial correlations do not vanish
in LTP, as they do in AR(1) and iid series, and that violates
linear regression assumptions.
#344: I didn’t say I proved anything. I can see I,m gunna hafta though.
Here is the file:
You have a set of data points over some period of time. You trend those points. You then are sure since the data points have a linear trend that’s up, it will continue short term. So you plot the stock price for company A 1880-1944 and see that trend! Of course, you’re also ignoring 1900 1915 and 1926…. And not using a moving average…. And not looking at company fundamentals…. 🙂
Anyway, you buy the stock in 1944, and then wait until 1981, to get back, right?
Maybe we’re in for another 1944. Maybe not. Maybe Cisco stock looked like a keeper in late 1999 and early 2000. Turned out not to be so; the only question is how much did you lose, or have you just been flat for the last 10 years.
So the analogy I’m making is a fine one; 130 years of climate change with a general upward trend is no promise of another anything. Opinions on the future based upon a foundation of guesses and incomplete information that may easily turn out wrong, that can turn out to be true or turn out to not be true.
Correct or incorrect guesses on outcomes of chaotic random long-term multi (infinite) variable systems.
Or you can call them proven or disproven. 🙂
#347, 348
If you’re still holding a stock that hasn’t moved in 29 years, your stock broker needs a new model.
That last one #350 on the guessing the future based on incomplete and highly variable informationwas for DeWitt….
David My #347 is GHCN-ERSST for Jan-Jul means to show that so far this year is the lowest so far of this time for the last 5 years, at .48 It’s not satellite nor a trend.
For the satellite trend, I am using that same TLT file for -70 to 82.5 as on your FTP site (that I got from RSS/MSU today). (The spike for Jan-Sep 1998 is impressive!)
It’s maybe the processing, I simply took the raw data from Jul 1979 to Jul 2008 and plotted
it, -.16 to +.32 on the linear trend, for +.48
bender,
After going back and re-reading the link in David Stockwell’s original post, I commend your self restraint. The “not even wrong” comment of Wolfgang Pauli comes to mind.
Hi Sam, I just calculated the sd using DrK’s equation
for differences of statistics,
and the sd = 0.19 down from 0.25 that I got
before. Still not significant though. I will
do it up with the code so you can try it.
To be non RC-ish, I think you have to say why its trash or at least give a powerful hint, not just “an exercise left up to the reader”.
Hi All, The first thing you have to do is understand what someone
is talking about before passing judgement. I will do up the
analysis using the framework supplied by DrKs paper and
it might help. I think he is right that the post
is a special case of a more general question posed
at a range of scales and lags.
I really don’t think there is much point discussing it until I have done that.
I have been pondering this thread with regards to the claims of temperature anomaly trends for the periods 1979-2007 and 1998-2007 (or there about) and decided to do my own simple minded calculations. What I did was use the GISS and UAH time series and determined the anomaly trends (linear regression) and 95% CI (for the trends) for the time periods in question.
I know that Lucia has used monthly data that is autocorrelated and corrections for that autocorrelation using the methods of Cochrane-Orcutt in looking at temperature trends for recent years in order to determine whether the IPCC trend was in statistically significant arrears. Steve M has noted that in doing maximum likelihood calculations that Lucia’s C-O adjustments might not give CI’s sufficiently wide. UC has been known to point out that one should preferably avoid using autocorrelatrion adjustments where possible and adjust the model to eliminate/reduce the autocorrelation.
I calculated the Durbin Watson statistic (DW) for autocorrelation for the GISS time series 1979-2007 (using the residuals from the anomaly regression) for monthly data and determined a DW = 0.83 indicating a strong positive autocorrelation. I then did the same calculation for the annual data and obtained a DW = 1.76 showing neither a positive nor negative autocorrelation. From these results I decided to use annual data for the calculations I list below.
GISS 1979-2007:
Adj. R^2 = 0.65; Trend = 1.93 degrees C per century; p = 9.2E-08; 95% CI (for trend) = 1.39 to 2.47
GISS 1998-2007:
Adj. R^2 = 0.19; Trend = 1.99 degrees C per century; p = 0.12; 95% CI(for trend) =-0.61 to 4.58
UAH 1979-2007:
Adj. R^2 = 0.40; Trend = 1.41 degrees C per century; p = 1.3E-04; 95% CI (for trend) = 0.77 to 2.07
UAH 1998-2007:
Adj. R^2 =-0.11; Trend = 0.58 degrees C per century; p = 0.74; 95% CI (for trend) =-3.2 to 4.4
None of this gets me very excited and I suggest we all simmer down. I will admit to this being a layperson’s rendition and await an informed critique — of course.
Ken has now shown that there has been a positive trend from 1979 to 2007. How is it possible that there is a positive trend, yet “no difference” betwen the two endpoints? Is it true that “the points in between don’t matter”? What do you lose in cutting out those 26 points? This is a matter of signal and noise.
The stock market analogy is this. If a company’s fundamentals are sound, you do not sell in 2007 because you expect the rise to continue*. If you look at only two points you will lose the ability to make the statistical inference that the fundamentals are sound. That is why you do not ditch the 26 in between. They are informative.
[*The 2001-2007 flatline notwithstanding.]
Keep discussing. I’ll tally later who exactly left “steaming piles” when the dust has settled. All I care is who is right and who is wrong. I’ve given the correct answer 4 times now, once with an explanation. This time with an elaboration. This is not rocket science. It’s Investment 101. Ken has got it. De Witt has got it. Everyone else still in denial?
I’m not here to be your friend. I’m here to make sure you don’t take bad investment advice.
Maybe. I’m waiting to see.
“informative” in the sense of information theory. That is different from saying they are indicative. I too am waiting to see. We all are.
And if the books are cooked (ala ENE) the funnymentals mean nothing.
#328, etc. — bender, my point in 311 and 317 was not about whether David’s analysis was right, or not. It was that your dismissal in #302 was both unkind and unconstructive. Demetris has given a very transparent and constructive review in #337. His review is a model of constructive comment that is helpful to a researcher, as Jonathan Schafer pointed out in #331. You could have done that. It would have helped David with his ideas (as does Demetris’ post), and would have obviated all the commentary coming after.
You wrote in #328, “If there’s no intellectual blood being spilled, you’re not trying.”
This sort of thing happens only when researchers invest their egos into their scientific positions. The rancor that results more typifies religion or politics, where ideas are always matters of personal authority. In science, objective knowledge means right or wrong is not invested in the person, but in fact and theory. These are free of ego, and always indifferent to personal desire. Investing ego is thus always a mistake, in part because the likelihood of a crash is high. Those scientists who suffer from blind ambition or juvenile urges toward domination are those who always make this mistake. I consider them as suffering from a kind of retarded personality. Their struggles darken the otherwise clear waters of science.
MrPete, #332, if science is not for its own sake, for whose sake shall it be? As soon as science for the sake of ‘A’ is admitted, then ‘A’ becomes the dominant partner because science exists for its sake. Science is itself judged by whether it forwards or retards ‘A,’ and is no longer free. Partisans of ‘A’ are then justified to attack the careers and character of those scientists who report results contrary to ‘A.’ We see this now among AGW proponents, who regard climate science as being done for the sake of understanding and interpreting everything in terms of a human imprint on climate.
Freedom to pursue objective knowledge, which is the sine qua non of science, must mean that science is done for the sake of that knowledge alone; for its own sake.
Falsification doesn’t prove what we don’t know. It only separates what has been falsified from what has not, within the standard applied by science (invisible pink unicorns have not been falsified, but they’re not in the purview of science).
The fact and theory that remain unfalsified is knowledge because we can understand their entire meaning in a manner free from custom, culture, or personal opinion. We can even have knowledge of what has been falsified, because the discarded theory must have been precise enough to make a valid prediction. Objective knowledge of that which is wrong is still knowledge.
This is all OT and will probably be snipped. But anyway, I wanted to get it communicated. 🙂
Bender, in 358 you say, “The stock market analogy is this. If a company’s fundamentals are sound, you do not sell in 2007 because you expect the rise to continue*.” In the market world I’m familiar with those who tend to be concerned with the company’s fundamentals do not generally get too excited about any technical (statistical) analysis. If technical analysis factors into your thinking then you look for breaks in trend lines. If a stock starts at $10, goes up for a while, then returns to $10.00 , there would have been a break in the trend line at some point, and a smart technical investor would have sold at the break point, and any points in between the break of the trend line and the end point price of $10.00 are not even useless, let alone informative.
But that aside, what on earth are you talking about when you speak of a “…statistical inference that the fundamentals are sound”. Sound fundamentals are generally discerned in a balance sheet, not in any technical mumbo jumbo related to market sentiment rather than a company’s revenues, costs and stock price.
To me your stock market analogy not only fails the Logic 101 dictum that analogy proves nothing, it’s not even a very good analogy in the first place.
FWIW, I am solidly in Pat Frank’s camp here. You have to separate (ignore) the personalities and egos from the facts for science to progress (in the long run, at least). Einstein was severely hampered by the egos of his protoge’s, but, thank God, he ignored them (ironically, that hurt him in some ways). All good scientists in controversial areas must have very thick skins and a committment to truth, otherwise they take the chance of being dissolved in the goo of “consensus,” ego-feeding, and ultimately anonimity. Bender has a point about science being a blood sport. You sometimes have to be tough to be honest.
Pat, in one sense, science is no different from junk TV, to pick a particularly horrifying juxtaposition. (Got your attention :)) How? In both cases, if nobody cares, over time the process becomes unused and goes away. In other words, science will always be beholden to the willingness of people to engage in the process.
Another way of putting it: when someone says “I’m doing this only for the sake of knowledge” there’s actually a hidden minimum assumption: ‘A’ for Joe is “Joe’s own drive to Know”. It is Joe’s dominant partner. Joe is a partisan of ‘A’ and as you say can feel “justified to attack the careers and character…” of others. Not a good thing if it happens, no more justifiable than any other ‘A’. Thus, the pure freedom is lost as soon as people are involved, i.e. as soon as the process begins.
As for knowledge being embodied in what is unfalsified, it is only an assumption that unfalsified information is “free from custom, culture or personal opinion.” It all depends on the domain.
Neither assumption can be presumed true.
This is actually on topic, I believe: when people believe they are completely free from any influence and are working towards pure knowledge (but are not), and when they see their results are unfalsified and believe they are therefore free from custom, culture or personal opinion (but are not), then we get in trouble.
And on THAT point, I agree with you 10000 percent. 😀
CA is an amazing record of this. People too easily believe they themselves have no bias (but others do.) And people too easily believe that their pet idea has not been falsified because it is true (and not because custom/culture/relationship has left it in place.)
The shortest poem ever published, to my knowledge, is by Cassius Clay, Mohammed Ali:
“Me, Whee!”
Here’s a bid for second place:
“One, two, three,
Zamboni”
#365 — Pete, it’s true that science will disappear if no one cares, but only trivially true because the same thing is necessarily true of every single human endeavor. I.e., the condition tells us nothing unique about science.
If “Joe” is a partisan of objective knowledge, as you suggest, then he can not be dogmatic about content because the content of science cannot be deduced from any axiom. If facts are indifferent to personal desires, then Joe’s commitment to science as a process toward knowledge must necessarily be open and democratic because new facts will arrive from unpredictable trajectories.
The criterion of falsification further requires that Joe be not dogmatic about any known content of science, because any one of them may be wrong. These necessary positions remove Joe from any conventional definition of partisan. Joe may be partisan about science itself, but that is commitment to maximal rational freedom. That commitment can hardly lead to tyranny. Notice the use of “rational freedom.” There is no path to anarchy (pure freedom) in science, because the process of science is principled, and behavior in light of science is necessarily rational.
As an aside, there is no case to be made against that last in citing, e.g., social darwinism or vulgar eugenics, or such-like. These were not supported by the science of the day, no matter the appeals to science by the, umm, partisans. 🙂
Science is not embodied in what is unfalsified. Science is a process of theory (theorizing) and result. Both are necessarily monosemous, that is, having a single meaning. Singular meaning is a necessary condition of falsifiability.
Theory in science has its own meaning, free of what anyone may think about it. The Nernst equation in Electrochemistry, for example, E=Eo-RTlnK, has only one meaning — that of relating electrochemical potential to the contents of a solution. That meaning is inherent in the equation itself. None of the terms have any ambiguity. The Nernst equation doesn’t change anywhere, or in any alternative hands. All of science is like that. Freedom from opinion or culture is not an assumption, but a trait of science. The process of monosemous theory tested by (replicable) result ensures this freedom. Other disciplines have similar invariant knowledge, such as mathematics and engineering.
I’m not saying that people (scientists) believe they are free from influence or bias. But science is not ‘what scientists do.’ It is theory and result. You can find science in journals, not in the foibles of scientists. The process of science, test against theory, frees the results of science from bias. There is no bias in facts. There may be bias in interpretation. But when the interpretation is falsifiable, the bias is pruned away. If the process is relentless and honest what finally remains is unvarnished objective knowledge, as indifferent to the desires and foibles of scientists (or anyone else) as the sun.
I totally agree with you that we all have biases of one sort or another. We need to watch out for our own, and maybe sometimes draw attention to the bias of someone else. But the proper process always involves objective knowledge. After all, if scientific knowledge were not objective, then its use would just be substituting one bias for another. Where’s the fun in that? 🙂 It’s hard sledding, but I benefit from having my biases filed off. It’s just a hellacious experience, sometimes. 🙂
Pat Frank, the reason for mentioning the role competition plays in science stems directly from Stockwell’s original remark in #298. In response to my mention of lucia’s latest analysis, he said:
To any right-thinking scientist, this is an open invitation to comment and to directly compare the two analyses.
Re: #363
See why analogies are often a bad idea? The stock market analogy was not mine. And now Ron’s so worked up over the rhetoric he can’t think straight about how the two problems might be statistically related. The real issue is how to estimate temperature rise. Stockwell’s conclusion is irrelevant or wrong because his hypothesis is queerly chosen and his highly selective method ignores the most informative bits of data.
Yes, Pat #362, my unkind dismissal was intentionally less constructive than it could have been. Stockwell’s #298 was equally “unconstructive” because he compared his result to lucia’s, yet didn’t substantiate the comparison. The fact is: hers is right, his is wrong. And Ken #357 has now shown us why.
Doncha love happy endings, where people who make serious mistakes admit them, and we move on? I do 🙂
The topic is Koutsoyiannis and LTP. And as I was saying, lucia is trying to analyse the surface record, making use of some of his ideas, to determine if the recent temperature trend is consistent with the IPCC projection of a 2C/century rise. The early results are worth a look. Meaning: they are worthy of publication in a scientific journal – a view that is shared by Roger Pielke.
The comparisons to financial markets are getting OT and a little silly, but bender is on shaky ground when he claims that historical stock price movements are “… “informative” in the sense of information theory…” In fact, the weak-form Efficient Market Hypothesis, which is the basis of much of modern finance, posits the exact opposite – that all relevant information is contained in the current stock price and there is no informational content in historical movements. Those unlucky few of us who are involved in valuing derivatives often model this as a wiener process with a drift. The error is just white noise. While there are a few quant funds (Renaissance being most prominent) that evidently make a very good living exploiting minor price efficiencies, correlations etc, on balance the weak-form EMH has proved rather robust and is widely accepted as a reasonable approximation of reality.
I know that bender did not originate the stock market analogy, but he certainly extended it (going one better :-)) and states he is “here to make sure you don’t take bad investment advice.” Right now, I’m a little wary of investing in the bender hedge fund.
Complete rubbish, of course. Ask a trader to explain support and resistance levels, for a start.
Hardly a stunning recommendation, just now …
Yesterday, three days after EJ, I found this thread, which has been a help and a joy. Unlike him I don’t dare to say what should be in Climate 101, partly because the numeric component doesn’t have quite the same impact in the UK. But I sure want everyone to read this page – the polite bits anyway.
The BBC website had reported on Thursday the latest news from the Hadley Centre, that the first six months of 2008 were 0.1 Celsius cooler than any year since 2000. That’s what got me googling and delighting in the latest efforts of Dr Koutsoyiannis and colleagues. Thanks too to Steve McIntyre and Pat Frank for pointing so many of us to it.
As a commercial programmer and concerned citizen, not a statistician or scientist, can I reiterate the pressing need now, as the game of unverifiable software models really seems to be up, not to indulge in unnecessary personal attacks. On this page you have not just the shining example of Professor Koutsoyiannis himself but continual exhortations (not to mention excisions) to the same effect from the host. It’s precisely because this issue matters so much, policy wise, that we should be all the cooler as the sorry state of IPCC GCMs is rigorously revealed.
Apart from the help to master Demetris’ paper, the key question for me was back in #38. Is there any other reason, apart from the models (which are shown to be worthless until proven otherwise), to believe that CO2 is largely responsible for existing warming and that the dangers may increase over the next century? What might a “careful engineering quality exposition” of 3 deg C sensitivity look like?
Has anyone done the statistical heavy lifting to model how long Steve would have to be out of contact before his blog broke down into one big food fight?
bender,
Is this a correct statement?
David Stockwell’s analysis assumes the conclusion that the data are i.i.d., otherwise known as begging the question. It is not model free. The assumed model is a normal distribution with fixed mean and variance. The data are probably autocorrelated so not independent. The hypothesis to be tested is whether the process is stationary or has a trend so i.d. cannot be assumed either. The analysis is wrong and worse, highly misleading because it looks so logical on the surface.
#316 Stockwell says:
“I have a policy of not arguing, as I don’t think it serves any purpose”
Contrasting hypotheses’ fit to data is what science is. That is the purpose of arguing: to determine whose version of reality is closer to the truth. The thing is to try to constrain the arguments to data and models, avoid ad hominem. Stockwell’s policy is strange, and Pat Frank should be on him like a bulldog for it. You make claims, but aren’t willing to support them through rational argument? Bizarre.
#369 takes us even further afield, underlying my earlier point that analogies are rarely a good thing when presented to a large, diverse audience. What helps the writer doesn’t always help the reader.
#372 Barney, this is not a big “food fight”. It is a focused (albeit OT) discussion on whether one particular analysis has any merit.
This discussion could easily be brought back on-topic, by considering what kind of information is contained in the intervening years of the endpoints of a stochastic, possibly non-ergodic time-series. Each year is a new realization of the GMT ensemble, so they effectively act as semi-independent pseudoreplicates. That is why the trend anlysis is so much more powerful than an arbitrary (or worse, cherrypicked) year-to-year comparison. The trend analysis is much, much more robust to choice of endpoints (though not perfectly robust).
I would have thought this obvious to most readers of CA – certainly to someone who claims to be an analyst with a doctoral degree – and not worthy of explanation. But maybe I was wrong.
DWP, I just noticed that Stockwell #356 has asked for a ceasefire until he’s finished re-doing his analysis.
DWP, I just noticed that Stockwell #356 has asked for a ceasefire until he’s finished re-doing his analysis.
Bender @ #368 says
Stockwell’s #298 was equally “unconstructive” because he compared his result to lucia’s, yet didn’t substantiate the comparison. The fact is: hers is right, his is wrong. And Ken #357 has now shown us why.
I have major reservations about the C-O correction that Lucia uses at the link:
http://rankexploits.com/musings/2008/ipcc-central-tendency-of-2ccentury-still-rejected
To this layperson, the C-O “adjustment” for using months, and the autocorrelation thus involved, just does not seem to “punish” the CI sufficiently. I also have a problem making comparisons using these short periods of times, and even with the increased data points that monthly data provides, where the trends are not statistically significant (slope not different from 0).
Steve M mentioned in a recent post here that his maximum liklihood calculations gave wider CI’s than Lucia’s C-O method obtains.
Data points based on annual data seems so much more “natural” than using monthly data. Monthly, or even weekly or daily, data will get you more degrees of freedom for calculating statistical significance for short time periods, but unless you have an assured method of compensating for the autocorrelations you could be obtaining misleading results.
I do like the way Lucia spells out the details and explains her methods.
As ever the skeptic and aware of my own limitations,
Ken
Kenneth Fritsch says:
“Data points based on annual data seems so much more “natural” than using monthly data. Monthly, or even weekly or daily, data will get you more degrees of freedom for calculating statistical significance for short time periods, but unless you have an assured method of compensating for the autocorrelations you could be obtaining misleading results.”
I don’t see how anyone can justify using annual data if the monthly or daily data is available. If short term autocorrelations are an issue then they could be addressed by a 12 month moving window instead of arbitrarily partitioning the data based on a human calender that has no physical meaning.
Re: 345 Max thanks for taking the time. Are data available to measure (or approximate) “heat content of the system” by years? 1979 through 2007?
#375
Bender you have always been polite and resectful in your responses to me and I value your opinions. But describing someone’s conclusions as ‘retarded’ while not directly an ad hominem certainly is a less than respectful comment and seems designed to shut someone up or shout them down, rather than advance an idea.
My concern is that your ‘bloodsport’ is a too easy justification for intentionally inflammatory comments. When you really get on a jag what sometimes suffers is your message; it gets drowned out by the vituperation.
If your only concern is debunking bad science then why not do so with facts alone rather than mixing so much emotion into it? Science can be debated with collegiality can’t it? Most everyone else here seems to.
Raven @ #379
I don’t see how anyone can justify using annual data if the monthly or daily data is available. If short term autocorrelations are an issue then they could be addressed by a 12 month moving window instead of arbitrarily partitioning the data based on a human calender that has no physical meaning.
Raven, my reference to natural was the use of an entire average yearly cycle. The starting point may be arbitrarily partitioned by humans but surely not the cycle. Could you explain how using a 12 month MA after compensating the statistical calculations for its use would be different than using annual data?
You guys are missing the point. This has nothing to do with autocorrelation in data, error distributions, or lucia’s use of Cochrane-Orcutt. How many of you have actually looked at what Stockwell did? You’re telling me that it is valid to look for temperature difference by an arbitrary choice of time periods and to compare them graphically, avoiding the use of statistics?
I must be missing something. But like I said, I’ve scanned his citation twice now. Maybe someone can summarize what he did for me?
Barney, I already explained why I find this exasperating. I will not repeat it. I don’t owe anybody anything. I would not have even replied to Stockwell’s comment had it been posted in “unthreaded”. But he chose to post it here.
#382 – The anonomlies are supposed to account for annual variation. The fact that all of the statistics are based on monthly anonomlies instead of absolute temperatures makes the monthly data more ‘natural’ in my opinion.
Using a 12 MA would still give you 12 smeared data points per year. Using a single annual average leaves you with one.
#383 – I thought the same thing as use when I first looked at David’s analysis but he has another post up where he explains the mathematical technique that he is using and it appears to be more sophisticated than simply comparing two data points. That said, I don’t understand the technique and I asked him to post something that illustrates why the technique is telling us something useful.
Analysis posted. Off line 12 hrs.
Re: #385
Using a 12 MA would still give you 12 smeared data points per year. Using a single annual average leaves you with one.
My question was how would you handle an adjustment to the statistics since using a MA means you are using the same month’s data twelve times over 12 individual MAs.
Re: #383
Bender, my point was, from what I have learned about both David Stockwell’s and Lucia’s treatment of time series, that they both could be wrong, at least, from my layperson’s perspective. I would very much like to hear more from them with more details on what they have done and why they did it the way they did.
From my LP’s perspective and more specifically, what I think David Stockwell was seeking was the prediction interval estimate of an individual value for the temperature anomaly when one regresses the anomaly over time. The calculation will give a different prediction interval width depending how close one is to the average anomaly (where it is the smallest). It is a simple calculation that I can do and will do – if no else takes up the task.
The question will be does the variation fit within the model, or better, how much of a downward temperature movement for any given year(s) could we expect over the time series, given the trend.
I probably should have consulted you guys before publishing but this is my view.
http://www.associatedcontent.com/article/978728/global_warming_what_is_the_truth.html?cat=9
I think Raven makes a good point. http://wmbriggs.com/blog/2008/04/21/co2-and-temperature-which-predicts-which/ I think for us to do apples to apples, oranges to oranges, WITHOUT CHERRYPICKING, the wmbriggs point should be included. This does not mean that one cannot use, say a rolling three month temperature anomaly with a rolling three month CO2. But that in order to get the most from the data why use a year? As proof of this supposition I direct you to http://www.climateaudit.org/?p=3436 where it is documented that the “sausage” making discredits December. I ask, is December a less of a month, due to the holidays, than January or November? LOL. Where John Goetz says “In Africa, GISS tends to over-estimate December 1986 when combining records. Because the temperature is over-estimated, older records must be warmed slightly before they are combined with the present record. By introducing artificial warming in a past record, the overall trend through the present is cooled.” Why use this, as one would have to with annual anomolies, rather than monthly’s and avoid this?
Of course if you do not want to do CO2, I would say that November to November anywhere in the world at similar conditions would be better than a comparison of November versus February where summer to summer or winter to winter lag in the respective continents could cause a discontinuitity.
Stockwell’s presentation is still opaque, but lots better than before. It helps to have the script, although it isn’t well commented. This method of Rybski is foreign to me and to 99.99% of the people I know. Use of novel methods that yield a different conclusion than more common methods is always a bit suspect, but of course not fatal. If Stockwell wants us to accept this Rybski method as a better alternative to trend analysis, he’s going to have to make his case. That means summarizing the Rybski and the Koutsoyiannis papers he cites in order to explain why it works better and why it’s more applicable. I have nothing to say about this Rybski-based analysis. It is foreign to me. I don’t accept the conclusions from that analysis until I understand the method.
Re bender # 391
Why don’t you bring yourself up to steam with Rybski and the other Dr K papers before being critical of D Stockwell? I feel that he’s attempting to advance the state of analysis by providing different approaches. That does not deserve an a priori attack. David is not a simpleton, far from it. He’s Australian.
Re Willis 292 et seq., on the subject of selecting GCMs for presentations and comparison exercises, I have been writing for years that the ensemble average should include the rejected models as well as the ones polished up for maximum prestige. Why not ask Dr Ruedi of NASA if there are remaining GCMs with no obvious arithmetic or scribal errors or complex colour schemes, that have been run but not presented for averaging because they fail the eyeball test? I get concerned when I see error bounds of models narrower than actual data.
Pat sez:
I think we’re comparing apples and oranges.
Yes, in theory or in the ideal case science produces objective knowledge.
But it’s no surprise that in reality science is done by imperfect (i.e. somewhat fallible, biased, selfish, etc) people. And thus the use of science most definitely can and sometimes does substitute one bias for another. We must not assume that imagination, motive, process or outcome is 100% free from such foibles. To make such an assumption is itself a bias.
Is 95% sufficient to be useful? You bet. And that’s why DrK’s contributions are important… as you say, sanding off the biases is a Good Thing.
Well, so much for philosophy of science. 🙂
#390
I’m not critical of Dr Stockwell. Review the comments. I criticized an analysis that he presented. The presentation was incomplete to the point of being inadequate. He has improved the presentation, although it is still incomplete.
I never said he was “a simpleton”. Please stop putting words in my mouth and turning my comments into an ad hominem attack. I used the word “trash” to describe the two graphs he linked to, and the word “retarded” to describe his sophomoric interpretation of a result that is unclear to me and to many others who’ve bothered to scan his work. Do NOT attribute these judgements to the person. I’m sure he’s a terrific person and analyst. But I stand by my statemnts. The work that he linked to WAS trash. There is no way in hell it could withstand peer review. Not a chance. Now the presentation is improving, but it is still unintelligible. Ask Raven. Stockwell himself documents that the analysis and its presentation is incomplete (vis avis significance level testing). It still would not withstand peer review. It would not get past stage one because it is unintelligible. Outright rejection. (Contrast his, errr, “manuscript” with the ones submitted to CA by Loehle and Koutsoyiannis. No comparison.)
If this analysis is so darn robust and insightful, why not submit it to Nature? I’m sure it would make headlines if someone were to prove that “global mean temperature has not risen in 30 years”. If that were the case it would be the most important work done to date.
There is another paper I recall that made use of novel methods that no one had heard of, and got promoted in full glossy color before anyone had taken a serious look at it. It’s called the hockey stick paper: MBH98. Before criticizing Mann, you all should be able to recite to me the Mannomatic algorithm. Right? By your own standard.
But to answer your question, Geoff:
“Why don’t you bring yourself up to steam with Rybski and the other Dr K papers before being critical of D Stockwell?”
1. Give me a good reason to and I will.
2. As I said BEFORE you posted: I had already suspended judgement on Stockwell’s Rybski-based analysis. So your question was answered before you asked it.
Recall: the initial presentation he linked to was purely graphical. There was nothing in it mentioning Rybski.
Realize: Dr. Stockwell still has not explained his logic that “the datapoints between the endpoints don’t matter”. What kind of voodoo logic is this? Does the Rybski analysis make use of the intermediate data points (1980-2006)? Yes or no?
A read of K&M07 suggests that the newer analysis presented by Stockwell – once he actually gets it correct and complete – may have some relevance. [Although I still strongly disagree with the way he worded his conclusion above.]
One quote from K&M07 is pivotal:
“the Hurst behavior has astonishing effects in the foundation of climatology and hydrologic statistics, provided that the LTP hypothesis is true”
True. And this last little caveat is VERY important. It’s something that Stockwell must not forget to discuss in his eagerness to report a contrarian result. Even if his analysis is executed correctly, it will not possible to conclude that “GMT has not changed in 30 years”. That would be a highly misleading statement – and it is what set off alarm bells for me. A much more accurate wording would be that “the positive trend in GMT inferred by trend analysis may be a product of some LTP process, assuming such a process can be identified”.
I have no problems with the latter statement, as it is what I have been arguing all along. (Whereas I have been merely spouting that line, Stockwell is trying to illustrate it in more concrete graphical terms. And for that he should be given credit.)
The question – keeping the K&M07 caveat in mind – is: what proof is there that there is such an LTP process in the atmosphere? If you were to go to RC and suggest it is the oceans, storing heat and then releasing it at a later time to the atmosphere, you would be ridiculed. There seems not to be a consensus on the nature and source of LTP in the atmospheric time-series data. And this is a major barrier to getting LTP-based models accepted as fact.
I applaud Dr. Stockwell in his efforts to clarify what exactly he has done and what he thinks it means. His result will be much stronger if he can tie it, comparatively,to pre-existing work, especially consensus works cited by IPCC.
Koutsoyiannis, D., and A. Montanari, Statistical analysis of hydroclimatic time series: Uncertainty and insights, Water Resources Research, 43 (5), W05429.1–9, 2007
P.S. Under the LTP hypothesis the reason that “the data points in between the endpoints don’t matter” so much is because they carry redundant information.
I can’t stress enough the importance proving a physical mechanism that could acount for atmospheric LTP behavior. The modelers claim that “all the relevant physics are known”. If their modeled oceans are not behaving in a sufficiently Hurst-like manner, then this is false. This is a question that Gavin Schmidt dodges at every opportunity that he gets to lay it to rest. [Why?]
bender:
“I have no problems with the latter statement [that recent increases in GMT may be down to LTP], as it is what I have been arguing all along. (Whereas I have been merely spouting that line, Stockwell is trying to illustrate it in more concrete graphical terms. And for that he should be given credit.)
May I be the first to give bender credit for giving David Stockwell that credit.
Phew, thank goodness that’s over.
(Note to reader. The summary of bender’s statement in square brackets is deliberately informal. Please refer to his original before launching a further 100-post-criticism-flame at this yet-more-ignorant contributor.)
re: 100-post flame
The hockey stick was a half cooked product that is still giving us all indigestion. And look at the foodfight it provoked.
A spitball exchange is exactly what you should expect when you make bold statements that are tied
to a web page linking to a half-cooked result.
When Stockwell’s analysis is complete it may be worth a look. Until then …
——————————————————-
bender, #394: … “The question – keeping the K&M07 caveat in mind – is: what proof is there that there is such an LTP process in the atmosphere? If you were to go to RC and suggest it is the oceans, storing heat and then releasing it at a later time to the atmosphere, you would be ridiculed. There seems not to be a consensus on the nature and source of LTP in the atmospheric time-series data. And this is a major barrier to getting LTP-based models accepted as fact.”
———————————————————
I am now into my second year of asking the following two general questions here on CA, but without any kind of adequate response from people whom I have long hoped would offer some kind of definitive opinion:
(1) What kinds of direct physical observations need to be made; what kinds experiments need to be performed; and what kinds of data need to be collected directly from the physical climatic systems themselves to determine how they actually work?
(2) What is the delta between what we are doing now, and what would we should be doing in the future, to better characterize the actual physical climatic processes themselves, as these exist in nature?
These questions are asked from a perspective which views the GCMs as being mere intellectual exercises which may, or may not, have any useful fidelity to the actual processes happening in the operative climatic systems, as these exist in nature.
May I ask Dr. Koutsoyiannis to comment upon these two questions, if he would be so kind to do so.
#398
You don’t get anwsers because these are large questions that would take some time and space to answer and they are not related to the audit function, which is the purpose of Steve M’s blog. In terms of research I think we need to do what we are already doing. We all know that moist convection is a critical knowledge gap in the GCMs. Even the nost ardent alarmist modelers freely admit that. I would suggest emphasizing research on those elements. What answer do you get when you ask at Pielke’s site? I know he advocates more research on ocean heat content (OHC). I can’t disagree. But what do I know. Who is so presumptuous as to think they can provide a definitive review of the state of knowledge of the whole of climate science? You’re asking a bit much.
IMO it’s not what we need to DO, so much as what we need to STOP doing: promoting half-cooked ideas to the level of policy, ignoring uncertainty, failing to collaborate with real statisticians, failing to comply with disclosure rules, and so on. If we rectify those things, then the science will progress at the maximum possible rate.
Re 384 – David Stockwell’s analysis
Isn’t what is being shown by Stockwell’s analysis is that statistics has nothing to offer in the AGW debate. The null hypothesis cannot be eliminated and so AGW statistics remains just a manipulation of numbers. This would mean that the attribution studies based on the GCMs and their underlying physical models are now the only method we have for determining if AGW is taking place.
I believe Steve McIntyre has made this point several times. The point may be obvious to everyone but me but I thought I would make it again.
Continuing 400 and in referencing to Stockewell’s analysis in 384:
So if AGW statistics have nothing to offer and Koutsoyiannis et al (2008) shows that GCMs have no predictive value, what are we left with
bender, the attempted analogy (#392, #397) between the decadal hockey stick shenanigans and your own intemperate response to David Stockwell’s obscure and tentative blog posts here and on Niche Modeling in the last five days would I think be hilarious to everyone, if you alone did not take yourself so seriously.
Hockey stick (from memory, please anyone correct): the graph in question was put forward in a peer-reviewed paper in 1998 and quickly became the poster-child of the AGW community, including a prominent role in the IPCC TAR in 2001, thus helping influence the whole world towards irrational climate change alarmism. The heroes who took it down, through many vexatious months and years, were McIntyre and McKitrick, and later I guess Inhofe and Wegman.
Stockwell’s ‘no warming found July 79-08’ based on Rybski: put forward in what I thought was a light-hearted way on McIntyre’s own blog last Wednesday (#298) it attracted a ridiculously aggressive response from you a full ten minutes later (#299) which is worth mentioning only to highlight David’s delightfully measured and humble reply (#300).
But you don’t give up, do you? You don’t learn from Stockwell, from Frank, from Koutsoyiannis or indeed from McIntyre and McKitrick.
For the avoidance of doubt, I’m not talking about these men’s multi-valued abilities in climate science and statistics. I’m talking about the exemplary way they conduct debate.
I feel privileged to be on this blog, even in a small way, with them. I don’t feel the same way with you. And that’s not because you’re not smart, smarter even perhaps than me. (Irony: a British weakness. Sorry.)
Which reminds me. While I am getting low-down and personal let me add one other criticism, the most damning of all. In his defence of Stockwell and constructive suggestions to you in #390, Geoff Sherrington wrote:
“David is not a simpleton, far from it. He’s Australian.”
As alluded to above, humour has been one of the weaker spots of this otherwise fascinating page. But for you not to pick up and play a riff on this great example of the genre, and thus take much of the heat out of the flaming, is simply too bad.
Meanwhile, it would indeed be interesting to learn more about the Rybski/LTP implications, even as a rank amateur. #400 and #401 are a promising start, in language I can almost understand. So I guess I’ll be sticking around. Just to let you know.
From the well articulated paper KM 2007, I excerpted the following statements which may have bearing and reservations on what David Stockwell is attempting to show.
Click to access 2006WRRHydroclimaticStatisticsPP.pdf
Rybski et al. [2006] conclude that the hypothesis that at least part of the recent warming cannot be solely related to natural factors, can be accepted with a very low risk. Cohn and Lins [2005] state that, given what we know about the complexity, long-term persistence, and non-linearity of the climate system, this warming can be due to natural dynamics. This disagreement may indicate, in our opinion, that our understanding of the behavior of LTP and its consequences in climatic analyses and statistical testing is not complete yet and that additional insights are needed.
And here
Our focus is on providing insight on uncertainty rather than on proposing accurate statistical tests. In this respect, our study of the detection/attribution problem is carried out on a conceptual basis and therefore we avoid proposing categorical results. In addition, we try to locate potential pitfalls, which may appear if this uncertainty is not explicitly considered and may have also influenced previous studies. The uncertainty is studied under both STP and LTP hypotheses, also in comparison to the IID case, but the emphasis is given to the LTP case. It is not our target to prove or disprove the LTP hypothesis here; in contrast, we demonstrate below that (because of high uncertainty) such a target cannot be achieved by merely statistical arguments.
However, by summarizing the above discussion, we believe that several indications have been already accumulated (see the references cited above) that make the LTP hypothesis very plausible in contrast to the implausibility of common alternative hypotheses such as IID (usually implicit in most statistical analyses of hydroclimatic processes.
What Stockwell posted the first time around bears no resemblance to what is there now. That is precisely why I reacted as strongly as I did: to get him to clarify what he was doing. Whereas timeteem, you add what exactly to the process?
timeteem, #400 and #401 – dismissing the role of statistics – are “a promising start”? Is that a joke?
Stan Palmer is forgetting that it is not a foregone conclusion that the LTP model advocated by Rybski has anything to offer as a statistical model of climate. Until you have identified the source and nature of the alleged LTP, you have added nothing to the debate. That is precisely what Koutsoyiannis’s caveat means. It means you have to understand the cause and nature of “internal climate variability” that the iid folks treat as noise.
My apologies for being so humorless. I am excited by the fact that the climate community is actually talking about this issue. It’s important. Get this issue on the table and it will change the way the GCMers must do their work.
bender (#395)
“I can’t stress enough the importance proving a physical mechanism that could acount for atmospheric LTP behavior. The modelers claim that “all the relevant physics are known”. If their modeled oceans are not behaving in a sufficiently Hurst-like manner, then this is false. This is a question that Gavin Schmidt dodges at every opportunity that he gets to lay it to rest. [Why?]”
Why? One phrase: “warming in the pipeline”
I think the ‘L’ in LTP is different for different processes, one of which caused the great sea dragon to exhale most of the excess heat to space in the el Nino of 1998.
Syl #406,
What literature can you cite that makes this connection between “warming in the pipe” and LTP? Is this addressed anywhere that you can see in the IPCC AR4? If not, then which sections come closest?
This specific question has been dodged many times at RC, by the way.
well, I’ve stayed out of this food fight which is utterly uncommon for me. I happen to agree with bender and lucia, which should be no flash news release, but I’d gladly review david’s work again, since I’ve always enjoyed his writing
and contributions.
One thing bender said really struck home:
” IMO it’s not what we need to DO, so much as what we need to STOP doing: promoting half-cooked ideas to the level of policy, ignoring uncertainty, failing to collaborate with real statisticians, failing to comply with disclosure rules, and so on. If we rectify those things, then the science will progress at the maximum possible rate.”
If the discussion is turned to wacko theories or other nonsense, then all the air is sucked out of the room.
FOCUS ON THIS. Uncertainty. Yes its getting warmer. how good are the records? not very good. Methods. how good are the models and the statistics? LOUSY. Openess, can the data and methods be used by others? Barely
climate science gets a D.
well, that’s the view from the lukewarmer camp.
I wouldn’t have the sort of blog I do if I didn’t want feedback, so I am grateful to bender for that and bringing important issues into focus. I don’t think any method is ‘better’, but they are based on assumptions, and thats what you need to focus on. My thoughts on the DrK discussion:
1. Why LTP? DrK has written extensively on mechanisms of LTP. One of the most relevant views I see are where he suggested that LTP is a maximum entropy solution. As I understand it, AR(1) is a restriction to a specific, analyst determined time frame. When we assume all timeframes as equally valid, then we get a process like fractional differencing, and LTP behaviour. Another generating mechanism is alternating means. If the underlying temperature alternates at a range of magnitudes and time scales, (as few as 3 makes a reasonable approximation) you get LTP. DrK also has mechanisms of feedback that lead to LTP. Its all in his papers.Start here, or review past CA posts on Koutsoyiannis and my blog.
I tend to think the problem with GCMs not showing LTP is that they have finite elements. LTP behaviour could be simulated, but it would increase computation only to blow out the CIs. The end result is the GCMs would still have the warming bias in the average behaviour, but wander farther afield.
#409
Dr Stockwell, I’ve always enjoyed your comments at CA. May I put my over-reaction on context, and say that I did not realize you were working on something deeper than what you had initially presented. [I should have known …]
That said, your comment #409 doesn’t get to the heart of the problem: the physical mechanism(s) behind putative LTP. Abstract heuristic and statistical explanations and analogies will not make a dent in the consensus (although it may help to get your point across to a lay audience). A convincing explanation has to be grounded in the physical sciences. This is where Koutsoyiannis matters. He’s a hydrologist. If oceans behave, in part, as rivers, then his work is in play. If the heat that’s “in the pipeline” is a source of LTP, then the game is on. But if it comes from mystical places that can’t be physically identified, the theory will not play well. Witness mosher’s reaction.
Also … “blowing out the CIs” on the GCMs would not be a bad thing.
bender: I try to reach all levels on my blog, and there is a large demand for basic statistical stuff (and I mean basic) so sometimes I intentionally ‘dumb it down’. This sort of misunderstanding has happened before.
To your point in 410: this is my view. Consider special relativity. The concept is abstract and counter-intuitive, the consequences absurd on the face of it. The idea that the faulty assumption is a single arbitrary time-frame, and that all time frames in an AR(1) model are mare equally valid is abstract, but that’s physics. It may sound half-baked and out-there, but you know, there are still people who don’t accept special relativity too because it doesn’t seem physically realistic. (Please don’t take this OT).
By “blowing out the CIs” I mean that the same result could be achieved with a single uncertainty parameter, without going to all the trouble of simulating it.
#412
1. Thank you for the explanation. That makes sense. Myself, I am very wary of material that appears propagandist. Hence the over-reaction.
2. I didn’t say I disagreed with the idea. But it *would* get laughed off at RC. Strike that – *has been* laughed off.
3. I know what you mean by “blowing out the CIs”. That’s what I suggest lucia do, with the 1/f noise approach. Yes, it’s heuristic, black box, mysterious. But it gets the job done.
Stockwell, bender, Stockwell, bender (this could get addictive):
Sorry for the really ‘basic’ question … but what, pray, are the CIs of a General Circulation Model?
(And glory be, blockquotes seem to work.)
#413 This will be my last comment for a while.
1. Fair enough.
2. Says more about RC than the idea. AFAIK DrK is more sanguine about the arbitrary AR(1) maximum entropy explanation, and prefers a feedback dynamic (mean reverting with overshoot I think). If he tunes in no doubt he would elaborate. What we need are clever experiments.
#414 CI-Confidence intervals, spread of results, probability distribution function (PDF).
By way of more explanation, I don’t really have the time or inclination for long forum-like discussion, and I have never seen one settle an argument on the web. I have seen data settle things though, so I prefer to spend more working with the numbers.
bender
Chapter 10 in AR4 mentions commitment and thermal inertia of the ocean without explaining the mechanism. I apologize but I’m having severe problems trying to type in this box….
#415 David thanks. It was obviously something I should have been able to guess and now I know why. Before you go, thanks also for your desire to communicate to statistical neophytes on Niche Modeling, that then got you into so much trouble here. I feel I know enough about the net (if not LTP time series) to agree that such questions are unlikely to be settled on highly charged, massively multi-person blogs. But perhaps, gradually, the wider culture does change and inspired experimentalists come to the fore. Good luck in making that happen.
#415:
Couldn’t agree more. Scientific arguments are settled by data, not hugs and smileys.
As for blowing out GCM CI’s, recall that “9 out of 55 runs of model E exhibit 8-year cooling trends”. That’s right folks, no typo here. The party line is that short-term cooling is not inconsistent with long-term warming. Blowing up the CIs would mean what, that long-term cooling is not inconsistent with long-term warming? Can’t wait til we’re there.
IPCC 4AR p. 825
So, ocean thermal inertia should scare us for the warming that gets held “in the pipe”, but it should not be a source of LTP-related skepticism on the estimated magnitude of the GHG sensitivity parameter?
That’s definitely one for the AAGW double-standards database.
Aha ….. This thread is a great opportunity to see if Block Quote and Bold are working as well as they did before the WordPress upgrade:
and:
Having been both a full-time engineer and a full-time auditor, neither the engineer in me nor the auditor in me is satisfied with the responses so far to my two questions. To wit:
No doubt these are very large questions. I knew this when I wrote the two questions in such simple and direct terms. But I did so with a purpose in mind.
If one is determined to eat the elephant, one has to start somewhere. I suggest the top left ear — the trunk, the tail, and the feet being unacceptable starting points for various hygenic reasons.
As for not being connected to the audit function, little of the discussion in this topic thread is directly connected with the strictest definitions of what Quality Assurance auditing is all about, including the topical matter of the thread itself.
What this discussion is all about fits into a broader definition of auditing, one which is often called “Internal Audit” in a large corporate organization.
The Internal Audit function has significantly broader powers than does the QA Audit function, in that any facet of the organization and its operations can be examined for deficiencies and for potential improvements, including deficiencies in the corporation’s written processes and written procedures which the QA Auditors have no authority themselves to go beyond in performing their audits, or to criticize directly.
In government, the most prominent example of an Internal Audit function is the Government Accountability Office, aka “the GAO.”
As long as the staff of the GAO works within its written charter, and as long as the staff continues to do their work with a high degree of professionalism, they are free to set their own boundaries relative to the issues they are examining.
I interpret the charter of Climate Audit, as Steve McIntyre has described CA’s role and purpose, as fitting the “Internal Audit” model for an auditing organization, i.e. its auditing powers go well beyond the more strictly defined limits of the QA Auditing model.
What it all comes down to is this: I get to ask my two questions, and I am allowed some reasonable expectation that I could receive at least the nucleus of some set of appropriate answers – within the boundaries of what an Internet discussion forum could reasonably provide.
However, in a larger context, relative to the billions being spent on climate science, I want more. (Much, much more.)
You, bender, have made a start at providing these answers, as follows. Your initial response might form just one square foot of the left ear of this particular elephant, but it’s a start:
I have not asked Dr. Pielke these two questions. But I presume he is reading this thread and will offer some comment about them.
The IPCC bills itself as having a thorough and comprehensive understanding of the current state of climate science.
However, the IPCC’s assertions not withstanding, this claim is not currently backed up by an auditable and tightly organized foundation of reference information and knowledge — viewed either from a narrow QA Audit perspective, or from a broader Internal Audit perspective. Hence the need for a climate science auditing function — formal or informal.
There is much more to it than that. A more professional approach to pursuing the details isn’t nearly enough to get us by. We have to ask ourselves what kinds of details and what kinds of data are missing from the evaluations — not just ask if we are doing the right work with the data and information which happens to be readily available to us. Here is an example of why I say this:
And yet another example:
As I am typing this note on my laptop, while sitting on the veranda of my small cottage, it is a hot humid afternoon, and I am observing a thunderstorm developing in the distance off to the west. A lot of energy is moving around up there in the sky. Where did all that energy come from? Where is it going? Wherever it is going, why is going there, and not somewhere else?
Through the magic of the Internet, I can also see lots of neat climate science discussions with lots of neat equations and lots of neat statistical analysis. But as an engineer, I ask myself, what real connection does all this mathematical abstraction have with the natural activity I see going on up there in the sky to the west of my cottage?
I do not see what value Steve McIntyre’s engineering quality exposition of 2xCO2 Yields 3C Warming would have — nor do I see how it could even be produced — without there being in existence some kind of auditable, tightly-structured inventory of climate science issues, one which includes a subsidiary inventory of the types and quantities of empirical information which would be necessary to prove or disprove the conclusions of said engineering analysis.
That detailed inventory then forms an objective basis for answering the further questions of: (1) what data have we got now; (2) how reliable, and of what true value, is that data; (3) what more do we need, and why; and (4)what specific implications does a lack of necessary data have concerning the overall validity of the engineering analysis itself.
Assuming no autocorrelation for RSS (based on the DW test with GISS data), I regressed the annual temperature anomalies for the period 1979-2007 and determined the prediction intervals for individual years shown in the graph below.
The regression also gave the following:
Trend = 1.83 degrees C per century; R^2 adjusted = 0.54; p = 3.4E-06 and Trend Confidence Interval = 1.18 to 2.47 degrees C per century.
I present these data for comparison with David Stockwell’s methods. The RSS trend fits a linear regression rather well with a significantly positive trend. The prediction intervals for individual years show that a beginning point and ending point predicted from the regression could fall close together.
Re: Post #421
My graph showed in the preview but not in the final post. I will attempted to link to the graph in this post.
Scott-in-WA
This thread IS about audit. Review McKitrick’s post #24. If Koutsoyiannis’s paper and his ideas have some credence, then it is significant that this chapter section was removed from IPCC 4AR. Meaning someone should be accountable for that decision.
Sometimes you have to prove there’s a scientific issue at stake before you are justified in suggesting there’s a procedural problem. Granted, procedural errors by themselves are a problem. But those kinds of errors are everywhere in this IPCC process. In order to provoke corrections or process reform, one is best off to focus on just those procedural errors that are consequential.
That is what Steve M did to break the hockey stick. He found a mathemtical error that turned out to be a systemic problem in the way that the science is conducted and the review process is implemented.
Kenneth, I couldn’t follow your statement. You say:
What does the DW test on the GISS data have to do with RSS? Also, why do you assume no correlation for the RSS data? I see a lag(1) autocorrelation of the RSS data of ~ 0.86, and a Hurst exponent (R/S) of 0.89 …
w.
bender (#418):
Reference?
bender (#423):
The thing is, I don’t see anywhere that Scott says it isn’t about audit. He is merely saying from his background in the nuclear industry that ‘internal audit’ for the whole AGW scene, feeding as it does into extremely important policy making, should be immensely stronger than it is. Surely none of us can disagree with that.
What Steve McIntyre means by Climate Audit though is up to him. I read with habitual admiration what he said in the first post on this thread:
So I was very disappointed at your cheap shot at RealClimate just four posts later:
Strictly speaking, you hadn’t indulged in generalized complaining about climate models. But what you had said seemed not only completely unnecessary but against the spirit of what Steve had just asked. I hadn’t been on CA all that much until this moment and I didn’t remember the bender moniker at all. But, from this moment on, given the beautifully irenic approach of Dr Koutsoyiannis, whose paper we were meant to be discussing, I was appalled to see the subsequent conversation so dominated by you. “Poisoning the well” indeed. With friends like this, we didn’t even need enemies.
Still, you just apologised to me for being humorless (#405). I didn’t expect that. Thanks. I may respond at greater length to that post and the previous one, before the UK’s bank holiday Monday is out.
Re Bender # 418 re my # 390
It was not my intention to inflame debate about David Stockwell. I had had a cordial conversation with him on some matters that overlapped, at about the time he posted the seminal piece. So I had the advantage of some inside knowledge when cautioning care. (Like David, I dislike social arguments).
Re # 402 timeteem
Not all together humour. In time people like bender will get used to matters like the Beijing Olympics Gold medal count – USA 0.12 golds per capita, Great Britain 0.31, Australia 0.70, all +/-0.1.
Closer to home, here are raw values for melbourne annual max temp by year, with y-to-y change, Celcius
1999 20.93
2000
Data dropout – continuing table
1999 20.93
2000 20.99 +0.06
2001 20.55 -0.44
2002 20.91 +0.36
2003 20.73 -0.18
2004 20.36 -0.37
2005 21.39 +1.03
2006 20.84 -0.55
(My figures end here)
There is a tiny difference between 1999 and 2006. Three positive increments, 4 negative. I fail to see that one year can predict the next, e.g. 2005 was a bit warmer, but why?
Since start = finish, am I justified in claiming no change, or do I have to be more sophisticated statistically?
This is a quite homogeneous dataset, with daily readings at same time of day, UHI maxed out, no missing data, same instrument so far as I know, etc.
So where is the relished, relentless, re-released, radiative red rise that that little devil CO2 caused?
re 410. BINGO. without some physical theory a mere appeal to LTP is just an appeal to ignorance, bender I like the rivers in oceans, BTW. very clever way to put it.
re 428. A while back StMac did a compliation of all stations in the US. Its in one of his data files. He calculated century trends at each station. Its interesting to note that a sizable ( not a majority, obviously )
of stations have cooled over a period that is longer than the magic 30 year number. why is that? why is that GCMs
can hindcast the warming trends but seem to miss the cooling trends?
3Am must sleep.
Some recent comments and questions give me the opportunity to clarify some of my views with respect to LTP.
1. I do not think that LTP is just (or mainly) a hydrological behaviour, related for instance to the rivers and the water storage in soil or aquifers. Definitely not. Attributing LTP to merely storage will not help understand its nature. Storage implies STP, not LTP. In my view, LTP in hydrological processes is a result of LTP in climatic processes. The huge variations of the Nile flow on large time scales (which we know from the longest available instrumental record covering many centuries) reflect (and result from) variations of the climate over its huge basin.
2. The close relationship of LTP with hydrology is historical, rather than science-based – and not exclusive. Engineering hydrologists design structures to cope with future uncertainty (e.g. reservoirs) of water availability and water related risks. To this aim they study all available historical information in a statistical manner, rather than attempt to build deterministic models predicting the far future. They trust data more than models. They are satisfied with the quantification of uncertainty, which makes a reliable basis for engineering designs. The British hydrologist Harold Edwin Hurst discovered LTP while studying the design of the High Aswan dam in the Nile. His celebrated paper (1950/51) is not just hydrological. It refers to numerous geophysical processes, in all of which he verified the same behaviour. Amazingly, Kolmogorov studied the stochastic process that describes this behaviour, discovered by Hurst in geophysics, 10 years earlier (1940). Kolmogorov was then studying turbulence, which also exhibits similar behaviour. In our EGU 2008 presentation with initial title “The Hurst phenomenon and climate” (http://www.itia.ntua.gr/en/docinfo/849), Tim Cohn and I used the term “Hurst-Kolmogorov (HK) pragmaticity” instead of the more common “Hurst phenomenon” to give credit also to Kolmogorov and to signify the fact that the behaviour is more general than hydrological and that it is a very common, rather than phenomenal, behaviour in all processes. This presentation contains a brief history of the study of the HK pragmaticity, from where it can be seen that the widest use of HK ideas is made in electronic networks and not in hydrology. The papers by Leland et al. (1994, 1995) on Ethernet traffic are the most cited ones (> 3500 citations; cf. Hurst 1100, Mandelbrot & van Ness 1900).
3. Those who seek a physical explanation for the presence of the HK behaviour in climatology per se may be disappointed by the fact that HK concerns also other geophysical processes, physical processes and human-related (technological and economical) processes. The HK behaviour seems to be omnipresent. Therefore, we may seek a more general explanation. A path that I have explored in this respect is the principle of maximum entropy (e.g. Koutsoyiannis, D., Uncertainty, entropy, scaling and hydrological stochastics, 2, Time dependence of hydrological processes and time scaling, Hydrological Sciences Journal, 50 (3), 405–426, 2005).
4. Physical explanations are not necessarily mechanistic explanations (as we have learned from quantum physics and statistical physics). Entropy is a physical concept as fundamental as to provide the basis for formulating the second law, yet its definition is probabilistic/stochastic. Entropy is a measure of uncertainty and maximum entropy is maximum uncertainty. The stochastic grounds of this definition should be contrasted to mechanistic analogues of the 19th century and earlier (e.g. the caloric fluid). The linkage of LTP with the principle of maximum entropy, along with the omnipresence of LTP demonstrates nothing other than the dominance of uncertainty in nature and life.
5. Many regard entropy, uncertainty and unpredictability as concepts with a “negative” meaning. I regard them as very “positive” concepts, the causes of creativity and evolution, and the reason why life is fascinating. I would not watch a football game if its evolution and outcome were deterministically predictable or controlled. Life would be a nightmare if it were deterministically predictable and controlled. I would be very unhappy to live in a technocratic (i.e. fascistic?) system where a few super-experts with their super-models could predict what will happen in 100 years and control the environment and life. Fortunately, this will never happen because nature and life obey the principle of maximum entropy.
RE: 431 Demetris,
Thank you. I hope you never lose your sense of poetry in trying to understand nature – it speaks of truth.
bender, mosh: something to learn.
David Stockwell, Pat Frank, Jonathan Schafer, Barney Frank: I think you understand.
Cliff
timeteen – bender comes and goes. You’ll miss him if he takes another holiday. He’s relentless on any weakness, real or apparent. That’s why we love him so.
Demetris (#431) makes sense of some things I have been trying to organize and articulate since the bender-Stockwell-kerfuffle (bSk) erupted. To get to the point, as much as I hesitate to engage, IMHO the bSk is a false conflict.
What bSk reveals (again, IMHO) is a lack of rigor in the foundations of climate (and other) science (not in the participants). As you have noted previously, we tend to assume existence of a consistent definition of trend without checking to see if such a definition exists.
This is reminiscent of Ross’s inquiry into the concept of global temperature.
Everything gets complicated when you bring in LTP. Working out the physics — which is almost always a useful way to proceed — is not a trivial assignment. As you point out, it requires digging down to the very foundations, because LTP seems to be coded into the center — the shared portion — of Mother Nature’s DNA.
It is only an historical accident that LTP was first recognized in hydrology. In fact, LTP is ubiquitous in essentially all sufficiently large and complex systems (no, I cannot provide rigorous non-tautological definitions).
On the other hand, perhaps I have completely misunderstood everything. 😉
RE: #427 Geoff,
Of course, you did not explain why a bright Australian (Stockwell) is living in the US, while the Australian jocks that won metals are still living in Australia. 😀
Cliff
#425 timeteem, I’ve referenced the 9/55 number on several occasions at CA. It came from Gavin Schmidt at RC. It should not be very easy to find. (Being reprimanded for not sticking to blog rules is laughably ironic. You are going to be one busy person as soon as I go on my next hiatus.)
#432 nothing to learn. I simply tried to emphasize what I know the self-described “physicists” at RC would demand for an explanation of LTP. Maximum entropy, fine. But good luck moving that one forward. I can just imagine. “Entropy caused the 1990s uptick.” “Entropy caused the 2000s flatline.” You see the problem. (Readers will also note that nowhere in Stockwell’s discussion is the word “entropy”.)
DrK, I think Steve M would be happy to have you speak any time you feel the need.
mosher and me are just court jesters. We know that. Just happy to have a gig.
remove the “not” in 2nd sentence. Should be very easy to find.
RE: #436 bender.
(Re: #432) No problem, it is your loss. A bender has got to do, what a bender has got to do. Rationalize on, as usual – nature won’t care.
BTW, I don’t think Steve M or mosher need you to speak for them.
Cliff
RE: #436 bender.
(Re: #432) No problem, it is your loss. A bender has got to do, what a bender has got to do. Rationalize on, as usual – nature won’t care.
BTW, I don’t think Steve M or mosher need you to speak for them.
Cliff
I find it interesting that the Team (and maybe some here) considers a 10-year divergence in the solar relationships as PROOF that those relationships are garbage. But then a 10-year divergence in the OCO/Temp correlation is just “natural variability.”
bender: 9/55 is 16 percent. If you look backwards in time, it seems that multi-year periods of constant or decreasing temperature are a lot more common than that.
bender (#436):
obviously
Re: #424
Willis E, I am using the lag 1 correlation of the residuals from the regression of annual anomalies for RSS and I obtain an R^2 = 0.001. That is what I would base my computation of the DW statistic on and I would strongly suspect that it will show no significant autocorrelations. I’ll do that calculation and post it here later.
When using a lag 1 correlation on the RSS annual anomalies (and not regression residuals) I obtain an R^2 = 0.31.
I have not done the monthly lag correlations for RSS, but when I did it for the GISS data 1979-2007, the DW statistic on the regression residuals showed a very significant positive autocorrelation.
These results are why I question the use of monthly data with its autocorrelations (that have to be corrected with methods such as Cochrane-Orcutt) when the annual data does not require corrections (that could be of uncertain validity – see Steve M remarks on C-O CIs versus those CIs derived using maximum liklihood approach).
Cliff – “sense of poetry”: Very flattering, thank you.
TAC – “Mother Nature’s DNA”: Well said — and I agree with all what you say, so “perhaps I [too] have completely misunderstood everything”.
bender – “the self-described ‘physicists’ at RC would demand for an explanation of LTP”. Is what they demand my [our] problem? Shall I let the self-described physicists describe/determine my [our] reactions? But I enjoy your comments, even though sometimes I am surprised by your style — either positively or negatively; certainly it harmonizes with max entropy 😉
Re: #442
My calculation of the DW statistic for the residuals of the RSS annual anomalies was 1.92. This DW statistic ranges in value from 0 to 4 with 2 indicating no autocorrelation. The tables I used showed that we can conclude no evidence of autocorrelation of the residuals at a very high probability.
After reading KM07 and Dr Ks comments at David Stockwell’s blog, I think the main difference that I see between their presentations is the number of caveats that Dr K presents versus what David S has offered to date.
My only purpose in presenting the RSS 1979-2007 temperature anomaly series here, and as something of an aside to the discussion, was to give a basis for comparison to what David S was proposing with Rybski’s methods for LTP. I will await David S’s further efforts to use that approach. I personally feel that I have learned from this discussion and credit David S with his attempts to push the LTP statistics onto something topical and in the process learn from his efforts. I hope that we can have future discussions here on this topic as well as discussions of Lucia’s shorter period trend analysis.
Being in rather decent touch with my own limitations, I must admit that I am uncertain off the top of my head what to do with the RSS data series that shows a lag 1 correlation with the raw data but not with the residuals. The residual correlation would violate the assumption that error terms are independent. I have seen corrections using a reduction in the number of degrees of freedom in calculating confidence intervals due to autocorrelations of data, but I do not have a finger on how or when to make the correction.
If anyone can help me it would be most appreciated even if you have to be a little hard on me. My feelings seldom are hurt anymore and particularly when I can learn something in the process.
bender’s style is uneven because he has two roles to play:
-provoking discussion on areas where he is ignorant, but there are knoledgeable experts lurking
-discussion on areas where he is not ignorant
Think of him as schizophrenic.
DrK’s work deserves wider attention. bender is trying to promote that discussion. Spitballs are not a problem. What matters is that discussion is happening. That people are learning something they will never get at RC.
What matters is in post #24.
#431 Dr. K,
A wonderful and useful post. #5. especially. I’m tucking it away in my “quotes to be used later” file.
bender:
Dr K:
As outlined in post #24, it is a problem for everyone when the consensus keepers do their dirty work by editorially subtracting out science wherever it is convenient.
Hypothesis: LTP may be THE inconvenient truth.
I challenge those far smarter and more even-toned than bender – the Hustons and the timeteems – to get the consensus keepers at RC to talk about the issue.
Contrary to what the contrarians think, they wield enormous influence.
David Stockwell,
Maybe it’s not that the physical mechanism(s) that cause LTP or 1/f or whatever in the atmosphere are not in the models but that they have been so regularized that LTP disappears. Convection looks to me a lot like the sand pile problem. You build up an unstable temperature gradient near the surface that eventually causes convective mixing to restore stability, just like there are avalanches in the sand pile as more sand is added to the top. In the real world that might range from lots of little updrafts that don’t get very high to a few big ones that reach the stratosphere. But if you always resolve the stability problem the same way at the same level of instability, then no more LTP. Yes?
Re: 448
Bender, there are no doubt many sharp minds that participate at RC and they do provide a view of where the consensus climate science comes down on important issues and explanations for it. What they choose to discuss and how they approach it does, however, appear to have a goodly dependence on their well-known stand on climate policy. They are very good at defending the status quo of climate science, but that does not come without negatives.
If there is an urgency in getting all the facts on the table with regards to climate science before deciding/embarking on major policies, in my view, it will have little to do with what is discussed at RC or CA and much more with what our politicians judge is in their best interest vis a vis a marketable approach to their constituents. The science on which those political decisions will be based will be, if history be the judge, unrecognizable.
Let RC do their defender thing and hope that CA can tend toward the puzzle solving inclinations of Steve M and keep the hard analyses of papers and methods in the forefront. I think climate science will have to cleanse itself of any internal problems and became more aware of the special dangers lurking for their area of science from not maintaining a clear boundary between science and policy. I would hope that most of the participants here are more interested in getting the climate science right in their own minds and less in saving the world – as I think that latter activity would require a blog of a different nature.
The above was a long way (around) saying that I hope we can have a more detailed future discussions of LTP and climate here at CA.
After re-reading #24, what isn’t in the models is(are) the process(es) that keep the real climate from wandering off into absurd states. Tweaking out drift is a kludge.
Kenneth, thanks for answering my questions. Inter alia, you say:
Like you, I have similar questions. Mine concern the HadCRUT3 dataset and the GISS ER models. Here are the raw data (including monthly variations) in the first row, the first difference (∆T, second row) and the second difference (∆∆T, third row) for the models, their average, and the data. Here are some violinplots of the results.
Fig. 1 Violinplots of monthly surface temperature results for 9 GISS ER historical model runs (1880-2003), their average (orange), and the HadCRUT3 global surface temperature dataset (red). First row, data (T): second row, ∆T: third row, ∆∆T
Now there’s some things of note. First, the data shows the cyclical nature of the monthly changes in its “barbell” shape, wider at the top and bottom.
The next is the nature of the distribution of the values for the first difference (monthly change in temperature, second row). The models all show a Pareto type distribution, a truncated Pareto distribution. The observations, on the other hand, are very different. They show an almost uniform distribution (which can also be modeled as a truncated Pareto distribution, but a very different type).
Then look at the second differences (acceleration of monthly change in temperature, third row). The models all again show a truncated Pareto type distribution, but once again, the observations show a very different pattern. Oddly, the pattern itself is very similar to the models … except it is inverted. Go figure.
The curiosity is that all of this statistical weirdness disappears when we remove the average monthly anomalies. At that point, the data and the first and second differences all are basically gaussian normal …
So it seems to me that we may be going down the wrong road to concern ourselves with anomalies. The GISS ER models all give results which are near to observations for the anomalies (all of them are gaussian normal and match fairly closely to observations), but which are far from the observations for the actual data.
My understanding of the nature of climate is that it is running most of the time in a state of self-organized criticality. This leads to either uniform distributions or Pareto distributions of very specific kinds. It seems to me that it would be more valuable to study that data, which is how nature actually works, rather than the uniform gaussian distributions arising from the removal of the monthly averages.
I also think that this kind of analysis should be done on all of the models, and those that cannot reproduce the distribution of the observations should be sent back to the drawing board.
A final question … I can model the observational results shown above, but only by brute force. I model the ∆∆T, use that to back calculate the ∆T, and then use that to back calculate the “sine wave plus variations” shown in the original data.
So my question is: what the f*ck kind of distribution is sinusoidal plus variations, but has a uniform random (or perhaps truncated Pareto) distribution for the first difference, and an inverted truncated Pareto distribution for the second difference???
Any assistance gladly accepted …
My best to all,
w.
Grrr … the Img tag is not working? I try again, using different syntax …
In case that doesn’t get through, use
w.
Ross M, you say above:
The problem is that nature doesn’t drift because it is running at a state of self-organized criticality. In other words, it is running as fast as it can and staying in one place, because is is up against an upper limit at all times. It’s like a boiling pan of water … the temperature of a boiling pan of water doesn’t “drift”.
I doubt if earlier GCMs would handle this any better because, as far as I know, the models do not run at a state of self-organized criticality. Which IMHO is the main problem with the models. This results, as shown in my posting above, in distributions that are not at all “lifelike”, and in results that have to be forced into a semblance of “lifelikeness” through a variety of kludges.
w.
#450
Ken, I think you may be underestimating the power of the blogosphere. There is a need to get the facts on the table for all to see. GCMs are the strongest leg under the AGW table. If they have been tinkered with to have LTP removed, either by (1) forcing the entropy to behave incorrectly or (2) selecting out the runs that don’t conform to a preconceived notion about what kind of output is “realistic” – then this needs to be known, and the precise effects quantified. There is no time to lose. You have seen what kind of work people are capable of doing when they focus. This paper we are discussing is an example. I strongly disagree with your suggestion to let RC do its defender thing. If we are questioning the way that NASA does ensemble statistics, then RC is the most direct line of communication. If they don’t want to talk about it publically, then let that reluctance stand on the record.
One of the reasons my tone has been unbalanced, my posts so frequent, it is because time is of the essence. The community (both “sides”) needs to talk about this NOW.
#449
Inspired by #24, DWP #449/#451 asks a pointed question: are the GCMers using a kludge to tune out LTP? Tuning is one way they could do it. Parameterization another. Selective reporting of individual runs in ensemble-generation another. Is there any evidence of such tinkering in IPCC AR4?
I suspect that there are other ways that uncertainty is removed from the GCMs, in line with the points regarding turbulence that Gerry Browning has made on many occasions. Where are the cold fronts and warm fronts which cause so much weather uncertainty? Integrated out?
Having admitted many times that I’m too rusty to contribute to the nuts and bolts of stats, might I please be permitted to restate a number of general points I have been trying to make for many months now.
1. Where possible, work in absolute units. This business of reference periods of chosen years and centering and deltas and so on has caused a lot of extra work.
2. Work with raw data where possible. There are dangers that I do not have to detail, in using sophisticated statistics on data sets that have had prior statistical massaging. This error is far too prevalent.
3. Beware of trend analysis when the trend seems apparent but the cause is unknown. There might be more than one simultaneous trend, for example.
4. Do not assume normal distribution statistics when calculations can derive the actual distribution and assist in choice of subsequent analysis.
5. Remember that one sigma, two sigma, etc, are a mere convenience to visualisation and that Nature knows not about them. One sigma in one context need not be of the same importance as in another.
6. Avoid weighted running means where possible because of end problems and missing data.
7. Start with the highest resolution data and compact it with reluctance, because you lose data. Like taking a low resolution JPG photo rather than using RAW format. Sometimes you can’t go back through the data.
8. Use replicate measurements where possible (3 thermometers better than one) and in any change of method, maximise the overlap period.
9. Observe Nature. Not all problems are soluble with supercomputers.
10. Where possible, have an independent calculation of the important parts of your work. Hunt down any variance.
11. Be careful in discarding outliers. Sometimes they contain the very clue that is hindering your progress.
12. Correlation is not causation, always.
13. Do not assume that one data point can act as a predictor for another, without extensive testing under a range of perturbations.
14. Use uniformitarianism as your best assumption, but remember that it cannot be proven quantitatively to the distant past in many cases. (Try proving that the gravitational constant is constant, through observation, or that the diameter of the earth was essentially constant over a billion years).
I know that these are low-level statements; but I am surprised at how often they are violated.
One of the reasons that Dr Koutsoyiannis and his colleagues are so widely respected is, I suspect, that they are among the less frequent violators. Their publications are a pleasure to read.
bender, thanks for your comment. You say:
I have not seen any evidence of any effort to “tune out” LTP. At least one of the GCMs produces reasonable LTP. The Hurst exponent for the nine 20th century runs of the GISS ER is about 75 before removing the monthly averages, and about 95 after removal … which is about the same as the observations (HadCRUT3).
The problem, as I hope I showed in the graph at
[CAPTION:Fig. 1 Violinplots of monthly surface temperature results for 9 GISS ER historical model runs (1880-2003), their average (orange), and the HadCRUT3 global surface temperature dataset (red). First row, data (T): second row, ∆T: third row, ∆∆T]
(sorry, Img tag not working), is not that GISS GCM does not have LTP. It does. The problem is that it doesn’t have the same kind of distribution that the observations have.
Actually, I would say that’s not the problem, that’s the symptom. The problem is that the natural processes are not being modeled with enough fidelity to get lifelike results.
Best to all,
w.
On a long thread like this, it’s probably just as well that the Img tag isn’t working.
#439 and #441 misrepresent my take on DrK’s entropy-driven LTP. I have a solid superficial understanding of the idea. For four years I have been espousing DrK’s papers, two years publically at CA. Fourteen years for closely related papers in my field. I know what the subject is about, thanks much. Unfortunately, an intuitive, i.e. non-mathematical understanding is not enough to confront the emperor. Ill-posed questions do nothing but make the asker look silly. What are required are direct, pointed, well-posed questions that the emperor must choose to answer or evade. An honest answer would make me very happy. But a clear evasion would still be progress, if it were a matter of public record.
Re # 435 Cliff
Answer – Many of the Australian Olympic medallists have tried USA food.
BTW, I often include a harmless little error in my posts to see how closely they are read. The figures for medals in my #427 were for golds per million capita.
A question for Dr. Koutsoyiannis:
Which is more likely to be a cause of a short-term GMT trend either upward (e.g. 1991-98) or flat (e.g. 2001-2008):
(a) “entropic” LTP
(b) ocean heat storage (“STP”) lag effects
Feel free to rephrase if ill-posed.
In #127 I promised I would answer Boris’s #126 question –
– “after the thread at RC had developed somewhat”.
Well, the experts at RC gave it everything they had, I guess, and concluded that Koutsoyiannis was trivially correct, despite a weak methodology (due to low replication).
The one question they did not address was the only question that matters, which, ironically, is Boris’s question! Boris’s question is a good one because it relates directly to DrK’s last point in the abstract:
IMO DrK did not prove that local-weather-scaling-to-global-climate failed to provide the “healing effect” (as referred to by Tom Vonk). But the proponensts of these models over at RC have equally failed to justify their assertion that the healing effect exists and that it emerges at a particular tiem and space scale. All they can do are spout platutides and appeals to authority: “climate is a 30-year average of weather because that’s what it traditionally is”. Hardly a reassuring reply. Does the chaos of weather tame down so nicely at climatic scales that deterministic responses to external forcings are unequivocal? (RC recognized the rope for what it was, and ran away.)
So, Boris, I think it is settled: the issue of how weather scales to climate is an unsolved question. Therefore it is not reasonable to assert as the modelers do. DrK is right to call this assumption into question.
Happy?
As David Stockwell said in his #415 that that would be his last post for a while, I’ll reply on his behalf to Cliff Huston’s comment (#435) that Geoff Sherrington hadn’t explained in his #427 ‘why a bright Australian (Stockwell) is living in the US.’ No explanation is needed: David Stockwell is living in Australia, and is still hoping that CA experts will comment on his analysis of the CSIRO/Bureau of Meteorology Drought Report, as urged by Steve McI three weeks ago ( http://www.climateaudit.org/?p=3392 ).
As far as I know, the answer to the question of how “weather scales to climate” is “fractally”. Steve M has pointed out somewhere that this was studied by Mandelbrot. My impression via Steve was that Mandelbrot found no “break” in the fractal dimension of climate phenomena with increasing time, at thirty years or anywhere else. As I said above, at thirty years, “climate” to a human is “weather” to a redwood tree.
It also would make no sense. It has been shown in a host of papers that an exceedingly wide range of climate phenomena are “scale free”. Cloud sizes and rainfall amounts and drought durations and tropical CAPE convection, the majority of climate phenomenon is scale free in time or space or both. It’s self-organized criticality, it’s self-similarity. If we divide up a single day and count clouds, or we count them for a week, or month, or a quarter, or a year, we get power law distributions. Why should that suddenly stop at thirty years, at which point we magically get Gaussian distributions? Climate is just weather writ large. And short term (30 year) averages of underlying power law distributions will follow a power law distribution, not a Gaussian distribution.
Gotta love Climate Science … a scientific field with no agreed-upon subject of study.
“What is the climate, Daddy?”
“Son, if I knew that, I wouldn’t be a Climate Scientist”
For me the climate is a honking great heat engine. Following the nature of self-organized systems, it does not throw its energy back out to space the way it came in. It picks up heat at the equator and transports it to the poles by moving the water and air. It moves unimaginable amounts of energy every moment, driving the great currents of air and ocean that are the working fluids of the heat engine.
And it runs at all times at “the edge of chaos”, as someone put it, in a state of self organized criticality. As such, over much of their range, events of all types are scale-free. The climate does not rain, or cloud up, or snow, or release energy to space in any even manner. It releases it in great gouts and bursts, in chunks and pieces that have no characteristic size, followed by periods of quiet of indeterminate size.
I have very little idea how to mathematically analyze the consequences of this.
w
re 462. in 1984 I found myself in a bar in Malibu california with the some of Aussie water polo team. fosters was available
so they didnt have to suffer american beer. or pay the tab. my wallet is still in rehab. Fine bunch of lads.
Willis (#459);
When you write that
Are you talking about the case of the forced scenarios (SR A1B?)? If so, it should come as no surprise that with forcings the GCMs exhibit (20th century) Hurst coefficients in the range of what’s observed in nature. Because the forced GCMs are tuned to mimic 20th century temperatures (in both time and frequency domains), they also mimic the corresponding LTP (in other words, the LTP-like behavior is an artifact of the forcings).
The interesting place to look, and the place where the discrepancies occur, is in the unforced model runs, where (IIUC) the GCMs fail to reproduce LTP.
Please correct me if I have misunderstood this. 😎
bender, 463:
With the risk of being pedantic, here is my reply:
1. We roll a die on a table and assume very low friction, so that it takes long to stop. We are interested in the succession of the upmost faces in time. We can describe the movement of the die by Newton’s laws, and use this description to predict the state (the upmost face) if the time horizon of the prediction is short (say smaller that the time taken by a couple of collisions with the table). We easily understand that on longer times the deterministic dynamics cannot help to know the system state. (After all, the die is the typical example of an unpredictable, random system.) Our deterministic model will have always an answer, but the reality will be different from the model’s prediction. At this time we may wish to try a probabilistic approach. Applying the principle of maximum entropy (ME), we can (very easily) obtain a simple result, that the probability for each face is 1/6, provided that nothing tells us that the die is not fair. By the way, the same result can be obtained by the principle of insufficient reason, but the ME principle is more powerful; for instance it can work also for an unfair die, giving an answer different from 1/6. The information given by this probabilistic approach may be seen as useless (though in fact is still is useful) if we are interested about the state at a specific time instance. But if we are interested in the general picture of the movement, without focusing on details, the information is absolutely sufficient. That is, ME gives us information for the forest and not for each individual tree. In this respect we cannot tell that entropy caused this specific state or part of the trajectory. ME just tells us that this state should have been expected and determines the odds with respect to all other states.
2. Now let us consider one mole of a gas, i.e. a system of N_A = 6.022 x 10^23 molecules. We can use the ME principle to infer several macroscopic quantities of the system such as pressure or temperature. Again the principle does not help us to know the state of a specific molecule. Usually, however, we do not care about each molecule and we are happy if we merely know the macroscopic quantities (the properties of the forest).
3. In the die example it is justified to assume that the properties of the die do not change in time, so the probabilities resulting by ME will be constant. In the gas example, which is more complicated, we may formulate some macroscopic preservation laws and enter them into the entropy maximization procedure as equality constraints of the optimization problem. Macroscopic mass, momentum and energy (i.e. sums over all molecules or, equivalently, means multiplied by N_A) are quantities that are preserved (if the system does not exchange heat and mass with the environment). That is, the means of these quantities are constant in time.
4. If we take a further step and consider the atmospheric state at a location (or even the global average) with respect to temperature or precipitation, we may observe that physics does not imply any preservation law for temperature (the total energy is preserved, not temperature) or for precipitation (the total water balance is preserved, not the rate of precipitation). Therefore, there is no reason that temperature and precipitation will have a constant mean through time. We can thus model these processes assuming variation of the mean. If this variation were deterministically predictable and we had a skillful model for prediction, then we would have built a nonstationary model for each of the processes. However, deterministic predictability may be a just a (bad) dream, so we may describe this variation again in a probabilistic manner. If we continue this type of thinking (means varying at a cascade of time scales, in an unpredictable manner), the eventual result is a stationary (yes, stationary) stochastic process with LTP.
5. Coming to part b of the question, certainly all components and properties of the climate system (including ocean heat storage), all feedbacks and all external forcings played their role. But I do not have any model to reproduce the climate evolution, so my my answer is “I do not know”. Even if the question were related to the simple die example (e.g. what caused face 5 to be the upmost phase at time 500 ms?) again I would have difficulties to answer. Was perhaps the cause related to the initial position, momentum or angular momentum? To the series of collisions with the table? To collisions with air molecules? To imperfect uniformity of the density of the die? To all together? The latter seems plausible, but does not offer any useful knowledge.
re 439 Cliff,
Don’t get me wrong. I’ve been a supporter of DrKs work, In fact I even got tamino to do a post on hurst and LTP.
The warmers want to rule out LTP and attribute all change to C02. there are clearly problems with that. But LTP
is not a magic wand. It does not make radiative physics wrong.
If we don’t truly know how the natural climatic processes work, how do we know if these processes are, or are not, being modeled with enough fidelity to get “lifelike” results?
If we rely primarily upon computer modeling to resolve the most important questions as to how the natural processes work — as opposed to direct observation — then are we not caught on an infinite merry-go-round of circular reasoning which leads us only to that set of conclusions which the computer modelers themselves determine?
IMHO, this issue of inherent determinism in the current approach to doing basic climate research — i.e. near complete reliance on computer modeling as opposed to physical observation — is as important as is the physics-related question as to whether the climate itself behaves in a deterministic fashion relative to the CO2 content of the atmosphere.
Is it not so that the most reliable “computational engines” that might be of some use to us in answering important scientific questions about climate change are the physical interactions of the natural processes themselves?
The fact that not nearly enough is known about these natural processes and natural interactions means that it doesn’t matter very much, really, if you yourself (or anyone else) have very little idea as to how to mathematically analyze the consequences of these interactions.
Acknowledging the breath and the fundamental implications of the following two questions, I ask them yet again:
(1) What kinds of direct physical observations need to be made; what kinds experiments need to be performed; and what kinds of data need to be collected directly from the physical climatic systems themselves to determine how they actually work?
(2) What is the delta between what we are doing now, and what would we should be doing in the future, to better characterize the actual physical climatic processes themselves, as these exist in nature?
Answering these two questions would be a time consuming and expensive proposition, and performing the observations and experiments themselves would, of course, be an extraordinarily expensive and time consuming proposition.
On the other hand, the results would be founded in observational facts and data, and would not be nearly as subject to the whims and biases of an agendized clique of climate modelers whose basic starting point is, and always will be, “Nothing else but C02 explains it.”
Re # 466 Willis Eschenbach
That was a neat explanation you gave –
Intuitively, a break would not be expected. However, people working with data often need to break it into bite-sized chunks, to fit it on a map, to allow for computing power, etc. Re the length of a coastline, an atlas will typically show bays down to a certain dimension, for convenience and line width. This does not mean that bays of this size have computational or definitional significance.
I suspect that the origin of the 30 years is rather like that. When you have only 150 years of thermometer data, you like to break it down to more than 5 pieces so you can play with the numbers, do calibration and confirmation series, etc.
Physically, the explanation by Dr K in 469 says much the same in more detail.
One reason must be that LTP makes prediction problems bloody complicated. Fig 1. of Mandelbrot68 mentioned earlier (#342) is a good example. Here’s another,
half-integrated white noise observed for 200 samples, and then best linear predictor applied for future 200 samples. Note that
1) CIs get very wide very rapidly.
2) Non-Markovian behavior means that covariance propagation takes lots of operations. Predicted value is a function of all past observations.
3) It would be tempting to ignore LTP, fit a trend to observations, and use that in prediction
steven mosher says:
But would it not make the convective physics ‘wrong’? (ill-parameterized)
Scott-in-WA, #471
Assuming the usual convention for climate as the 30-year average, we need to wait 30 years for a true additional data point. Furthermore, as shown in Table 1 of Koutsoyiannis and Montanari (2007), 150 years of climatic data (the CRU time series) are equivalent to about 2 data points in the classical statistical sense, if the LTP hypothesis is true. In another example, in Koutsoyiannis and Cohn (2008), slide 7, you may see that we have to wait 3 million times the age of the universe 😦 to form a sample equivalent to a classical statistical sample of 100 data values. So perhaps we should fight down anxiety about data. That is why in the excerpt quoted by Kenneth Fritsch in #403 we claim that the target to prove or disprove LTP cannot be achieved by merely statistical arguments.
Experiments cannot be done in natural climate – there is no repeatability. Unless you mean experiments with models. In this case, there are already a lot of ongoing experiments. I think that falsification of climate models (and the implied deterministic predictability of climate) advocates LTP.
Another way of gathering experimental data is to change field. Turbulence and electronics can provide arbitrary long data sets. As I described in another comment (#431) they seem to exhibit similar behaviour. And there must be some reason why.
For your second question, my opinion is summarized in the following excerpt from the last paragraph of Koutsoyiannis et al (2008):
“In our opinion, however, the unsatisfactory state of the art in climatic (and hydrological) future projections does not reflect a general deadlock in related sciences, but only a wrong direction. Causality in climate and hydrology is not sequential and one-to-one but rather circular (due to feedbacks) and many-to-many (due to complexity). Such causality can be better described in probabilistic and stochastic terms (see Suppes, 1970), rather than in terms of the current deterministic climatic models and practices (see also Giorgi, 2005). Probabilistic and stochastic approaches should not be confused with current multi-model ensemble climate projections (e.g. Tebaldi & Knutti, 2007). A stochastic framework for future climatic uncertainty has been studied recently by Koutsoyiannis et al. (2007) in a stationary setting. Arguments that the increasing concentration of greenhouse gases causes nonstationarity (Milly et al., 2008) should not discourage stochastic descriptions: after all, nonstationarity is clearly a stochastic concept and, hence, stochastics is the proper mathematical tool to deal with it. For instance, the synchronized palaeoclimatic data of atmospheric temperature and concentration of greenhouse gases (studied in a different context by Soon, 2007) can be utilized to establish a stochastic relationship between the two processes and test its significance. … Possibly, deterministic climate models could also assist in establishing such a relationship, which, if proven to be significant, could be incorporated in a nonstationary stochastic framework of climatic uncertainty.”
DrK, thank you so much for your replies. Is there a foundational textbook that explains how ME leads to LTP?
The stochastic modeling approach described by DrK sounds so compelling and fruitful. Is it fair to say that the folks who conducted the “attribution exrcise” (the phrase I use to describe how the various forcings were tuned to fit the GMT) completely ignored LTP? Was this simply an oversight? Do they not understand the fundamentals of how ME might lead to LTP? (There are a lot of smart physicists contributing to IPCC chapters. Surely they understand ME and the role it could play in LTP?)
Under an LTP paradigm trend attribution is futile. Is that why the trend attributors deny the existence of LTP – because it would eat into the variance that they want to attribute to GHGs?
And from an IPCC audit perspective –
Of the thousands of scientists who make up the consensus, how many understand this one issue (#478)? And what tiny fraction were sitting around the table when it was decided exactly how to do the attribution exercise – attributing as much as possible of the recorded trend to external forcings, and downplaying the importance of the error model? 4/2500? 10/2500?
(Is this a consensus or an autocracy?)
I have always wondered this question, but was not brave enough to ask it publically until the 2001-2008 flatline GMT could be declared significantly flatter than what IPCC projected.
Signing off. See you again at the end of hurricane season.
bender (#448):
Yes, far smarter than bender, better toned than an entire Aussie water polo team, timeteem is back. At the very moment bender may himself have gone (#480).
Bender, it seems you took my snipe in #441 to mean that I thought that you were not prepared to learn from DK (the slightly longer rendering always reminds me of a chap called Kissinger, an association I’d prefer to avoid). Let me say right away that that wasn’t what I meant and is clearly untrue, just from what you say in #477. You are learning from DK and it sure is a good thing to do right now, because the whole world should be. (Let’s just skip the boring intermediaries like RC and IPCC. More on that shortly.)
In this, and other things, we are united. Have a good break, if that’s the right term.
Re #480, timeteem
Hmmmm ? Any details ?
Ian Castles (#465):
Ian, may I take the liberty of addressing you in David’s stead. Even as a newcomer I was very disappointed by how I saw him treated on this thread, as I hope was clear. But I now regret one phrase I used in trying to wade into the situation in #402:
The undeserved obscurity, as I hope was clear from the context, I was comparing to the global acclaim accorded to Michael Mann et al for their (very undistiguished, as it turns out) paper on the hockey stick. I’m not sure David would have liked the tentative either. The point was that he, unlike some, seemed open to constructive criticism of his ideas. I did consider ‘humble’ but it sounded even more effete. Afterwards, though, I regretted the overall effect.
I hope David receives the kind of feedback he has been looking for in both areas and, while I’m on the line for the first time on Climate Audit, thank you to the whole Aussie skeptic team (that I’m aware of), including Bob Carter and, not least, your own work with David Henderson which, from what I can tell, usefully triggered the interest of Nigel Lawson here in London not just in climate change but its policy implications.
Dr K is so clear with his material that everytime I finish reading it I understand it. But his material is so difficult that everytime I start re-reading it, I’m lost again.
=======================================
kim, I know what you mean. I think the phrase ‘paradigm shift’ may have been invented for this situation.
Scott-in-WA, you say:
Easy. We don’t have to know how the climate works to see what the results are. When we look at the distributions (e.g. data, 1st difference, 2nd difference) of the observations of global temperature, and of modeled temperature, they are very different. See my graph cited above, where I compare those variables (data, 1st and 2nd differences) for the 9 hindcasting GISS ER runs and the HadCRUT3 data.
Since the modeled data is so unlike the data from real life, I say that the models are “not lifelike”.
QED.
w.
Kenneth Fritsch (#450):
Ken, I want to comment on this response to bender but before I do I’d like to clarify my approach to what’s off topic on Climate Audit, an issue that clearly concerns you – and I’m sure others. Obviously, a post that is off topic (OT) is simply anything that is not on topic (OT). Hmm, that sums up the problem pretty well. Here’s my rule of thumb.
A post is off topic (OfT) if Steve McIntyre deletes it. It is on topic (OnT) if he doesn’t. This has the interesting consequence that you can never know that your post is OnT, just as you can never know that your post is OfT. You can only know that your post was OfT. The key practical point is that nobody else’s opinion counts, apart from the host. That saves a lot of time.
The advanced student might want to consider the situation where Steve McIntyre says that a post is off topic but doesn’t delete it. But as I don’t know whether this has ever happened in the history of CA I’ll let others wrestle with the problem. DK and Cohn talk beguilingly about HK pragmatism (as a preferred alternative to LTP) and that was my take on OT pragmatism (also referred to pejoratively by some as “you can’t always get the toothpaste back in the tube”).
So, with the ground rules set, and no complaints if this or other posts are later removed, your point about policy makers strongly reminded me of what Thomas Sowell said four years ago about the striking success of his mentor Milton Friedman in affecting US (and other) government policy over many years, in a short appreciation a couple of years before the 92-year-old Nobel Prize-winning economist died:
You can watch the video (which I highly recommend for the good things it later has to say about teachers and students) here.
To deal with the most obvious red herring complaint about how OfT this all is, my point stands whether you think the ideas of Friedman and Sowell are terrific or appalling. But the key thing that has been pinging around my brain since I got just a taste of what DK is saying about LTP/HK in the last few days is that here are ideas that will totally resonate with the man in the street, if we do the hard work of getting them out there. And that will change everything – despite the glaring democratic deficit in some of the goings on in the UNEP and IPCC in the past.
No, I can’t prove it. But it gave me enormous hope, on the world-saving front. I hope it is ok to mention it.
Just went to get Dr. K’s presentation listed above, and I found the following:
You know the Hurst phenomena must be at work when the condensed version is larger than the original … you see, what has happened is a high H effectively reduces the number N of bytes in the regular presentation to below the number N of bytes in the condensed presentation …
w.
Re: 452
Willis, I am not sure what you mean when you say “remove the average monthly anomalies”. Do you mean use annual anomalies? If so when you say:
I could only add what a doctor once told me when I complained about my arm hurting when I put it behind my neck and he told me to quit putting it behind my neck.
re: #486 timeteem
This isn’t really correct. Steve often moved off topic material to unthreaded. And I’m sure I’ve seen him make remarks like “any further OT messages on this thread will be deleted.” This necessarily implies that he has left OT messages on threads. Then there are guest threads where, AFAIK he leaves it to the poster of the thread to decide what to do with messages posted to said thread. AFAIK said posters have not made it necessary for Steve to come in and clean up their messages.
Re: Timeteem @ #486
I think the worst Steve M would do with these posts, at least to the point before your post and my reply, would be to put them over to unthreaded – but I have guessed wrong in the past. I also think that Steve M’s blog would lose a lot if it went down path to “saving the world” to the detriment and sacrifice of puzzle solving and paper/methods reviews and analyses – and I think he knows that.
You mentioned a couple of my favorite economists, but in this case (climate issues) I think the main players are the climate scientists. My hope there would simply be not to blur the line between science and policy, backing-off on claims of consensus, using review processes that call for a show of expert’s hands and paying more attention to the uncertainties involved in their results and predictions. I think the criticisms that Steve M and others here level at climate scientists stem primarily from how these scientists fail to respond to my hopes.
Kenneth, you ask above:
The data are the raw monthly data, the actual monthly temperatures. The interesting statistical features disappear when the underlying seasonal pattern is removed by subtracting from each month the average value for that month.
I have previously spoken against this widespread use of anomalies with the monthly averages removed, for other reasons. However, this is the first time that I have noticed this particular difference in the distribution of the data.
In short, I can only agree with Geoff Sherrington when he says above:
All the best,
w.
Willis E, I am more confused than I thought I was. If you are using monthly data for statistical analyses, for temperature trends, for example, with a time series over several years, you would almost have to use monthly anomalies to compare apples to apples. Using yearly data one could use anomalies or raw data. You could use monthly raw data if you wanted to determine a long time trend for a given month.
Is the statistical weirdness the same as interesting statistical features to which you referred in the the two preceding posts? Does the weirdness occur when you use the raw monthly data or monthly anomalies?
When you say you “remove the average monthly anomalies” the only average monthly anomalies that make sense to me would those used to calculate an annual anomaly.
Willis (#452)
I, too, am puzzled by your finding:
If what you are saying is that the distribution functions are approximately Gaussian, that is (arguably) to be expected under a variety of models (including LTP, btw). If you are finding that they are also iid, then I am indeed surprised because I am pretty sure they’re not.
IIUC, if observations are multivariate normal (with possibly some additional hypotheses) — which is consistent with many proposed stationary stochastic processes (iid, AR(1), MA(1), ARMA(p,q), FARIMA(p,d,q), etc.) — then the first and second differences will also be multivariate normal (note that the reverse is not generally true). In such cases, the marginal distributions are Gaussian, as you note. This tells us nothing, however, about whether the stochastic process possesses LTP.
As I think about this more, I find myself more confused. Likely I have not understood your point. Can you be more explicit about which “statistical weirdness disappears”?
TAC and Kenneth, thanks for your questions.
If I take the raw data, without removing the monthly averages, it has an approximately sinusoidal distribution, as would be expected given that it contains the cycle of the seasons.
The first derivative of the raw data, however, is essentially random uniform. Not random Gaussian. Random uniform. And the second derivative looks like a truncated Pareto distribution. It is those distributions which I was calling “statistical weirdness”.
However, if I first remove the monthly average anomalies, those three distributions (of the data and the first and second differences) are all approximately Gaussian normal.
When I say “remove the monthly averages”, this means taking the averages for each month over the entire dataset (or some subset of the dataset). These monthly averages are then subtracted from the raw data, leaving the anomalies from the monthly averages.
HTH … let me know if this is still not clear.
w.
Dave and Ken (#489 & #490), thanks for improving my knowledge of the system. Not the climate system, whatever that may mean, since we learned just how arbitrary that 30 year timeframe is, but the Climate Audit system. The events “Move to unthreaded” and “Create guest thread” were not ones I knew existed. If I was using the JSD, the method for system design proposed by Michael Jackson – not that one, the UK one – I would now ask questions to try to tease out the properties of each event. But happily, I’m not. I’m trying to learn about climate science – and basking in the sunlight DK has opened up onto all of science, perhaps even social science. He really is to blame for some of the most OT stuff on this thread, that guy. The most valuable stuff. I just hope it’s true.
Sorry Willis : Not clear to me.
is ok, this gets you the anomaly. However, what means
Following your wording, removing the anomaly would get you the mean. However, the average anomaly is zero by definition. So, what should come out of that operation ?
And :
Uniform is rectangular, bounded between 0 and 1. That is what our standard software random number generators deliver : Nothing weird at all, rather well-behaved, but never negative and never gt 1! Do you really mean that ?
Willis (#494), Thank you for the clarification. I think I now understand.
You raise questions that we have mostly been neglecting during this discussion: What is the true shape (distributional family) of climate data, and to which data does the distribution apply?
In general, it is convenient to assume — as we have here — that model errors are Gaussian, where errors are defined as differences between observations and model (the distribution of unadjusted observations — e.g. data before variability associated with seasonality has been removed — need not satisfy a distributional assumption).
The entire debate about whether climate processes are iid, AR(1), FARIMA(p,d,q) (which, for 0 .lt. d .lt. 0.5 exhibits LTP), or whatever, can be — and usually is — carried out in the context of the multivariate normal (Gaussian) error distribution. The difference between iid and LTP, for example, is confined to the covariance matrices of the corresponding error distribution (the covariance matrix corresponding to iid data is simply an identify matrix multiplied by a scalar variance; for LTP, the off-diagonal elements are non-zero and non-vanishing).
In summary, you have raised a good practical question — one needs to worry about the distributional characteristics of the data — but I do not think it is central to DrK’s paper.
Dr. Koutsoyiannis, thank you for your kind response. As a lukewarmer, I very much concur with bender’s assessment of the importance of your work, for the reasons he has outlined.
I have these further questions to ask:
(1) Would it be an accurate summary of your position to say that sufficient observational climate information — and I’m referring here to data collected in the field from the actual climatic processes themselves — already exists in sufficient quantity and quality which could allow for reasonably useful predictions to be made of future climate behavior?
(2) If the answer is yes, i.e. we already have what we need in terms of raw observational data, is it an accurate summary of your position to say that achieving these useful predictions of future climate behavior is simply a matter of applying an appropriate and scientifically defensible series of analytical techniques?
#c473
Better to use real data instead of simulated, so I took HadCRUT Monthly
http://hadobs.metoffice.com/hadcrut3/diagnostics/global/nh+sh/
and used that to predict monthly average (*) for next the 10 years:
in text format here:
http://signals.auditblogs.com/files/2008/08/gmt_pred.txt
Of course CO2 effect kicks this prediction to the recycle bin quite soon, as temperatures keep rising. Yet, I’d like to see alternative prediction with CO2 included (including prediction interval! ).
Test:
(*) using that simple half-integrated-white-noise model
Thanks, Scott (#498). It is difficult to summarize my position but I can make a few comments on your summary, based of my experience as an engineering hydrologist:
Data: (a) Real world data are unique and indispensable (we cannot make repeatable experiments in nature as in laboratories). (b) Data are never enough. (c ) New data need a long time, so we have to rely on existing data. (d) Lack of data is never a reason to cancel an action (e.g. a research programme, an engineering design or a management measure — we have to give answers based on the available information each time). (e) Each time we have new data we must adapt our programme, design or management.
Predictions: (a) If the time horizon is long, only probabilistic predictions are possible/meaningful. (b) Probabilistic predictions need probabilistic/stochastic models from the outset and rely greatly on data. (c ) Models have to be tested and validated with a subset of the data that was not used in model building and calibrating. (d) In decision making, adopting models that have not been validated or even hide or underestimate uncertainty in their predictions, results in increased risks.
If you agree with these clarifications, I can agree with your formulations.
Willis, have you done any of the following:
Used yearly anomalies or raw data and looked at the distribution.
Used monthy anomalies or raw data as one would in determining an individual month’s anomaly.
Compared for example what you would obtain in doing these calculations for the globe and a more regional area such as the US.
If you have done any of the above, I would be interested in your results. If not it is something I would want to do out of curiousity.
By the way, I do not see why one would want to limit ones calculations in analyzing temperature trends. I would think we should be looking at distributuions and trends using monthly, individual months, seasonal months combinations, annual, maximum and minimum temperatures and applied to zonal areas of the globe and any other regional area of interest.
I live in a state in the US (Illinois) where as on goes from north to south one can see large warming (generally north) to little or no warming and even cooling (generally south) over the past 80 to 100 years. There are also areas where the warming has been mainly in the winter and at the minimum temperatures. That we tend to see much more discussion about global warming is I think because of the limitations of the climate models when they go to more regional and seasonal predictions and refinements of max versus min temperature trends.
/delurk
bender’s blather condensed into one phrase:
DrK’s logic and insight stuns me.
/lurk
Dear Dr Koutsoyiannis
I’m a big fan, though a much more recent one than bender. I’m a software guy primarily. (It was good to see Object Pascal at the end of your CV, which I first used when Apple was calling it Clascal. We should talk about that one day!) For now, forgive the basic level of, or the misunderstandings betrayed by, any of the following questions, which are in no particular order and which I will chop up into different posts.
#475:
I’m sorry that the last sentence didn’t quite make sense to me and it seems an important one. I know that you deny the deterministic predictability of climate and that you consider LTP a better option. (A better option for analysis or a more truthful statement of reality? That’s probably a bit philosophical. Anyway.) Are you saying that the climate models have been falsified? By your paper? Even at the 30 year level? And that this implies LTP? It may just be the word advocates that is causing me a problem, which is normally only used in English with a human subject. Thus you can and do advocate LTP but a falsification can’t. Sorry to be a pedant in my own language (my Greek is very bad!) but I may have missed something here.
More for Dr Koutsoyiannis
UK_Spence quoting Cohn and Lins 2005 #150:
I see from p19 of your EGU presentation with Cohn that FARIMA is just one of the synonyms for LTP, which you would prefer to be called HK pragmaticity – for what seem to me good reasons. But the term does remind me of a system I helped program for forecasting financial time series in the mid 90s. The assumption was that relationships between the multiple series could only be linear but the number of lags used was potentially unlimited, with the Akaike Information Criterion (AIC) crucially used to make sure that the past was not in fact overfitted in building the model. I remember terms like ARMA, ARIMA and even ARMAX (is that right?) These don’t mean that much to me after a long gap but the system worked well and this leads me to ask
1. Is the AIC relevant to climate science at all?
2. Where’s the best place for a beginner with a fairly strong maths background to learn about Fractional ARIMA and how it differs from these others? Is it back to Mandelbrot or is there by now better teaching material?
Dr K, #431 was all stupendous, thank you
I take it then that the answer to bender’s question about a book on how ME leads to LTP is “No, read this paper, it’s all we have”?
Dr K, #431
I’m in deep water here but would anything change above if Roger Penrose’s ideas about an “Objective Reduction” of the quantum wave function, based on gravitational energy differences between superimposed states, turn out to be even roughly right? An approach which is still probabilistic, as I understand it, so I guess not? And his proposal that the Second Law derives from an extremely special starting place in phase space at the Big Bang with incredibly low entropy? Again I guess not but it was fun to try to ask the question!
Re: #506,
I think Brian Greene, among others, would disagree. According to him, almost perfectly uniformly distributed matter, as in right after inflation, has lower entropy than matter condensed into stars, galaxies, superclusters, etc. Rather far OT.
Dear Dr K, lastly, for now, earlier in the thread I called you irenic, one of my favourite words in English but one which is not widely used – or practised! I assume that eirene (peace) in Greek is more common. But I was also alluding to the last Greek-speaking early church father:
I’m not sure I’ve practised this so well myself in the last week but I hope it is always true of you.
I started with the stock market thing, but it was an analogy about predicting the future based upon past information, not a direct comparison between climate science and financials.
Think of it this way maybe. If in roulette red has come up 100 times in a row, the next spin still has an 18/38 chance of coming up red again. But what are the odds red will come up 101 times in a row?
Perhaps it doesn’t matter; the house still will make 5.26% over time.
It’s all about how you think of it.
358 bender:
The 26 in between don’t matter if they have bounced between 1 and 1000 during the time and now it’s worth 25.
The question then becomes; if you own a stock that’s not doing well, do you wait until it gets back to what you paid for it to sell, or do you just take the hit and put the money into something that’s doing well now?
timeteem (#503-508):
Thank you for the profound and insightful comments. I am sure that they will be discussed a lot in this thread. I have some initial thoughts but I must wait for a few days before writing anything – because I have to finalize and deliver some urgent works shortly. This time I will only reply to your simpler questions.
My sentence was:
The only ‘I’ in this sentence is in ‘I think’. A single paper (originating from research without resources – unfunded) cannot defeat a body of mainstream and dominant research (funded by several billions of euro). It is just one step. We have delineated in the paper some other steps. We have also cited other related works (Frank, 2008; Douglass et al., 2008).
I understand that ‘advocates’ was a bad word choice. I was drifted by the Greek use of the corresponding verb. Neither ‘implies’ is what I wanted to say (it would be too categorical). If I said ‘is in favour of LTP’ or ‘supports LTP’ would it make sense? And don’t say ‘sorry’; I am very pleased that you corrected me.
Indeed, I have not seen any book about these issues. I have written a few papers and given some talks on this; see http://www.itia.ntua.gr/en/documents/?authors=koutsoyiannis&tags=entropy. I believe that this topic is very promising for new research.
Dr. Koutsoyiannis, yes, your clarifications are quite as informative as I hoped they would be.
I also believe I can speak for many and say that your audience here at CA eagerly awaits your next paper concerning this topic.
Sam,
Re: 510.
AGREED. Thanks.
Ron.
Except that in the case of GMT the 26 data points have NOT bounced in between, so the analogy is not just inappropriate, the premise is false. Please, stop wrecking a good thread with OT nonsense. At least until Steve M is back at the helm. It is the FACT that GMT has risen and has inexplicably stopped rising that makes DrK’s work so relevant.
#514 — GMT was inexplicably rising, too. 🙂 I think this uniform inexplicability is part of the relevance of Koutsoyiannis, et al., 2008.
#515 What I meant by my choice of words was that the rise was predicted by the consensus (whether you think that prediction is credible is another story), whereas the stalling was not. 😦
But your point stands: DrK, work is relavant to all trends, regardless whether coincident with or divergent from a given prediction.
GENERALISED ENTROPY AND ITS MAXIMISATION
=====================================================
I have not been familiar with this approach so I read all available DrK papers mentionning “Entropy Maximisation Principle .” which is supposed to give the theoretical basis to derive non Gaussian distributions in time series .
However as I am familiar with thermodynamics , I did a couple of verifications which result in following comments :
– the generalised entropy (Sq = (1 – Sum (Pi^q)) / (q – 1) ) where Pi is the probability of the state i and q an arbitrary parameter doesn’t apply to thermodynamics .
While , obviously , lim Sq when q-> 1 is the Gibbs entropy , for q non 1 it is not possible to derive the black body radiation laws (doubtlessly other laws neither but I looked only at the black body law). Sq seems therefore either trivial (q = 1) or non physical (q non 1)
– it is said that under usual constraints (Sum Pi = 1 , Pi positive , energy conservation) the maximisation of the functional Sq gives the probability distribution function .
This is not right !
The maximisation is not done under the constraint Em = Sum (Pi.Ei) which gives the average energy BUT under the constraint GEm = (Sum (Pi^q).Ei)/Sum (Pi^q)) .
Here GEm is a “generalised” energy that is not conserved and it is necessary to impose the constraint on the wrong GEm instead of the right Em because else one doesn’t get the desired solution .
In a similar way it is necessary to define a “generalised” temperature , a “generalised” pressure etc . None of these “generalised” parameters is physical .
– it is very troubling that q is arbitrary . Actually q reappears in the probability distribution function once the maximisation of the functionnal Sq has been done and then is … fitted . From that follows that there are as many q as natural phenomenons observed . One could also propose a generalisation of the already generalised Sq of which Sq would be a particular case of which Gibbs entropy is a particular case (q=1) .
I found in no DrK paper a derivation and a physical interpretation of q .
– the maximisation of the functional Sq yields a very powerful fitting function (power law) that is particularly suitable for strongly (auto)correlated variables where the departure of normal law is also strong . However it must be noticed that this result is obtained ONLY when the constraints are carefully chosen – f.ex the “generalised” energy .
If the constraint was on a “generalised” mean of a variable more complicated than only x or x² what is not forbiden à priori and what is f.ex the case in the Kolmogorov turbulence theory , the maximisation of Sq would NOT yield a power law .
In a sense depending on the constraint , the maximisation process is able to yield any desirable probability distribution out of which the power law is only a particular case .
So I have a question for DrK .
I fully agree that autocorrelated time series don’t follow the normal law .
I also agree that power laws and more specifically the Hurst process are much more relevant to describe such strongly autocorrelated series .
I equally agree that “fat tails” due to the scaling issue prove that we can’t use normal statistics .
Do you really believe that you NEED the “generalised” entropy which seems to me more than dubious in order to make your point ?
Wouldn’t it be more correct to say that what you observe is a power law and that it happens that among the infinity of methods to generate a power law , the functionnal Sq can ALSO do the job if and only if particular constraints are applied ?
500 quatloos on the entropic one.
Re: bender #518
My favourite of your comments so far. I have an almost irresistible desire to raise you 500 quatloos – but as a newcomer I’m not sure of the rules, the game or the entry criteria. In any case, agreed, the entropic one sounds good.
Re: Pat #515
Uniform inexplicability. As Oscar Wilde would say, ‘I wish I’d said that.’ (His companion: ‘You will Oscar. You will.’)
Re: Dr Koutsoyiannis #511
It’s the elephant and the flea. I get that. Worth saying I found the Frank immensely helpful earlier in the year. Enough fleas of the right persistence and peskiness and the elephant will start to flap.
There’s another elephant/flea situation here – the DK achievement/my attention to just one sentence. But it still seems important so here goes. The best phrase that comes to mind is ‘lends support to LTP’. I’m still not completely clear about the earlier part of the sentence though. Let me now have a go at the whole thing:
This is what I believe. I think! It may or may not help you next time around. The ‘thus’, ‘already’ and ‘strong’ are worth attention.
Tom Vonk looks like he’s asked you some searching questions about it. Good luck!
Re: DeWitt Payne #509. Point taken (and perhaps ever so slightly missed). Let’s leave the OT-ness until Dr K gets around to it and/or Steve M returns (and I’ve only just learned he’s not ‘at the helm’, from #514).
I don’t know, bender; 1985 is -.405 and 1998 .619 (1979 -.07 and 2008 +.147) Seems rather bouncy. Perhaps you don’t consider it such. Eh.
Is your objection that answering “Is the lower troposphere satellite anomaly for July months since 1979 at start and end statistically significant at the 95% level” is meaningless because the question is the wrong one and the answer telling us nothing?
I’m interested in what a trend rise of about .5 over all months for the period tells us in a range of about 1. Does it “matter”?
Tom Vonk, #517 (advocated by timeteem, #521 – correct?):
1. I do not think that a power law (or scaling) is kind of a fundamental physical principle per se. So it must be produced from other principles. In my paper:
Koutsoyiannis, D., Uncertainty, entropy, scaling and hydrological stochastics, 1, Marginal distributional properties of hydrological processes and state scaling, Hydrological Sciences Journal, 50 (3), 381–404, 2005,
I indeed used the generalized entropy to describe the marginal distribution of hydrological variables, after having failed with standard entropy, particularly on the distribution tail. Note however that: (a) I did not use the q-moment constraints that you describe. Rather, I used standard moments (this is clear on p. 389, where the derivation depends on equations (10) and (11), i.e. the standard mean and variance, whose physical meaning you don’t put into question). (b) The derived distribution is a power law only asymptotically (on the tail) and this agrees with observations. If power laws were fundamental principles, wouldn’t they apply to the entire range? (c ) I used only continuous state variables, in which the entropy depends on the metric used (e.g. if we use a logarithmic transformation of the rainfall depth the entropy takes a different value, which does not happen with discrete state variables). Thus I could produce the same result with standard entropy using appropriate transformation of the rainfall depth, for instance. But it would seem more arbitrary/tricky than using the established notion of generalized entropy.
2. I said “established notion of generalized entropy” because renowned physicists including Tsallis and Gell-Mann are working on it. You are right to say “I found in no DrK paper a derivation and a physical interpretation of q” but perhaps it is better to address to them your criticism – certainly I am not the right person because I was only a user of Tsallis generalized entropy.
3. The scaling in state, or in the marginal distribution, which is examined in the above mentioned paper is something different from the scaling in time, or the Hurst-Kolmogorov behaviour. It is commonly assumed/thought that they are the same thing, but my opinion is different. A fat tail in the autocorrelation function is something different from a fat tail in the marginal distribution (i.e. in assuming one variable instead of the process evolving in time). For the scaling in time I have written the companion paper:
Koutsoyiannis, D., Uncertainty, entropy, scaling and hydrological stochastics, 2, Time dependence of hydrological processes and time scaling, Hydrological Sciences Journal, 50 (3), 405–426, 2005.
You may have overlooked that in the latter paper, which is the one relevant to the discussion here, I do not use at all generalized entropies. I use only the standard (Boltzmann-Gibbs-Shannon) definition of entropy, which seems sufficient to produce the HK behaviour (I have tried generalized entropies as well and the results are very similar in terms of scaling in time).
4. Currently, despite initial failure mentioned in 1, a colleague and I are trying to produce even the scaling in state using only standard entropy. We hope to report something on this in due course.
5. As I said in another comment, this research is new for hydrology (and climatology) and a lot of things have to be investigated. I believe that such research will be fruitful.
Re: Dr K #524
Not quite. ‘as pointed to by timeteem’ in this case, I think.
I advocate a ‘wait and see’ approach to global warming rather than cap and trade or carbon taxes. I advocate careful study of Dr K’s paper on the credibility of climate predictions for anyone with a scientific or maths background. I advocate eating lots of vegetables and regular exercise to stay healthy. Etc
I’m sure Tom knows a lot more than I do about entropy but I guess I’m not advocating very much in this area, just enjoying the interaction!
Dr. K, many thanks as always for your generous sharing of your time and knowledge.
As I understand it, the “entropy maximization” methods are subsets of the direction indicated by Bejan and the Constructal Law. Bejan has shown that a basic structure of the climate (Hadley circulation) can be both predicted and quantified by the use of the maximization principle of the Constructal Law (cite).
If you are familiar with Dr. Bejan’s work, could you comment on the intersection of the Constructal Law with what you see as the principle of “entropy maximization”?
Finally, a Pareto (power law) distribution is a known (and incredibly common) result of self-organized criticality. I see self-organized criticality every day, because I live in the tropics. The formation of cumulus and cumulonimbus clouds every afternoon obeys a power law, a few big ones and a lot of small ones.
However, you say this emergence of the power law phenomena is not a “fundamental principle per se” … could you perhaps expand on this a bit?
Many thanks,
w.
I certainly hope so and wish you well. Wading through all the literature is taking me forever, but so far the ensemble GC models do tend to be biased on the high side. Mainly by underestimating tropical convective variations, IMHO. I don’t know if this is one of your interests, but since I am watching a lot of tropical convection going on I thought I would mention it.
Now that there’s a hiatus in this fascinating discussion, I’d like to say a word of thanks to timeteem for post #482, and to draw attention to David Stockwell’s latest post at http://landshape.org/enm/comparison-of-models-and-observations-in-csiro-decr/#more-680 , in which he says that:
‘I have been in contact with Kevin Hennessy a number of times about the report, but unfortunately cannot report much progress. He maintains that the authors were satisfied with the validation of the models in the report, but has not provided details of the validation procedures or results that they used. Unfortunately the validation of the models was not reported in [the original report] either … I am very curious to see the methods of validation they used and the actual results they obtained. I would also like to know why the results of the model validation were not reported.’
I have commented that I do not believe that Kevin Hennessy of CSIRO should be deciding whether or not this important information is made available. As Steve McIntyre and readers at this blog undoubtedly helped bring about the release of the data used in the drought report to the Australian government (which was initially withheld due to ‘Intellectual Property’ reasons) I am hoping that CA can again play a part in overcoming the secretiveness of CSIRO (and maybe also of BoM).
I guess that discussion of this at CA should be on the ‘Stockwell on CSIRO Drought Report’ thread at http://www.climateaudit.org/?p=3392#comments
Dr K # 524
Yes I noticed this .
As long as you constrain only x or x² (what you do) , you get a power law distribution .
My point was the physicality of the “generalised” entropy (what was not your issue as you dealt only with mathematical properties of Phi) where an attempt at physical description of thermodynamical systems must be made .
In this case the physical energy mean (SigmaPi.Ei) is not constrained but rather a kind of momentum or “generalised” energy (Sigma Pi^q.Ei) .
On a tangent allow me to compliment for your brilliant paper “Nonstationarity versus scaling in Hydrology , 2005” .
This one is exactly in the heart of the matter in the following qote :
“The only merit of this (nonstationnary) modelling approach is that , by detrending the original series , we obtain a time series that can be regarded as a random sample (because it is free of trends) so that we can use classical statistics to process it further . The scaling modelling approach … instead of trying to adapt the series so as to obey the classical statistics , it adapts classical statistics so as to be consistent with the observed behaviour . And it shows that trends increase dramatically the uncertainty rather than decrease it “
I have written a post in the beginning of this thread about the same problem but focused on the “diergasia” aspect while your paper focuses on the “anhelixis” aspect .
Indeed writing a variable u(x,t) like a sum of µ(T) + u'(x,t) where µ(T) is the time average of u(x,t) over a period T and u'(x,t) is a fluctuation or “residual” is a perfectly legitimate change of variable in a deterministic equation defining the dynamics of a system (here N-S) .
Yet at the same time it shows immediately the scaling problem too .
First – µ is not constant but varies with a step T . The whole dynamic process is quantified by a time quanta T . There is no physical constraint on T which can be chosen arbitrarily (1 month , 30 years , 100 years) . however once the time origin chosen , µ will be constant for every time interval [nT , (n+1)T]
Second – this change of variable will be fruitful if u'(x,t) doesn’t depend on T and specifically if it obeys some statistical law (f.ex has a normal distribution) .
Third – yet observation of time series shows that u’ depends on T so its form is u'(x,t,T) . And here you have the scale dependence in the “diergasia” world – by increasing the temporal window you take on board more and more low frequency phenomena that influence more and more u'(x,t) . On top even if the choice of the size of the window (T) allows to describe the system INSIDE the [nT , (n+1)T] window , it doesn’t allow to conclude something about the [(n+1)T , (n+2)T] window because the sum of the windows is 2T wide and will be perturbated by low frequency events that could not be seen/were neglected in 1T windows .
That is what I did and spent my evening reading papers about the “generalised entropy” 🙂
F.ex
Click to access 0106496v1.pdf
Click to access 0310117v1.pdf
http://www.iop.org/EJ/article/1742-5468/2007/08/N08001/jstat7_08_n08001.pdf?request-id=f1c2729b-6a6c-4433-bfbb-f5d1b93f5e02
Those results are pretty convincing to show that the “generalised entropy” is unphysical .
What stays is that this functionnal (I prefer that expression to “entropy” which would be misleading by implying that this functionnal is physical) is able under certain conditions to generate by a maximisation process a powerfull fitting function (power law) that is relevant in many cases (but not all !) .
Besides a whole class of functionnals could be constructed that share the same mathematical properties but have nothing to do with entropy either .
That’s why I do not think that this particular way (the use of the “generalised entropy”) is promising or even correct to found the stochastical theory of scaling or Hurstlike dynamics .
I do not want to take away from the discussion of HK and LTP and the proposed statistical methods, but I do think that the Willis E post #452 referencing the distributions of monthly temperature data, monthly temperature anomalies (first difference) and second differences of monthly temperature data needs a better reply than what I first offered. I have heard lately is a lot about the lack of temperature series fit to normal distributions and the presence of autocorrelation in the residuals of temperature anomalies and this post and some simple-minded analyses raise some questions in my mind. I would appreciate some comments on the analysis described below and I am hoping that they will be a little more detailed than you “doddering old fool should leave statistical questions to statisticians” – even though it may be true.
First the monthly data (raw) distribution has been covered by Willis E in noting the seasonal cycles it shows. The monthly raw data hold little interest, in view my view, in looking for possible trends when used in long term series. Raw annual and individual raw data would, of course, give essentially the same information as the anomalies.
That temperature anomalies that contain a trend do not fit a normal distribution well should, in my view, not be surprising since the random scatter is around the trend line. That is what makes the regression residuals the important element in determining the autocorrelations and goodness of fit to normal distribution. Another element I have noted in these long term temperature series that, I would judge, will affect the fit to a normal distribution is that these series show regime changes that change the trends lines over several sub periods within the time series.
In an attempt to get a better feel for what I actually see in temperature trends, I selected the GISS Northern Hemisphere mean temperature series for 1880-2007 and that part of it from 1979-2007. I calculated the trends and the R^2 for the series and then looked at the goodness of fit of the data using a chi square test. The data used monthly (all months), annual and the individual months January and June. I then used the residuals and calculated the correlation, r, for AR1 autocorrelation and the goodness of fit of the residuals to a normal distribution. All the series had very low p values that rejected the null hypothesis that the trends were 0. The goodness of fit p values is assumed to require a value less than 0.05 to reject the hypothesis that the fit is not normal. The higher the p value, the more one can assume a better fit to a normal distribution. Some of the calculations for the 1979-2007 time period had only 29 data points for testing the fit to a normal distribution and the issue of how the data were binned becomes an issue.
GISS NH Temperature Anomalies 1880-2007:
Monthly (all months): Trend = 0.80 C/Century; R^2 = 0.48; p (fit to normal) = 0.00
Annual: Trend = 0.80 C/Century; R^2 = 0.66; p (fit to normal) = 0.04
January: Trend = 1.12 C/Century; R^2 = 0.51; p (fit to normal) = 0.45
June: Trend = 0.68 C/Century; R^2 = 0.59; p (fit to normal) = 0.19
Residuals of GISS NH Temperature Anomalies 1880-2007:
Monthly (all months): r (AR1) = 0.62; p (fit to normal) = 0.10
Annual: r (AR1) = 0.64; p (fit to normal) = 0.41
January: r (AR1) = 0.22; p (fit to normal) = 0.46
June: r (AR1) = 0.41; p (fit to normal) = 0.61
GISS NH Temperature Anomalies 1979-2007:
Monthly (all months): Trend = 3.01 C/Century; R^2 = 0.51; p (fit to normal) = 0.18
Annual: Trend = 3.01 C/Century; R^2 = 0.73; p (fit to normal) = 0.77
January: Trend = 3.15 C/Century; R^2 = 0.49; p (fit to normal) = 0.99
June: Trend = 2.48 C/Century; R^2 = 0.62; p (fit to normal) = 0.54
Residuals of GISS NH Temperature Anomalies 1979-2007:
Monthly (all months): r (AR1) = 0.53; p (fit to normal) = 0.34
Annual: r (AR1) = 0.00; p (fit to normal) = 0.87
January: r (AR1) = 0.39; p (fit to normal) = 0.92
June: r (AR1) = 0.10; p (fit to normal) = 0.94
Looking at these results, that are admittedly anecdotal at this point, I see generally better fits to a normal distribution and lower autocorrelation (AR1) in the residuals as one goes from monthly to individual months to annual data series and as one goes to sub periods of a long term temperature anomaly series. I also recall that the RSS and UAH temperature annual temperature anomaly series residuals had little or no autocorrelation (AR1) in the time period 1979-2007.
I known that there have been recent attempts to divide the long term temperature series at statistically derived breakpoints which results in some regime changes that to this point have not been assigned potential causes. I guess my question here would be: Does the climate work with periodic regime changes and within these changes would we expect the data, at least annual anomalies, to better fit a normal distribution and with less autocorrelation in the residuals?
Ken, that you can fit a linear trend model with ni.i.d. AR(1) noise to a series does not mean that the “trend”, or some part of it, is not attributable to an LTP process. In short time series (and 100 years is short relative to the time constant of ocean mixing), this view merits consideration.
[By the way, it would be terrific if you could plot the data with the trend lines on them.]
Re: #531
Bender, I agree with your comment.
I can plot the trend lines for anomalies and Lag 1 residuals as I have them in that form already. I need to combine all the monthly, annual January, and June trends into one graph for both time periods and for anomalies and residuals. By the way, there are striking differences in the appearance of the plots of the residuals of the regressions (not what you requested here) that make it rather easy to predict which will show better fits to a normal distribution and have less AR1 autocorrelation.
Re: 516 “What I meant by my choice of words was that the rise was predicted by the consensus (whether you think that prediction is credible is another story), whereas the stalling was not.”
I don’t want to quibble about semantics or seem argumentative, but just to observe that if a prediction is not credible, it’s not a prediction. It’s something else. Modelers have been very remiss in publishing physically valid CIs about their projections. It seems likely they don’t at all know the magnitude of the physical CI of their models. If that’s true, then their predictions are not falsifiable by observations. That makes model outputs more like guesstimates. Even in Demetris’ recent work, showing GCM mean projections do not match observations, can not really falsify GCMs if the true-but-unknown physical CI about the GCM temperature projection (for example) was about, say, (+/-)5 C. With a CI like that over 20 years, GCM outputs would be consistent with any trend in temperature.
This sort of result would just indicate that more basic physics needs to be done on climate itself so as to eventually bring sufficient theoretical precision into GCMs, that they might make a testable prediction. I.e., climate models as prediction machines are a premature birth of (a beautiful) climate physics. More gestation is needed to make the child viable.
Not unlike Gavin claiming the current stall, or even decline, is “not inconsistent with the models.” Any result is not inconsistent when there are floor to ceiling CIs. Sharpshooting…
Mark
534 Mark
Hardly sharpshooting! Miss-the-barn-shooting, I think.
This blog gets better by the day, we have a powerful exposition by first rate scientists, interesting distractions, brilliant thought provoking discussion. My further education was pure math, this thread bends my head, but whereas we used to talk about “there be dragons”, here, we see light being shone on the daemons hiding in the shadows. If only RC would adopt the CA posting policy we’d have proper “blog” i.e realtime discussion instead of stupifying paper publication timescales. It would be nice if one of the fiveish odd who can would split this thread in Steve’s self imposed excile in the hinterland however.
Here is a follow up to Posts #530, 531 and 532.
Below I have linked to the images of the plots for anomaly trend, residual plots and residual autocorrelation (AR1) for the monthly, annual, January and June GISS NH temperature series for the time periods 1880-2007 and 1979-2007. That gives 6 graphs for each month, annual, etc.
This links to monthly: http://img149.imageshack.us/img149/7098/anomresidualsmonthlydc3.gif
This links to annual:

This links to January:

This links to June:

I am presenting the data with links as I have heard comments that displaying the graphs directly into a longer thread will slow it down.
Tom Vonk, #529:
OK, but as I said in #524, I did not use generalized entropies at all to derive the Hurst-like dynamics. I used only the standard (Boltzmann-Gibbs-Shannon) definition of entropy. Therefore the interesting references you link are irrelevant to this discussion. In any case, your references demonstrate that there is an ongoing dialogue about the generalized entropy. In my opinion, a dialogue with different scientific opinions should not worry us; rather it is very healthy and a necessary condition for scientific progress.
Thank you very much for drawing attention to my paper “Nonstationarity versus scaling in Hydrology, 2005” and for your kind comment about it.
Willis Eschenbach, #526
Willis, I do not know much about the maximization principle of the Constructal Law but I am somewhat reluctant to use notions such as this one or the self organized criticality or the scaling as a postulation, before we explore if these could be derived by other well established physical and mathematical principles. Certainly nature optimizes (extremizes) some quantities and optimization laws are much more powerful than preservation laws. Well established optimization principles are in my opinion Fermat’s principle of least (in fact extremal) time for the light propagation, the principle of least (extremal) action for the motion in classical and in quantum physics and the principle of maximum (extremal) entropy for the macroscopic states of complex systems.
Dr. K, thank you for your thought provoking and interesting post.
I can only recommend Bejan’s work regarding the Constructal Law, as it has a number of applications in hydrology. Some of them are listed here, including Bejan’s textbook, “Convection in Porous Media”.
All the best,
w.
Re: Geoff #462. It did seem boastfully large, even for an Australian. The question being: how closely was it read?
I’m splitting this thread. Please comment at the new thread.
One Trackback
[…] are currently active discussions of the Koutsoyiannis paper on both ClimateAudit, the skeptic site, and RealClimate, the consensus site. I recommend that you read the full […]